跟上像AI这样快速发展的行业是一项艰巨的任务。因此,在 AI 可以为您做这件事之前,这里是机器学习领域上周故事的便捷综述,以及我们没有单独介绍的著名研究和实验。
本周,谷歌在其年度 I/O 开发者大会上发布了一系列新产品,主导了 AI 新闻周期。从旨在与 GitHub 的 Copilot 竞争的代码生成 AI到将文本提示转换为短歌的 AI 音乐生成器,它们涵盖了所有领域。
这些工具中有相当一部分看起来是合法的节省劳动力的工具——也就是说,不仅仅是营销上的废话。我对Project Tailwind特别感兴趣,这是一款笔记应用程序,它利用 AI 来组织、总结和分析个人 Google 文档文件夹中的文件。但它们也暴露了当今最好的人工智能技术的局限性和缺点。
以PaLM 2为例,Google 最新的大型语言模型 (LLM)。 PaLM 2 将为谷歌更新的 Bard 聊天工具提供动力,该公司是 OpenAI 的 ChatGPT 的竞争对手,并作为谷歌大部分新人工智能功能的基础模型。但是,虽然 PaLM 2 可以编写代码、电子邮件等,就像类似的法学硕士一样,它也会以有毒和有偏见的方式回答问题。
谷歌的音乐生成器的功能也相当有限。正如我在手上所写的那样,我用 MusicLM 创作的大多数歌曲充其量听起来还过得去——最坏的情况下就像一个四岁的孩子在DAW上放任自流。
根据高盛 (Goldman Sachs) 的一份报告,关于人工智能将如何取代工作的文章很多——可能相当于 3 亿个全职工作岗位。在 Harris 的一项调查中,40% 熟悉 OpenAI 的人工智能聊天机器人工具 ChatGPT 的员工担心它会完全取代他们的工作。
谷歌的人工智能并不是万能的。事实上,该公司在 AI 竞赛中可以说是落后的。但不可否认的是,谷歌聘请了一些世界顶尖的人工智能研究人员。如果这是他们能做到的最好的结果,那就证明人工智能远未解决问题。
