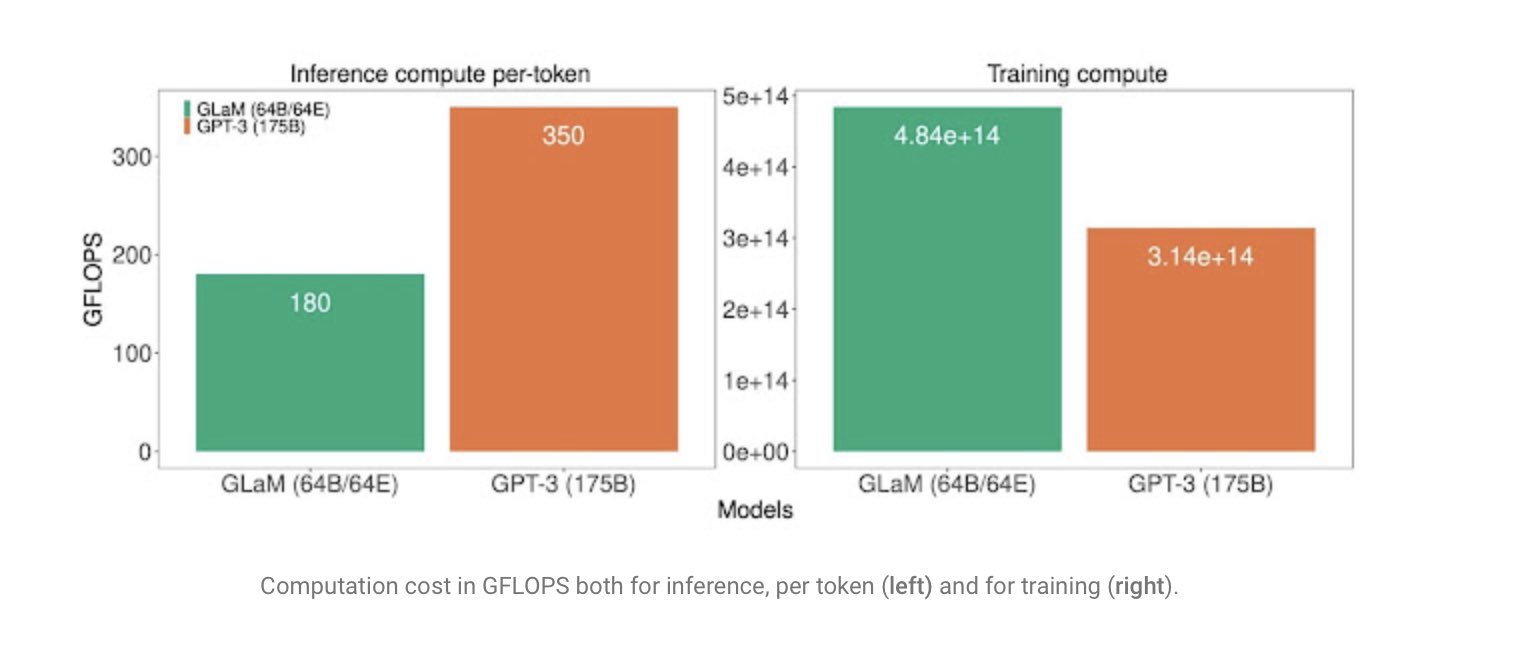
原推:Reduce AI inference load at the endpoint device by spending more upfront on AI training and feeding the model more data.
In this paper Google gets better model performance at ~half the inference compute load by spending ~50% more compute on ~4x the data.
ai.googleblog.com/2021/12/more-e…