“不要将聊天机器人用作搜索引擎”多年来一直是很好的建议……直到它不再适用。
早在 4 月份,我就写过关于 OpenAI 的 o3 在使用其 Bing 支持的搜索工具时表现如何的文章。GPT-5 感觉甚至更好。
我把它称为“我的研究小妖精” 。我可以给它分配任务,无论多么琐碎或复杂,它都会帮我们做很多工作,比如搜索互联网并找到答案。
这对于满足好奇心非常有用,有时对于更重要的努力也有用。
我总是通过从模型选择器中选择“GPT-5 思维”模型来运行我的搜索——根据我的经验,这会带来更全面(尽管速度慢得多)的结果。
以下是过去几天里的一些示例。每个示例都是在我手机上运行的,通常是在我做其他事情的时候。大多数示例都是用 iPhone 语音键盘听写的,我觉得这比打字更快。另外,和我的研究小精灵聊天也很有趣。
- 弹性人行道
- 识别此建筑物
- 星巴克英国蛋糕棒
- 《大英百科全书》助力维基百科
- 剑桥大学的正式名称
- 埃克塞特码头洞穴的历史
- Aldi 与 Lidl
- 人工智能实验室扫描书籍以获取训练数据
- GPT-5 在搜索方面表现不错
- 在 ChatGPT 中使用搜索的技巧
弹性人行道
希思罗机场以前有橡胶弹性自动扶梯,非常有趣,现在都已替换为金属自动扶梯,如果是这样,那是什么时候发生的?
当我穿过希思罗机场时,我一直在思考那些有趣的弹性橡胶人行道到底发生了什么。
以下是我得到的信息。Research Goblin 将时间范围缩小到 2014 年至 2018 年之间的某个时间,但更重要的是,它为我找到了 Peter Hartlaub 在《旧金山纪事报》上发表的这篇2024 年的精彩文章,其中介绍了旧金山国际机场 (SFO) 弹性走道的历史,可惜现在也已退役。
识别此建筑物
在阅读中识别这座建筑

这是我在火车上透过车窗拍的照片。它思考了1分4秒,并正确识别出它是“刀锋” 。
星巴克英国蛋糕棒
英国星巴克不卖蛋糕棒!深入调查一下
埃克塞特火车站的星巴克没有蛋糕棒,我问的那位女士也不知道那是什么。
结果如下。事实证明,星巴克确实于 2023 年 9 月在英国推出了蛋糕棒棒糖,但并非所有门店都有售,尤其是像埃克塞特圣戴维斯车站这样的授权旅行地点。
我特别喜欢它如何通过查阅 starbucks.co.uk 上的营养和过敏原指南 PDF 来建立确凿的证据,其中确实列出了生日蛋糕棒棒糖(我的最爱)和曲奇和奶油棒棒糖(显然在美国已经停产,至少根据 r/starbucks )。
《大英百科全书》助力维基百科
Hacker News 上有人说:
> 我之前在看另一个帖子,说维基百科是互联网上最好的。但他们只是抄袭了《大英百科全书》和其他所有东西,才抢占了先机。
找出他们这么说的意思
结果……事实证明,维基百科确实从已过版权保护的1911年版《大英百科全书》中植入了内容……但该项目是在2006年进行的,即维基百科于2001年首次推出的五年后。
我问:
哪篇文章能解释 1911 年大英百科全书事件,最好能给我提供链接
它指引我去维基百科:维基百科项目大英百科全书,其中包含详细的解释,以及指向仍使用该项目模板标记的13,000个页面的链接。我把我找到的内容发布在了一条评论中。
值得注意的是(至少对我来说),我觉得没有必要透露我使用 ChatGPT 来查找该信息——此时这感觉有点像透露我进行了 Google 搜索。
剑桥大学的正式名称
剑桥大学的正式法定名称是什么?
