人们常说情境为王,这在人工智能产品中确实如此。应用程序向人工智能模型提供的内容、工具和指令决定了它们的行为和后续结果。但是,如果情境如此重要,我们如何才能让人们在与人工智能驱动的软件交互时理解和管理它呢?
在人工智能产品中,很多内容可能在任何给定时刻都与上下文相关(作为指令的一部分提供给人工智能模型),但由于人工智能模型存在上下文限制,并非所有内容都会始终与上下文相关。因此,当人们从人工智能产品中获取结果时,他们不确定是否应该信任它们,或者应该在多大程度上信任它们。我回答问题时使用了正确的信息吗?模型是产生了幻觉还是使用了错误的信息?
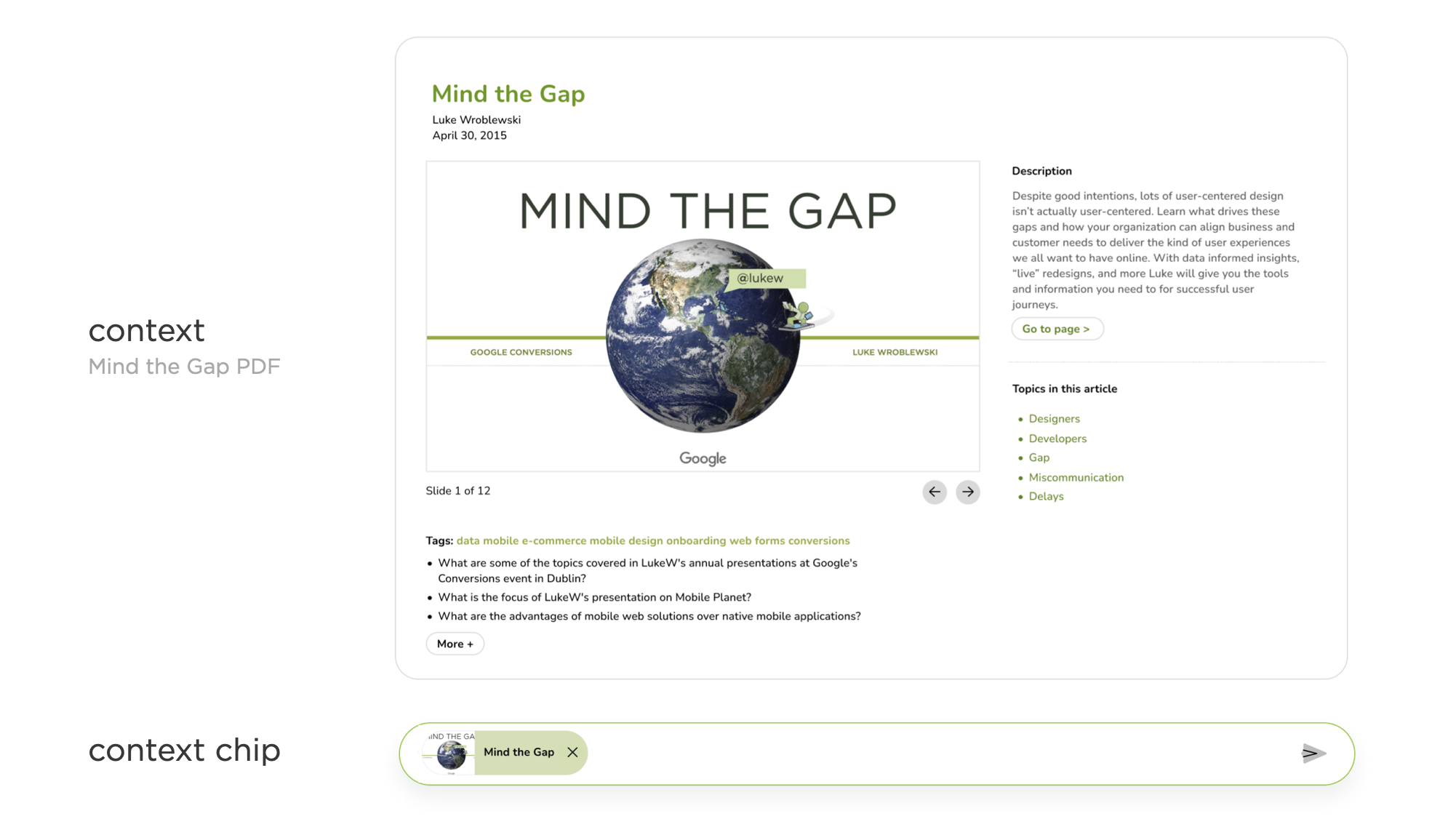
两年前,当我推出我的个人 AI 时,语境比现在简单得多。在Ask LukeW中,当人们询问有关数字产品设计的问题时,系统会搜索我的写作,找到最相关的内容,并将其放入语境中,供 AI 模型使用和参考,然后在人们看到的结果中将其标注出来。这在界面上非常清晰:所用到的文章、视频、音频和 PDF 显示在右侧,每个回复中都标明了这些文件最常被引用的地方。