以下是过去几天的其他 AI 头条新闻:
- Meta 将生成人工智能引入广告: Meta 本周宣布了一个人工智能沙箱,可以帮助广告商创建替代副本、通过文本提示生成背景以及为 Facebook 或 Instagram 广告裁剪图像。该公司表示,这些功能目前可供部分广告商使用,并将在 7 月扩大对更多广告商的访问权限。
- 添加上下文: Anthropic 已将 Claude 的上下文窗口(其旗舰文本生成 AI 模型,仍在预览中)从 9,000 个令牌扩展到 100,000 个令牌。上下文窗口指的是模型在生成额外文本之前考虑的文本,而标记代表原始文本(例如,单词“fantastic”将被拆分为标记“fan”、“tas”和“tic”)。从历史上看,甚至在今天,记忆力不佳一直是文本生成人工智能发挥作用的障碍。但更大的上下文窗口可能会改变这一点。
- Anthropic 吹捧“宪法 AI”:更大的上下文窗口并不是 Anthropic 模型的唯一区别。该公司本周详细介绍了“宪法人工智能”,这是其内部人工智能培训技术,旨在为人工智能系统灌输由“宪法”定义的“价值观”。与其他方法相比,Anthropic 认为宪法 AI 使系统的行为既更容易理解,也更容易根据需要进行调整。
- 为研究而建的法学硕士:非营利组织艾伦人工智能研究所 (AI2) 宣布,它计划培训一个名为开放语言模型的以研究为重点的法学硕士,并将其添加到庞大且不断增长的开源库中。 AI2 将 Open Language Model(简称 OLMo)视为一个平台,而不仅仅是一个模型——一个允许研究社区获取 AI2 创建的每个组件并自己使用或寻求改进的平台。
