对于训练有素的数据科学家 Jae Lee 来说,由于技术障碍,视频已经成为我们生活中不可或缺的一部分,随着 TikTok、Vimeo 和 YouTube 等平台的兴起,视频很难被搜索到,这完全没有道理由上下文理解构成。搜索视频的标题、描述和标签总是很容易,只需要一个基本的算法。但是在视频中搜索特定的时刻和场景远远超出了技术的能力范围,特别是如果这些时刻和场景没有以明显的方式标记的话。
为了解决这个问题,Lee 与科技界的朋友一起构建了一个用于视频搜索和理解的云服务。它变成了Twelve Labs ,它继续筹集了 1700 万美元的风险投资——其中 1200 万美元来自今天结束的种子扩展轮。 Lee 在一封电子邮件中告诉 TechCrunch,Radical Ventures 在 Index Ventures、WndrCo、Spring Ventures、Weights & Biases 首席执行官 Lukas Biewald 和其他人的参与下牵头进行了扩展。
“Twelve Labs 的愿景是通过为他们提供最强大的视频理解基础架构,帮助开发人员构建能够像我们一样看到、听到和理解世界的程序,”Lee 说。
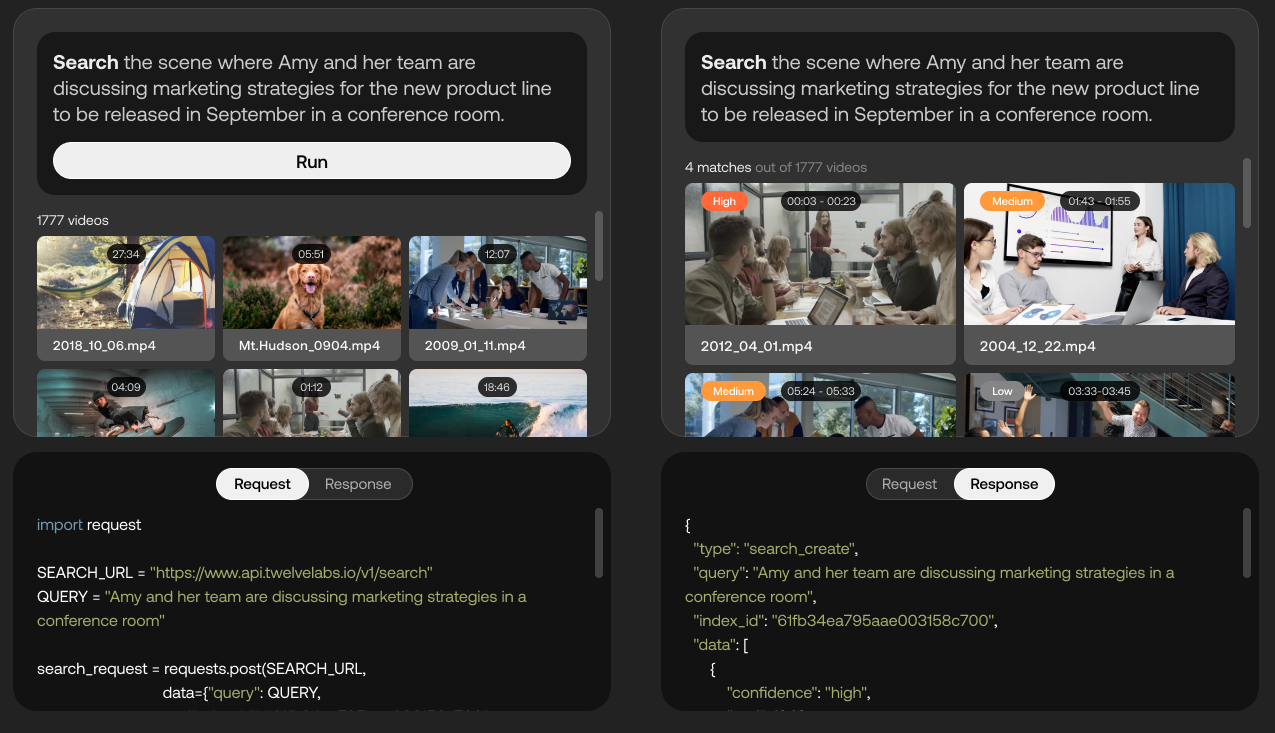
Twelve Labs 平台功能的演示。图片来源:十二实验室
目前处于封闭测试阶段的 Twelve Labs 使用 AI 尝试从视频中提取“丰富的信息”,例如运动和动作、物体和人物、声音、屏幕上的文本和语音,以识别它们之间的关系。该平台将这些不同的元素转换为称为“向量”的数学表示形式,并在帧之间形成“时间连接”,从而实现视频场景搜索等应用。
“作为实现公司帮助开发人员创建智能视频应用程序的愿景的一部分,Twelve Labs 团队正在构建多模态视频理解的‘基础模型’,”Lee 说。 “开发人员将能够通过一套 API 访问这些模型,不仅执行语义搜索,还执行其他任务,例如长格式视频‘章节化’、摘要生成和视频问答。”
谷歌通过其MUM AI 系统采用类似的视频理解方法,该公司使用该系统根据音频、文本和视觉来挑选视频中的主题(例如,“丙烯画材料”),从而在 Google 搜索和 YouTube 上为视频推荐提供支持内容。但是,尽管这项技术可能具有可比性,但 Twelve Labs 是首批将其推向市场的供应商之一;谷歌选择将 MUM 保留在内部,拒绝通过面向公众的 API 提供它。