这是那句话的上下文。它思考了19秒——思考痕迹表明它知道答案,但想确认一下。它回答道:
“剑桥大学校长、院长和学者。” 剑桥大学,剑桥大学出版社及评估部
第一个链接提供了我所需的引用,以确保这是正确的。
由于这是我最短的例子,所以这里是“19秒思考”面板的扩展截图。我总是会扩展这些想法——观察它是如何整合答案的,这对于评估答案是否有用至关重要。
埃克塞特码头洞穴的历史
埃克塞特的海滨餐厅是不是挖在悬崖里了?它的历史、建造者、建造原因和建造方式是什么?
我们来这里吃饭,发现餐厅的内部看起来像是挖进悬崖的一个空间,这引起了我的兴趣。
正是这次ChatGPT 会议启发了“研究哥布林”这个绰号。它一直在挖掘!
第一个回复花了 2 分 40 秒,确认是的,这些码头建筑是在 19 世纪 20 年代至 30 年代雕刻在红色砂岩悬崖上的。
GPT-5 的 ChatGPT 确实喜欢建议可以采取的额外步骤。在这种情况下:
如果您愿意,我可以找出涵盖“南方仓库”地址的确切英国历史记载,并将其叠加在金库地图上。
我经常出于好奇说“是”,想看看它下一步会做什么,而“将其叠加在地图上”的提议是无法抗拒的,比如它会怎么做呢?
它进行了大量额外的搜索,找到了餐厅的经纬度坐标(来自 Wikimedia Commons)和仓库建筑(来自维基百科的英格兰国家遗产名录),在表格中向我显示了这些数据,然后使用 Python 渲染了这幅图像:
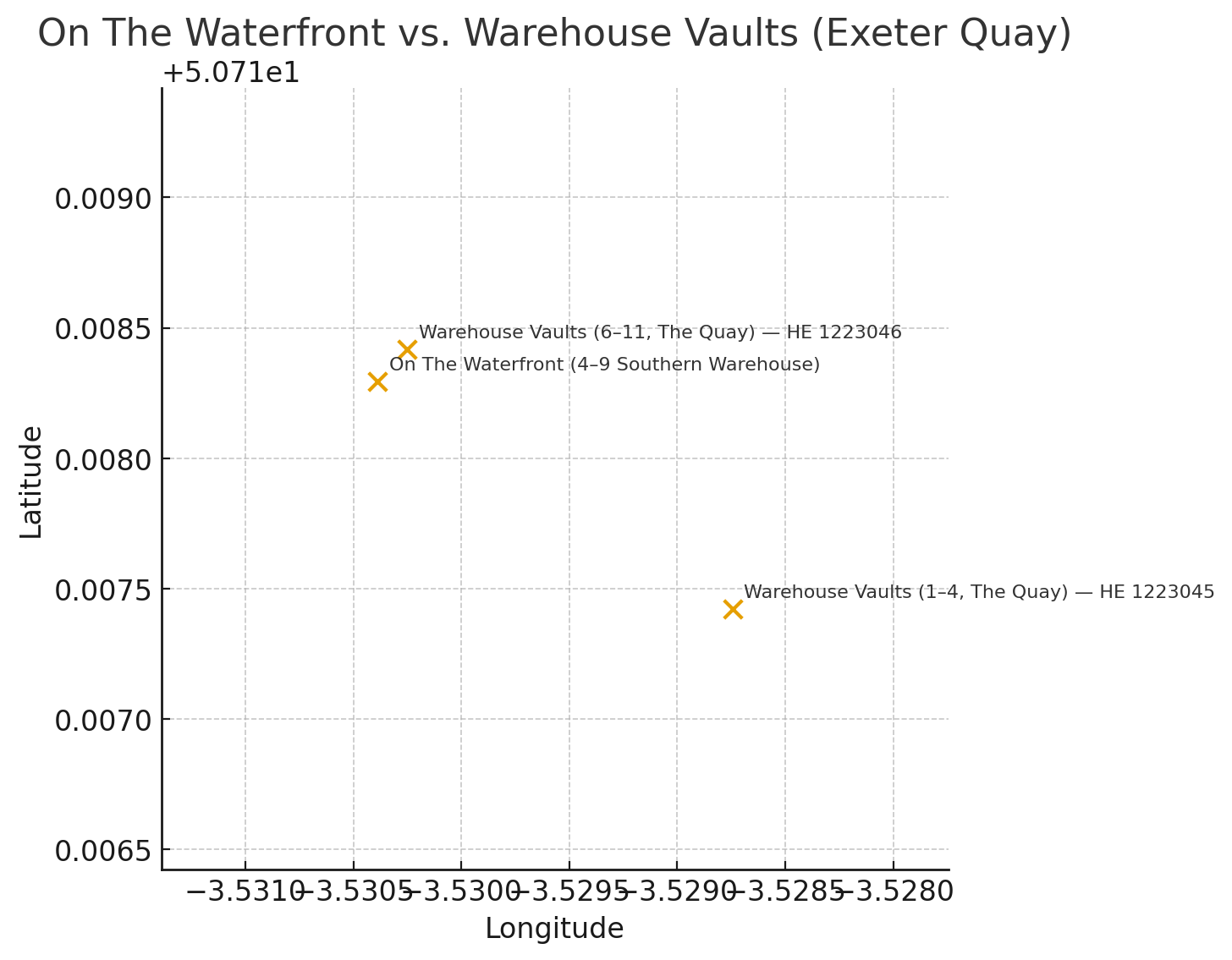
是啊,所以那有点错过!
但是……底层的研究链一如既往地引人入胜。我注意到它曾经搜索过“埃克塞特码头金库地图PDF”,这启发了我的下一个问题:
你找到任何 PDF 图表了吗,显示通往悬崖的隧道
