随着对人工智能推理的需求呈爆炸式增长,我对我的小型计算机的要求也会越来越高。
还有多少?
过去五周,我一直在使用本地模型,看看在不使用云端数万亿参数模型的情况下,我的日常工作能完成多少。答案是:一半。
| 类别 | 数数 | 占总数的百分比 | 例子 |
|---|---|---|---|
| 其他 | 521 | 35.3% | 涵盖所有非结构化请求 |
| 日程安排 | 254 | 17.2% | 查询空档时间,提出会议时间建议 |
| 市场调研 | 192 | 13.0% | 竞争对手分析、筹款数据 |
| 总结 | 184 | 12.4% | 文字稿审阅,视频摘要 |
| 电子邮件和入站信息 | 170 | 11.5% | 草拟回复、后续跟进、转发 |
| 工程 | 147 | 9.9% | 调试脚本、API修复、CLI任务 |
| 行政 | 10 | 0.7% | 差旅费、开支、报销 |
如果将这 1400 个任务按类别划分,其中一半可以在本地 35B 模式下完成。电子邮件和入站、日程安排、摘要和管理共计 618 个任务(占 41.8%)。市场调研和工程任务大致分为简单任务(数据查找、脚本修复)和复杂任务(多源数据整合、架构决策)各占一半,占比 50%。
使用本地化模型有很多原因:隐私、成本、资产折旧。
但实际上,真正重要的只有延迟。
今天早上我做了一个对比基准测试。八个智能体任务,相同的提示,两个模型都已预热。测试模型分别是运行在我 MacBook Pro M5 上的 Qwen 3.6 35B-A3B-4bit 和通过 API 运行的 Claude Opus 4.5。
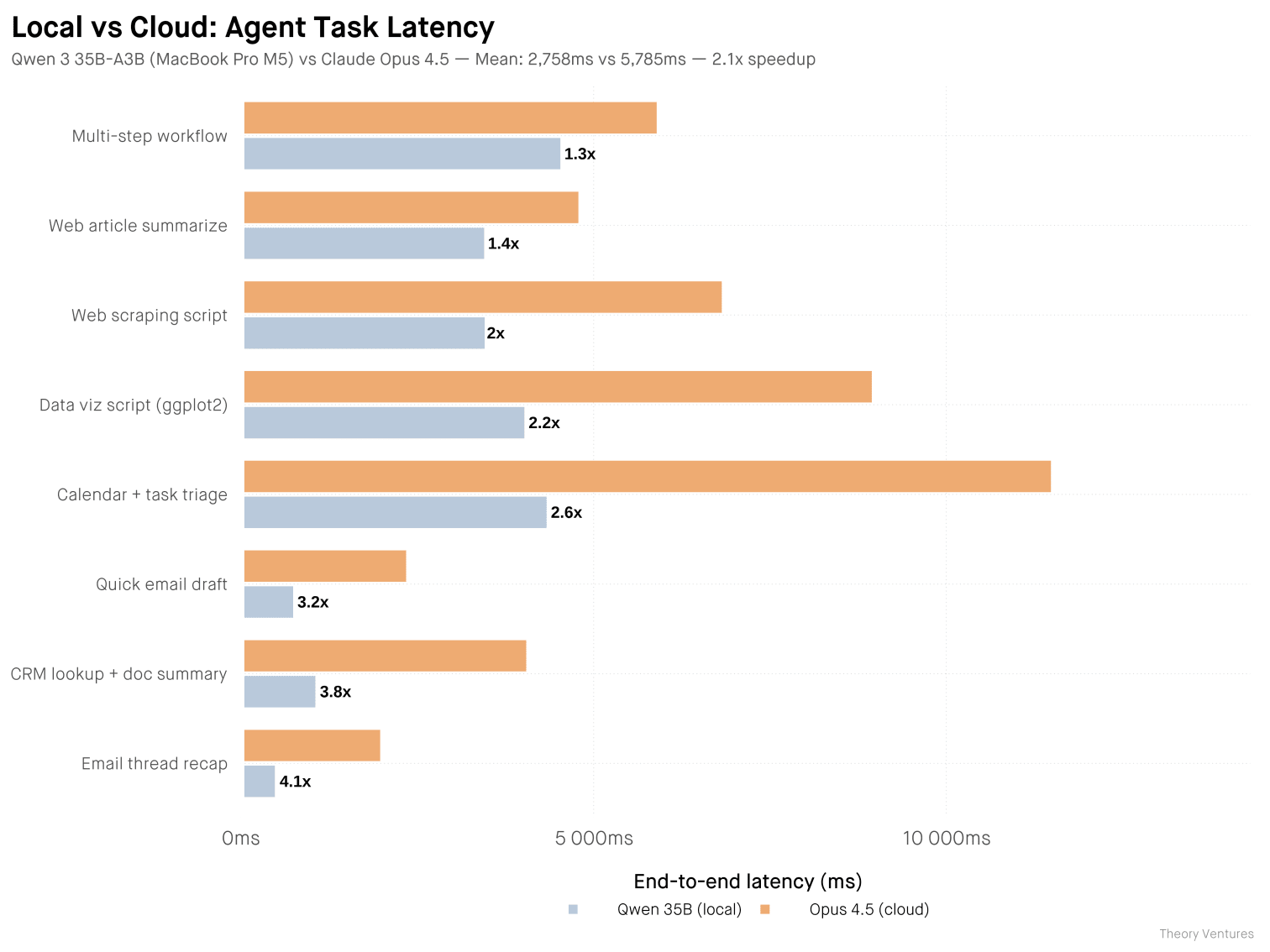
本地模型并不更智能。Opus 4.5 在推理基准测试中的得分仅比本地模型高出约 20%。本地模型比前沿模型落后 3-4 个月,对于大规模复杂任务而言,这种差距至关重要。但对于常规智能体任务而言,这种差距通常无关紧要。
Opus 在结构和润色方面胜出:要点式语句、标题、更简洁的代码。Qwen 则在简洁性上更胜一筹,代码量通常只有 Opus 的一半。我对比阅读了两者的输出结果,发现它们都正确完成了任务。对于输出结果需要反馈到其他系统的代理任务而言,简洁性至关重要。
本地最大化(Localmaxxing),即将更多推理任务转移到本地模型,是应对词元最大化(tokenmaxxing)的必然选择。随着本地模型不断改进并缩小与前沿模型的差距,越来越多的用户会将工作负载转移到他们自己的硬件上。
如果一半的工作在我的笔记本电脑上运行速度能提高一倍,我每次都愿意这么做。我的小电脑终于要派上用场了。
-
无论你是否使用,MacBook Pro 都会贬值。运行本地推理程序可以从不断贬值的资产中提取计算值,以便在转售前评估其价值。