- AI 新基金:在 AI2 的其他新闻中,非营利组织的 AI 启动基金 AI2 孵化器再次加速增长,规模是之前的三倍——3000 万美元对 1000 万美元。自 2017 年以来,已有 21 家公司通过孵化器,吸引了约 1.6 亿美元的进一步投资和至少一项重大收购:XNOR,这是一家 AI 加速和效率公司,随后被 Apple 以约 2 亿美元收购。
- 欧盟引入了生成人工智能的规则:在欧洲议会的一系列投票中,欧洲议会议员本周支持对欧盟的人工智能立法草案进行大量修正——包括确定支持生成人工智能技术的所谓基础模型的要求,如 OpenAI 的聊天GPT 。这些修正案使基础模型的供应商有责任在将其模型投放市场之前应用安全检查、数据治理措施和风险缓解措施
- 通用翻译器:谷歌正在测试一种功能强大的新翻译服务,该服务可以将视频翻译成一种新语言,同时还能将说话者的嘴唇与他们从未说过的话同步。由于很多原因,它可能非常有用,但该公司对滥用的可能性以及为防止滥用而采取的措施是坦率的。
- 自动解释:人们常说,与OpenAI 的 ChatGPT类似的 LLM 是一个黑匣子,当然,这有一定道理。为了剥离它们的层次,OpenAI 正在开发一种工具来自动识别 LLM 的哪些部分对其行为负责。它背后的工程师强调它还处于早期阶段,但运行它的代码本周可以在 GitHub 上以开源方式获得。
- IBM 推出新的 AI 服务:在其年度 Think 会议上,IBM 宣布推出 IBM Watsonx,这是一个新平台,可提供构建 AI 模型的工具,并提供对用于生成计算机代码、文本等的预训练模型的访问。该公司表示,推出该产品的动机是许多企业在工作场所部署 AI 时仍面临挑战。
其他机器学习
图片来源:登陆 AI
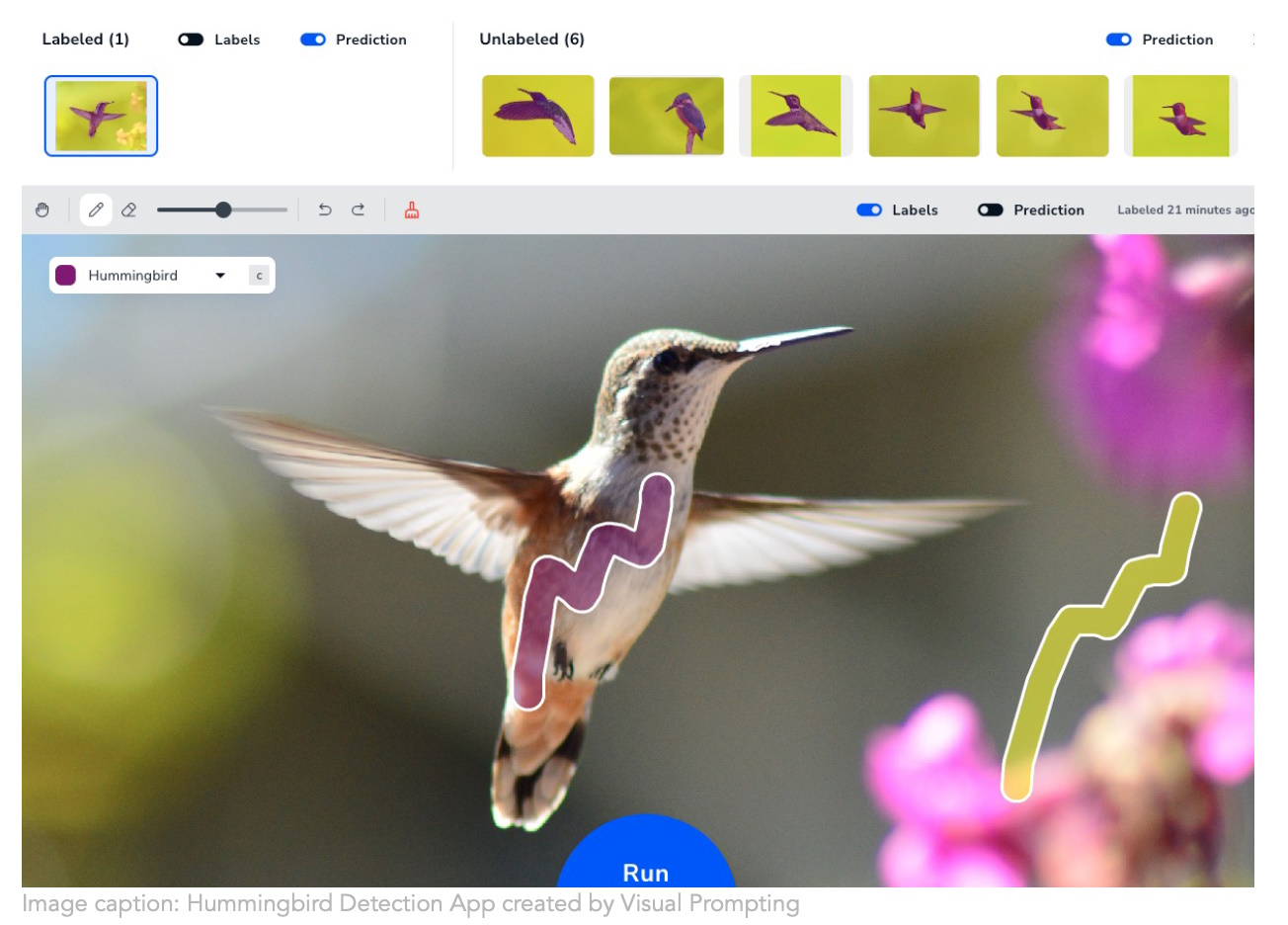