2分20秒后,它找到了一份规划文件和一份出租手册,都是PDF格式,但提示两者都没有我想要的图表。显然,它实际上是在“读取”找到的PDF文件,因为它似乎不仅了解文本内容,还了解其中的图片。
文章最后给出了这样一条有趣的注释:
有强有力的证据表明,规划人员经常引用的埃克塞特考古报告——《埃克塞特运河盆地考古、历史和保护研究》(埃克塞特考古报告 00.18,2000) ——确实存在一份详细的规划/剖面图,但该报告并未在线发布;它只是在规划文件中被引用。您可能需要通过德文郡遗产中心/历史环境记录中心申请。
如果您愿意,我可以继续在专业档案馆中寻找数字化副本或包含保险库布局的其他报告。
显然我说“是的,那就这么做”,2 分 24 秒后,它弹出一大堆额外的链接,对它仍然没有找到详细的计划图表示歉意,并在标题为“我下一步的建议(可操作 + 确切要求)”的部分下显示:
如果您满意,我可以起草一封电子邮件,您可以将其粘贴给合适的档案管理员。[…]
主题:埃克塞特码头悬崖拱顶 – 索取平面图/剖面图 你好,
我正在研究码头(The Quay,位于海滨/国王码头)后面的悬崖拱顶。您能否提供这些拱顶的平面图/剖面图/示意图的扫描件或复印件,尤其是《埃克塞特考古报告 00.18 (2000)》 (埃克塞特运河盆地考古、历史和保护研究)中的那些,以及EMAFU/埃克塞特考古部门为“码头”绘制的图纸,其中展示了开凿于红砂岩悬崖上的拱顶/隧道的布局?
供参考:NHLE 列表条目1223045(1-4 个仓库金库)、1223046(6-11 个仓库金库)和1223114(14-25 个金库) 。
非常感谢!
幸好我的研究地精没有发送电子邮件的能力(我们已经知道这是非常危险的事情),否则现在如果它开始自动代表我打扰档案管理员,我也不会感到惊讶!