也就是说,谷歌以及微软和亚马逊提供的服务(即谷歌云视频 AI、Azure 视频索引器和 AWS Rekognition)可以识别视频中的对象、地点和动作,并在帧级别提取丰富的元数据。还有Reminiz ,这是一家法国计算机视觉初创公司,声称能够为任何类型的视频编制索引,并为录制的和直播的内容添加标签。但 Lee 断言,Twelve Labs 具有足够的差异化——部分原因是其平台允许客户针对特定类别的视频内容微调 AI。

用于微调模型以更好地处理沙拉相关内容的 API 模型。图片来源:十二实验室
“我们发现,为检测特定问题而构建的狭义 AI 产品在受控环境中的理想场景中显示出高精度,但不能很好地扩展到混乱的现实世界数据,”Lee 说。 “它们更像是一个基于规则的系统,因此在出现差异时缺乏概括能力。我们也将此视为源于缺乏上下文理解的限制。对上下文的理解赋予了人类独特的能力,可以对现实世界中看似不同的情况进行概括,而这正是 Twelve Labs 独树一帜的地方。”
Lee 表示,除了搜索之外,Twelve Labs 的技术还可以推动广告插入和内容审核等工作,例如,智能地判断哪些显示刀具的视频是暴力的,哪些是教育性的。他说,它还可以用于媒体分析和实时反馈,并自动从视频中生成精彩片段。
成立一年多后(2021 年 3 月),Twelve Labs 拥有付费客户(Lee 不愿透露具体数量),并与 Oracle 签订了一份多年合同,使用 Oracle 的云基础设施来训练 AI 模型。展望未来,这家初创公司计划投资建设其技术并扩大其团队。 (Lee 拒绝透露 Twelve Labs 目前的员工人数,但 LinkedIn数据显示大约有 18 人。)
“对于大多数公司来说,尽管通过大型模型可以获得巨大的价值,但他们自己训练、运营和维护这些模型确实没有意义。通过利用 Twelve Labs 平台,任何组织都可以通过几个直观的 API 调用来利用强大的视频理解功能,”Lee 说。 “人工智能创新的未来方向是直接朝着多模态视频理解方向发展,而 Twelve Labs 已准备好在 2023 年进一步突破界限。”
Twelve Labs 获得 1200 万美元用于人工智能,该人工智能理解Kyle Wiggers最初发布在TechCrunch上的视频的上下文