Ask LukeW 中最复杂的事情是当有人打开这些引用的文章、视频或 PDF 文件以查看其全部内容时。在这种情况下,问题栏中会添加一个小的“上下文芯片”,以明确只针对该文件提问。换句话说,该文件是上下文中的主要内容。如果有人想再次针对我的全部著作和演讲内容提问,只需点击 X 即可移除此上下文限制,芯片就会从问题栏中消失。您可以在这里亲自尝试一下。
上下文芯片在当今的人工智能产品中非常常见,因为它们是一种相对简单的方法,既能让人们了解影响人工智能模型回复的因素,又能方便地添加或删除这些因素。然而,当上下文内容扩展时,它们的扩展性就不太好。例如, Augment Code将上下文芯片用于检索系统、活动文件、选定文本等。
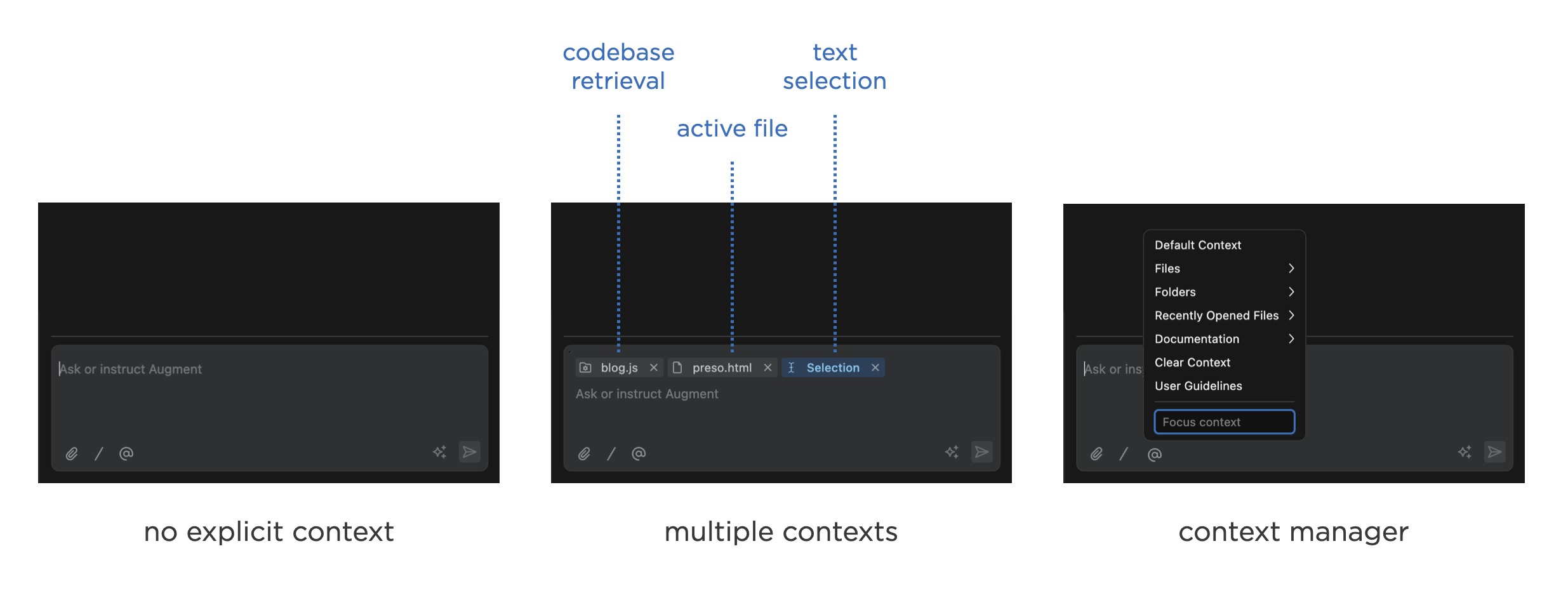
当许多事物(尤其是不同的事物)都处于上下文中时,使用上下文芯片来显示所有影响AI模型响应的事物就会失效。将它们全部显示出来会占用UI中宝贵的空间,并且需要截断它们的名称或标识符才能适应上下文。这在某种程度上违背了“显示上下文内容”的初衷。此外,当AI产品像Augment Code的上下文检索引擎那样进行自动上下文检索时:它是否总是会以芯片的形式显示?或者人们是否应该不必担心,而应该相信系统能够找到正确的事物并将其放入上下文中?
