推理市场是全球增长最快的市场,而且正在分化。每种模态都在开发自己的推理技术栈。
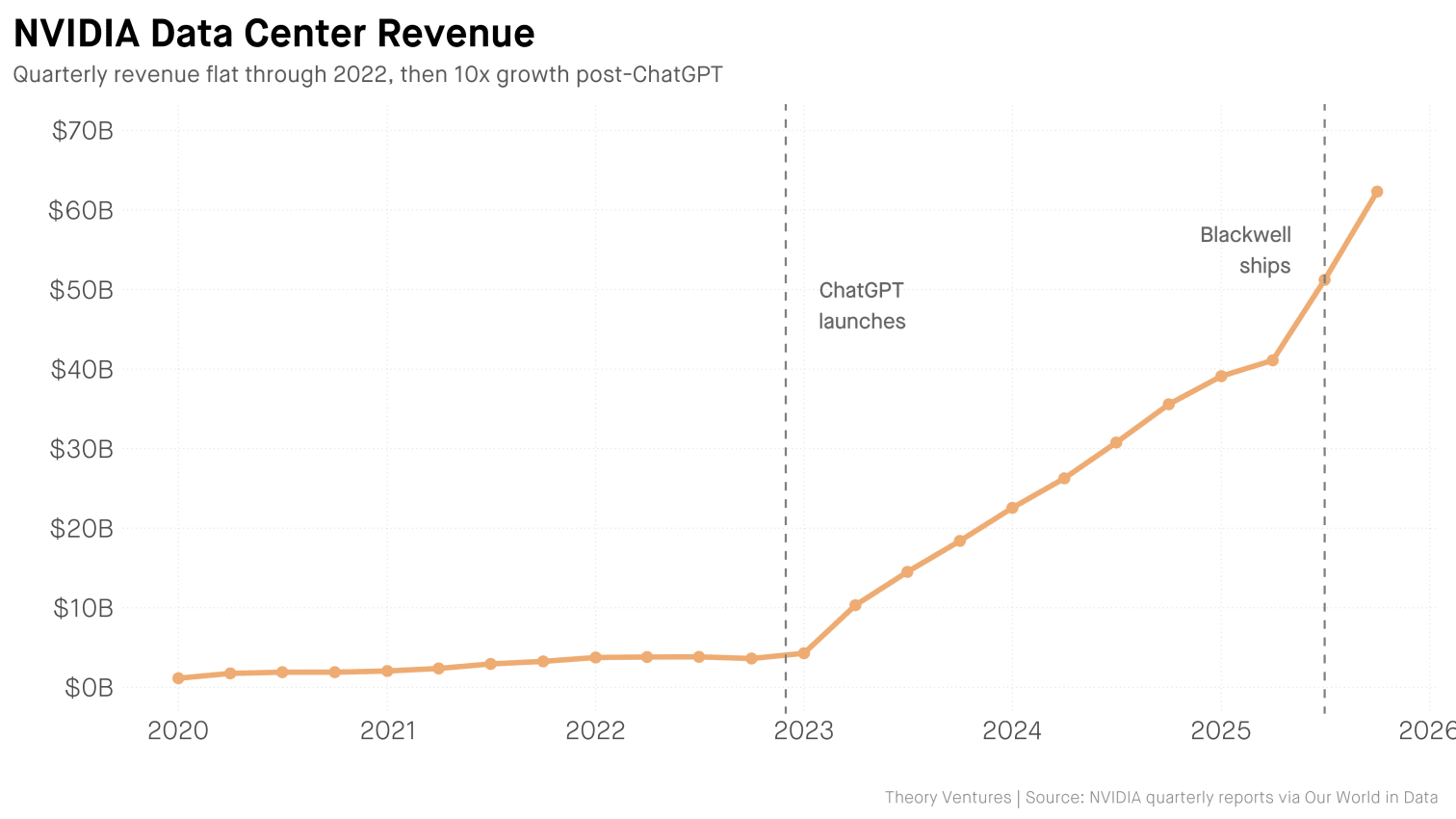
NVIDIA 的数据中心收入在 2022 年之前一直持平。然后 ChatGPT 上线了。三年后:增长了 17 倍。¹
数据库也经历了同样的演变。最初单一的数据库市场逐渐细分为关系型数据库、文档型数据库、键值型数据库、图数据库、时间序列数据库、向量数据库等等。每种类型都反映了不同的工作负载需求:实时事务处理与批量分析、ACID 合规性与最终一致性。
推理市场之所以呈现碎片化趋势,原因相同:工作负载各不相同。图像和视频处理需要大量的计算资源。更长的上下文窗口需要更大的键值缓存空间。边缘设备则受到功耗限制。单一架构无法针对所有这些需求进行优化。
模型生态系统也反映了这一点。在 Hugging Face 平台上,除了少数几个生命周期较长的主流低级模型 (LLM) 之外,还有超过 9 万个图像生成模型,而且每天都有新的变体出现。每种模型类型都有不同的服务需求,这导致基础设施分散。目前,我们看到以下几个细分领域:
延迟层级:实时、近实时和批量
延迟将服务划分为三个不同的部分。实时(低于 100 毫秒)服务于语音助手、实时翻译和自动驾驶汽车。用户不会等待,因此基础设施必须地理分布广泛,并配备专用容量。
近实时(100毫秒-2秒)涵盖聊天机器人、代码补全和搜索增强。目前大多数LLM应用都运行在这个速度范围内,通过批处理和排队来优化吞吐量,同时又不降低用户体验。
批量处理(耗时几秒到几小时)可大规模处理文档和内容生成。成本效益比速度更重要,因此工作负载会在非高峰时段使用竞价实例运行。
多模态(图像、视频、音频)
瓶颈在于信息处理能力。对于聊天机器人来说,问题在于内存。模型需要将整个对话存储在内存中,而且每次对话都会增加内存占用。对于图像和视频生成来说,问题在于原始计算能力。生成一张图像需要模型连续运行 50 次。不同的架构、不同的约束条件、不同的基础设施,都会导致不同的问题。
边缘计算(设备端和本地部署)
隐私要求、连接限制和对延迟的敏感性促使推理任务转移到边缘设备,例如移动电话、工业传感器和医疗设备。苹果在设备端运行一个包含 30 亿个参数的模型,用于 Apple Intelligence。特斯拉在 FSD 芯片上运行视觉模型,功耗为 72 瓦。量化模型、专用芯片和有限的内存带来了与云端推理不同的优化挑战。
数据库市场催生了Oracle、MongoDB、Databricks和Snowflake。一个价值1000亿美元的推理市场也以同样的方式碎片化,这为类似的赢家创造了空间。
-
拥抱脸部文字转图像模型– 截至 2026 年 4 月,已托管超过 90,000 个文字转图像模型。↩︎
-
Grand View Research:《2024年人工智能推理市场规模预计为972.4亿美元》 。
原文: https://www.tomtunguz.com/inference-market-segmentation/