这是 LLM 的“锯齿状前沿”下的另一个有趣结果,其优势和劣势往往是难以直观体现的。
长上下文模型最近在通过“大海捞针”测试方面越来越出色,但是相反方向的问题又如何呢?
本文探讨了当你给模型提供一些内容,然后删除一部分内容的副本,然后询问发生了什么变化时会发生什么。
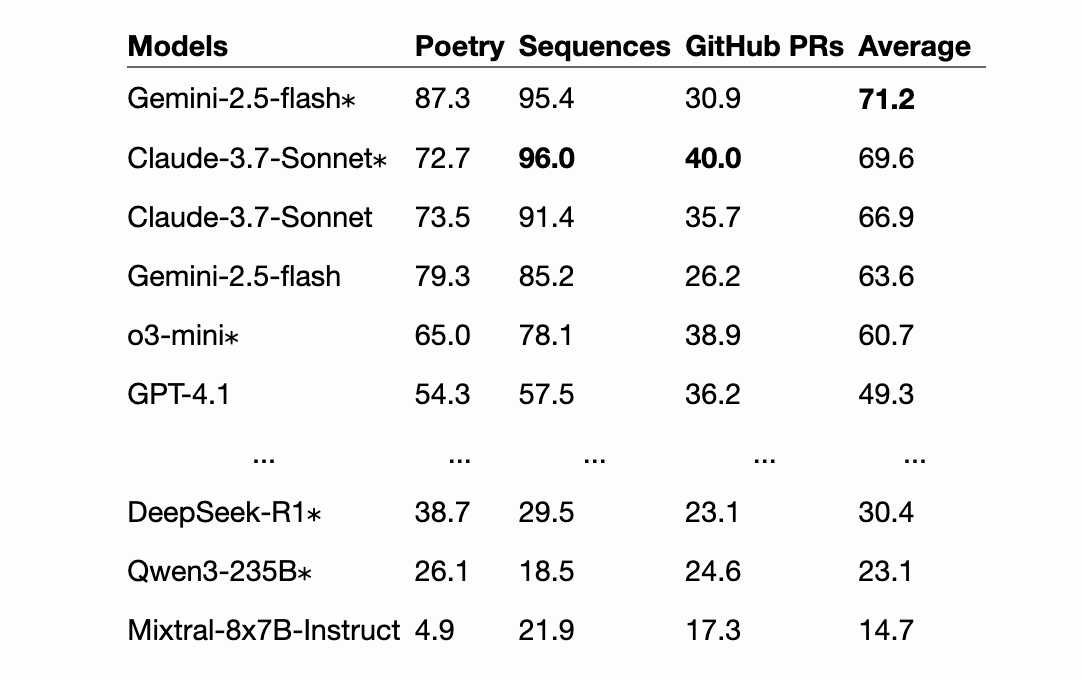
以下是该论文结果的节选表:
| 模型 | 诗 | 序列 | GitHub PR | 平均的 |
|---|---|---|---|---|
双子座-2.5-闪光* |
87.3 | 95.4 | 30.9 | 71.2 |
克劳德-3.7-十四行诗* |
72.7 | 96.0 | 40.0 | 69.6 |
| 克劳德-3.7-十四行诗 | 73.5 | 91.4 | 35.7 | 66.9 |
| 双子座-2.5-闪光 | 79.3 | 85.2 | 26.2 | 63.6 |
o3-迷你* |
65.0 | 78.1 | 38.9 | 60.7 |
| GPT-4.1 | 54.3 | 57.5 | 36.2 | 49.3 |
| … | … | … | … | … |
DeepSeek-R1 * |
38.7 | 29.5 | 23.1 | 30.4 |
Qwen3-235B * |
26.1 | 18.5 | 24.6 | 23.1 |
| Mixtral-8x7B-指导 | 4.9 | 21.9 | 17.3 | 14.7 |
*表示推理模型。序列是数字列表,例如117,121,125,129,133,137 ;诗歌由古腾堡诗歌语料库中的 100-1000 行组成;PR 是包含 10 到 200 行更新的差异。
最强大的模型在数字序列上表现良好,在诗歌挑战中表现尚可,但在 PR diff 上却表现糟糕。推理模型的表现略好一些,但代价是消耗大量的推理 token——通常比原始文档的长度还要长。
论文作者 Harvey Yiyun Fu、Aryan Shrivastava、Jared Moore、Peter West、Chenhao Tan 和 Ari Holtzman 对这里发生的事情提出了一个假设:
我们提出一个初步假设来解释这种行为:利用 Transformers (Vaswani et al., 2017) 背后的注意力机制,识别“存在”比“不存在”更简单。文档中包含的信息可以被直接关注,而信息的缺失则无法被关注。
来源: Hacker News
标签:人工智能、生成人工智能、法学硕士、评估、法学硕士推理、长上下文
原文: https://simonwillison.net/2025/Jun/20/absencebench/#atom-everything