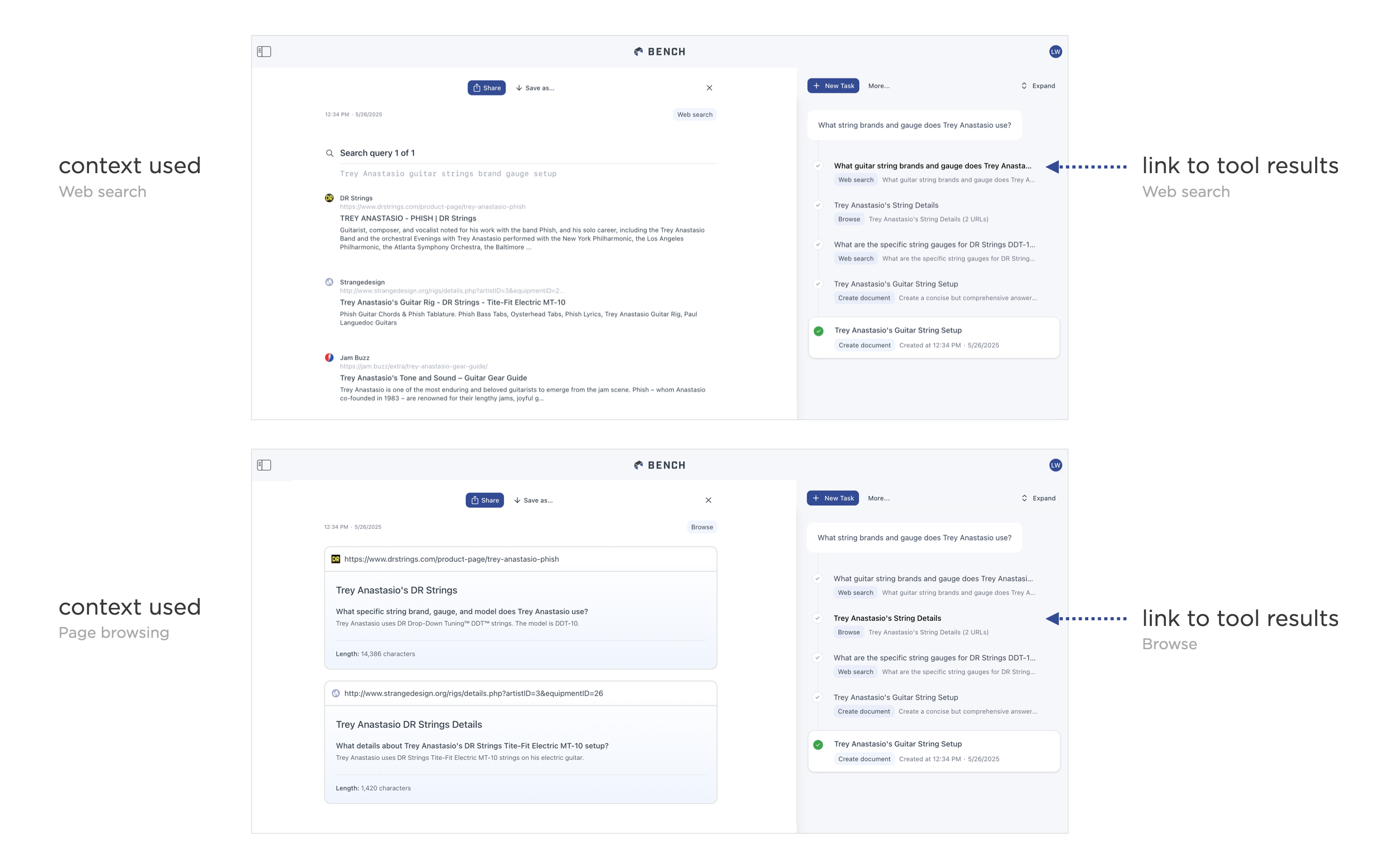
对于使用代理的AI产品来说,这些问题更加复杂,因为代理每次调用工具时,都可能以不同的方式或多次检索上下文。因此,将工具发现或创建的每一点上下文都显示为上下文芯片很快就会失效。为了解决这个问题,在早期版本的Bench中,我们展示了代理使用的工具创建上下文的过程。但这最终带来了令人不快的体验,因为上下文会显示出来,然后在下一个工具的上下文出现时消失(正如您在视频中看到的那样)。 )。
从那时起,我们开始将代理创建某件物品的过程以精简的步骤展示,并在每个步骤中提供上下文链接。这样,用户可以点击任何给定的步骤来查看工具找到或创建的上下文。但这些上下文不会在工具制作过程中自动闪现。这样,用户可以专注于最终结果,只有在想要了解最终结果背后的原因时,才会深入研究整个过程。