Aldi 与 Lidl
在英国超市方面,比较一下 Lidl 和 Aldi
我在埃克塞特看到Aldi和Lidl并排开着,很好奇它们之间有什么区别。结果我的“研究小精灵”比我预想的要深入得多,花了1分25秒思考市场份额、价格调查和会员计划,最后用十段详细的分析来回答。
我回答道:
是的,我只是想要基本的感觉,比如哪一个比另一个更花哨?
它思考了 6 秒,没有进行任何额外的搜索并回答道:
简而言之:两家店都不算“高档”——都是简洁的折扣店——但Lidl 给人的感觉更精致一些,而Aldi 则感觉更简陋一些。[…]
由于我现在很享受我的妖精对英国连锁超市的评判,所以我说:
与英国其他主要连锁超市相比,他们在 fancinews 上的评级如何?
(这是“fancy”的拼写错误,它已经识别出来了。)
它又思考了 1 分 1 秒,进行了 7 次搜索,查阅了 27 个 URL,然后给了我一个对我来说似乎合适的排名。

人工智能实验室扫描书籍以获取训练数据
Anthropic 买了很多纸质书,把它们剪下来扫描起来作为训练数据。其他 AI 实验室也做同样的事情吗?
与今天的重头戏相关。Research Goblin未能找到任何新闻报道或其他证据表明,除 Anthropic 之外,还有其他实验室正在大规模扫描书籍以获取训练数据。这并不是说这种事情没有发生,但如果真的发生了,那它肯定是在悄无声息地进行。
GPT-5 在搜索方面表现不错
最能描述我对 GPT-5 搜索的感受的词是“感觉很有能力” 。
过去几周,我尝试了各种各样的方法,它很少让我失望。它几乎总是比我花同样的时间手动搜索效果更好,主要是因为它运行搜索和评估结果的速度比我快得多。
我尤其喜欢它在移动设备上的出色表现。我以前总是在笔记本电脑上进行深入研究,因为这样我可以打开几十个标签页。现在我仍然会这样做,进行一些高风险的活动,但我发现,仅凭手机,我在旅途中就能满足好奇心的范围已经大幅提升。
我基本上已经停止使用 OpenAI 的深度研究功能,因为 ChatGPT 搜索现在可以为大多数查询更快地提供我感兴趣的结果。
作为一名在 LLM 上构建软件的开发者,我认为 ChatGPT 搜索是工具调用与思维链相结合所能实现的黄金标准。如果能将 RAG 等技术重新构建为多层级的工具调用,并结合一组精心挑选的强大搜索工具,其效率将大幅提升。
搜索工具与推理相结合的方式是关键,因为它允许 GPT-5 执行搜索、推理结果,然后执行后续搜索——所有这些都是初始“思考”过程的一部分。
Anthropic 将这种能力称为交错思维,并且它也受到 OpenAI Responses API 的支持。
在 ChatGPT 中使用搜索的技巧
与所有 AI 事物一样,GPT-5 搜索奖励通过经验积累的直觉。每当一个好奇的想法闪现在我的脑海里,我都会试着抓住它,然后把它扔给我的研究哥布林。如果我确定它无法处理,那就更好了!我可以从观察它的失败中学习。
我一直在尝试“深入”之类的暗示,这似乎能引发更彻底的研究。我喜欢用这些暗示来回答一些肤浅且不重要的问题,比如英国星巴克蛋糕棒棒糖的问题,看看会发生什么!
你可以向它提出答案单一、明确的问题——但我认为,那些范围更广、没有“正确”答案的问题会更有趣。上面的英国超市排名就是一个很好的例子。
我喜欢用一个比较有争议的比喻来形容法学硕士研究妖精……好吧,它就是个妖精。它非常勤奋,不太像人类,也不完全值得信赖。如果你想让它继续工作,就必须得智胜它。
标签: bing 、搜索、人工智能、 OpenAI 、生成式人工智能、 LLMS 、 LLM 工具使用、 LLM 推理、 GPT-5
原文: https://simonwillison.net/2025/Sep/6/research-goblin/#atom-everything