Andrew Ng 的新公司Landing AI正在采用更直观的方法来创建计算机视觉训练。让模型理解你想在图像中识别什么是非常费力的,但他们的“视觉提示”技术让你只需画几下笔触,它就会从那里弄清楚你的意图。任何必须建立细分模型的人都在说“我的上帝,终于!”可能有很多研究生目前花费数小时来掩盖细胞器和家用物品。
微软以一种独特而有趣的方式应用了扩散模型,本质上是使用它们来生成动作向量而不是图像,并根据大量观察到的人类动作对其进行训练。现在还很早,扩散并不是解决这个问题的明显解决方案,但由于它们稳定且用途广泛,因此很有趣的是看看它们如何应用于纯视觉任务之外。他们的论文将于今年晚些时候在 ICLR 上发表。
图片学分:元
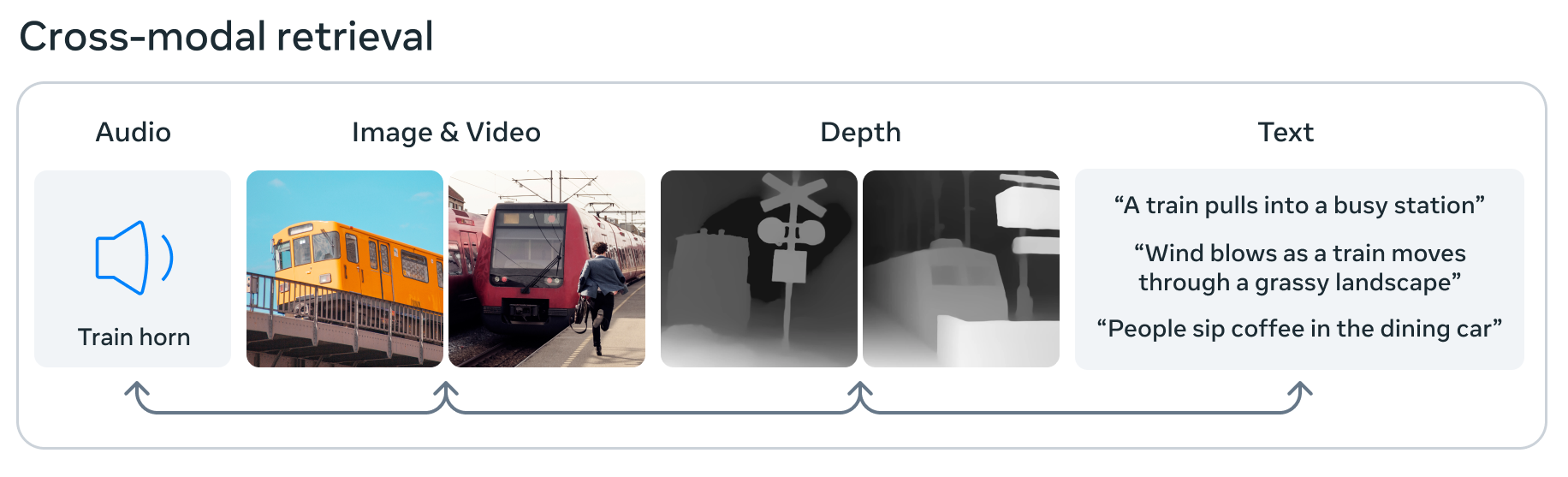
Meta 还通过ImageBind推动人工智能的发展,它声称这是第一个可以处理和集成来自六种不同模式的数据的模型:图像和视频、音频、3D 深度数据、热信息以及运动或位置数据。这意味着在其小的机器学习嵌入空间中,图像可能与声音、3D 形状和各种文本描述相关联,其中任何一个都可以被询问或用于做出决定。这是向“通用”人工智能迈出的一步,因为它更像大脑一样吸收和关联数据——但它仍然是基础的和实验性的,所以现在不要太兴奋。
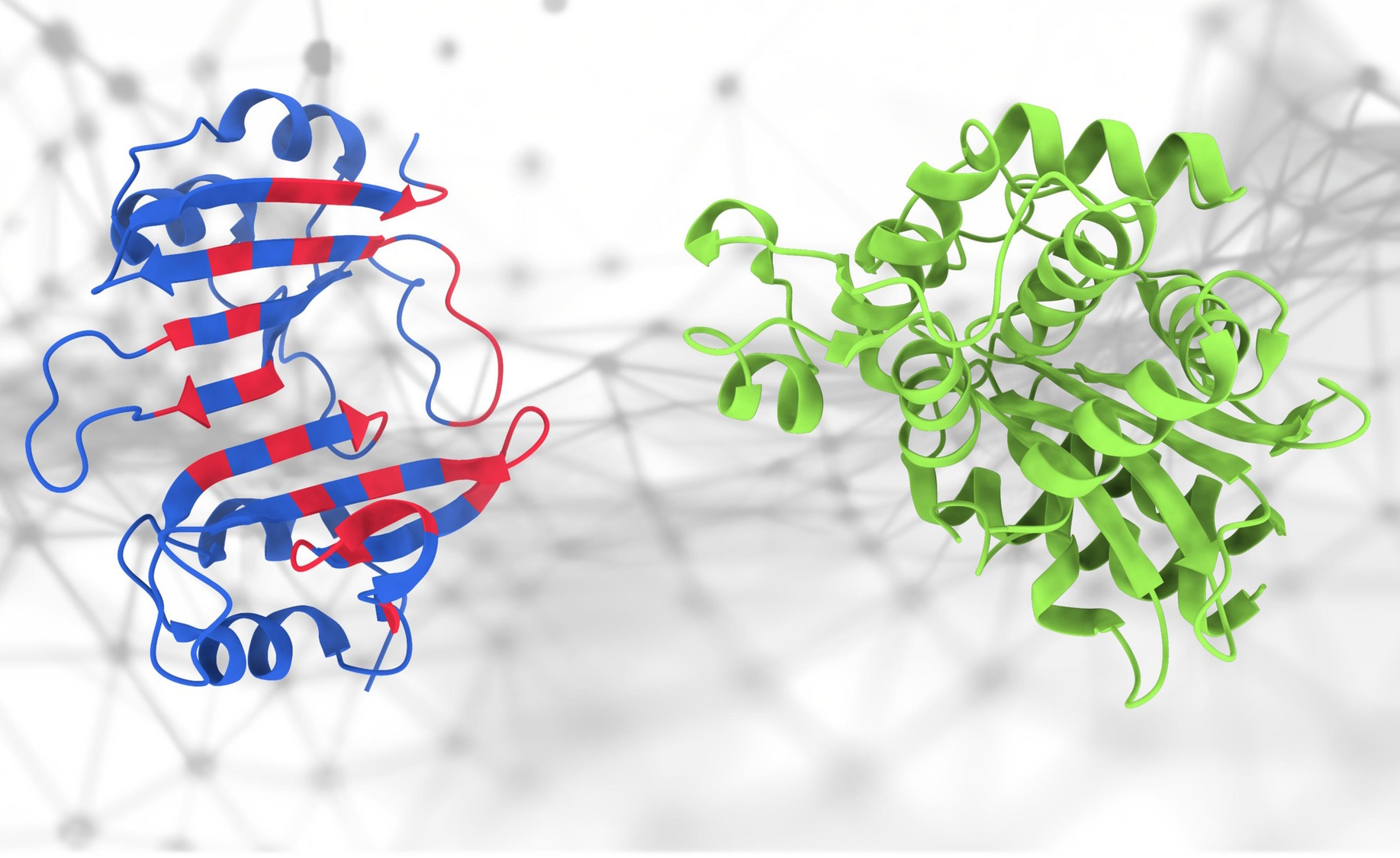
如果这些蛋白质接触……会发生什么?
每个人都对 AlphaFold 感到兴奋,这是有充分理由的,但实际上结构只是非常复杂的蛋白质组学科学的一小部分。这些蛋白质如何相互作用既重要又难以预测——但EPFL 的这种新 PeSTo 模型正试图做到这一点。 “它专注于蛋白质结构中的重要原子和相互作用,”首席开发人员 Lucien Krapp 说。 “这意味着这种方法有效地捕获了蛋白质结构内的复杂相互作用,从而能够准确预测蛋白质结合界面。”即使它不准确或 100% 可靠,不必从头开始对研究人员来说也是非常有用的。