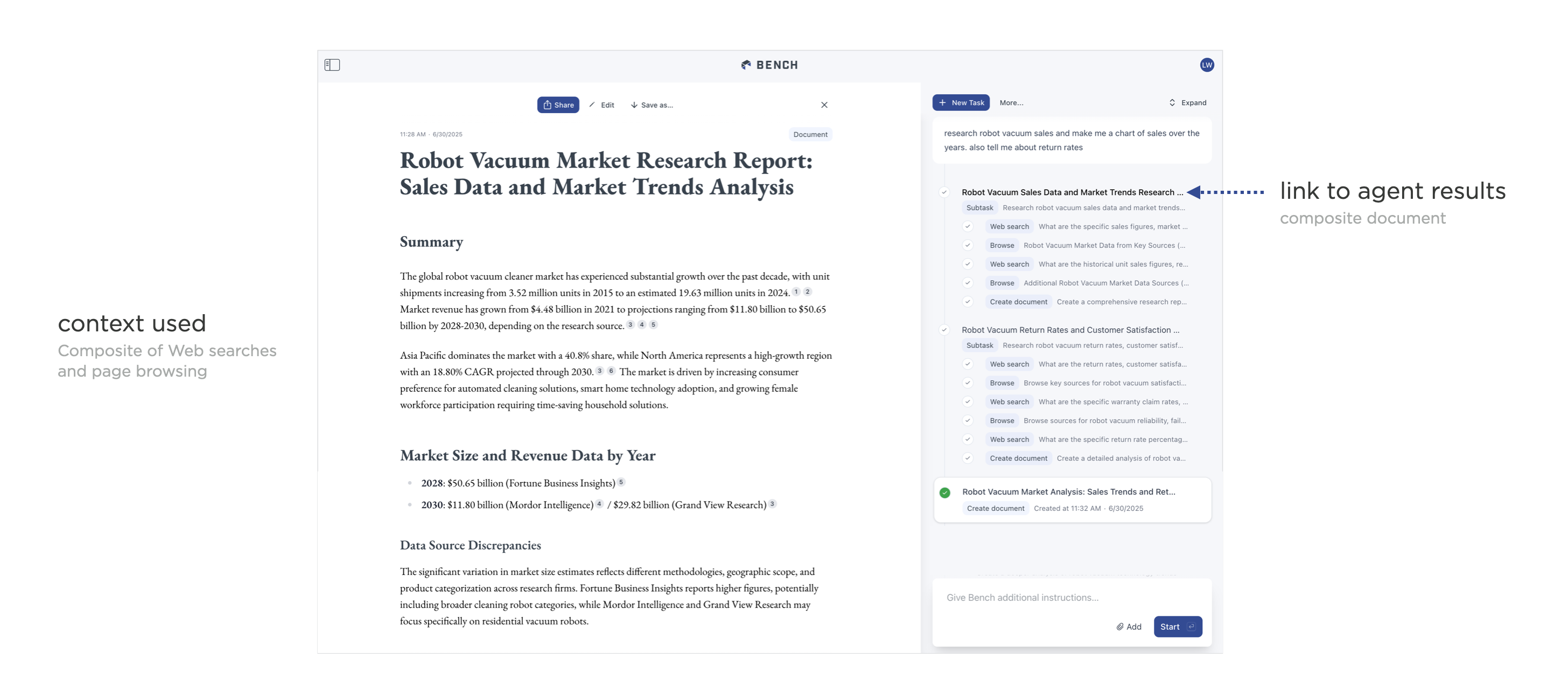
这种方法在代理编排方面更加适用。当代理能够利用自身代理时,最终会得到大量的嵌套上下文。两年前就说过,事情要简单得多!在这种情况下,Bench 只会在一个链接中显示由多个工具调用组合而成的集合上下文。这允许人们检查子代理创建的累积上下文。但重要的是,无论来自单个工具还是使用多个工具的子代理,这些组合上下文的处理方式都相同。
虽然让上下文易于理解和管理似乎是提供透明度和控制力的正确选择,但人们似乎越来越关注人工智能产品的输出,而不是创建它们的过程。只有当事情看起来“不对劲”时,他们才会深入研究Bench提供的各种流程时间线和上下文链接。因此,如果人们使用人工智能产品变得更加自信,我们可能会看到上下文管理UI的存在感越来越弱。