联邦调查局在 AI 上大放异彩。总统甚至参加了与一群顶级 AI CEO 的会谈,以说明实现这一目标的重要性。也许一堆公司不一定是合适的询问对象,但他们至少会有一些值得考虑的想法。但他们已经有说客了,对吧?
我对获得联邦资助的新 AI 研究中心感到更加兴奋。非常需要基础研究来平衡 OpenAI 和谷歌等公司所做的以产品为中心的工作——所以当你有 AI 中心的任务是调查社会科学(在 CMU)或气候变化和农业( 在 U of明尼苏达州),感觉就像绿色的田野(无论是比喻还是字面上)。尽管我也想对这项关于林业测量的元研究大声疾呼。

在大屏幕上一起做人工智能——这是科学!
那里有很多关于 AI 的有趣对话。我认为这次采访加州大学洛杉矶分校(我的母校,去棕熊队)学者雅各布福斯特和丹尼斯内尔森是一个有趣的采访。这是关于法学硕士的一个很棒的想法,假装你在这个周末当人们谈论 AI 时想到了:
这些系统揭示了大多数写作在形式上的一致性。这些预测模型模拟的格式越通用,它们就越成功。这些发展促使我们认识到我们形式的规范功能,并有可能改变它们。在非常擅长捕捉具象空间的摄影术引入之后,绘画环境发展了印象派,这种风格完全拒绝准确的表现,而是停留在绘画本身的物质性上。
一定要用那个!
AI 周:谷歌在 I/O 上全力以赴,因为法规逐渐提高Kyle Wiggers最初发表于TechCrunch
原文: https://techcrunch.com/2023/05/13/the-week-in-ai-google-goes-all-out-at-i-o-as-regulations-creep-up/