各位亲爱的网友们,大家好!
在2025年超级计算大会上,EuroHPC、AMD和Eviden宣布,欧洲第二套百亿亿次级超级计算机系统将被命名为Alice Recoque。该系统采用Eviden的BullSequena XH3500平台,并使用AMD即将推出的Instinct MI430X作为其主要计算组件。Alice Recoque的HPL性能将“持续超过1 Exaflop/s……且耗电量低于15兆瓦”。
现在,AMD 还没有公布 MI430X 的 FLOPs 是多少,但可能已经有足够的信息让我们对 MI430X 的潜在 FP64 FLOPs 进行一番思考实验。
就我们目前所知:
– Alice Recoque 将由 94 个 XH3500 机架组成
– Alice Recoque 实际使用功率不足 15 兆瓦,但该设施可提供 24 兆瓦电力和 20 兆瓦制冷。
BullSequena XH3500 每机架最大功率为 264 千瓦
BullSequena XH3500 每机架 38U。
BullSequena XH3500 的滑架有两种规格:2U 用于交换机滑架和 8 个计算滑架,1U 用于 4 个计算滑架。
我们还知道,HPE 将单个 MI430X 的功耗标定在 2000 瓦到 2500 瓦之间。
Alice Recoque 有 3 种不同的能耗数值:
-
小于15兆瓦
-
该设施的热极限为20兆瓦冷却功率。
-
设施功率限制为24兆瓦
这样一来,XH3500机架就有了3种可能的配置方式:
-
对于功率低于 15 兆瓦的系统,需要 16 个计算节点,每个节点配备 1 个 Venice CPU 和 4 个 MI430X,以及 8 个交换机刀片。
-
对于这套 20 兆瓦的系统,包括 18 个计算节点,每个节点配备 1 个 Venice CPU 和 4 个 MI430X,以及 9 个交换机刀片。
-
该24兆瓦系统包含20个计算节点,每个节点配备1个Venice CPU和4个MI430X,以及8个交换机刀片。
本次计算中,我将采用中间配置,即每个机架包含 18 个计算节点和 9 个交换节点,并假设整套 Alice Recoque 超级计算机的最大持续能耗约为 20 兆瓦。这意味着单个 XH3500 机架的最大功耗约为 200 千瓦。因此,我假设每个计算节点的功耗约为 10.5 千瓦,由此估算出每个 MI430X 的 TDP 约为 2300 瓦。这样,计算刀片服务器的其余部分(包括 TDP 高达 600 瓦的 Venice CPU)的功耗约为 1300 瓦。
Alice Recoque 超级计算机拥有 94 个机架、18 个计算节点,每个刀片服务器配备 4 个 MI430X 处理器,总共 6768 个 GPU。假设 Alice Recoque 的 HPL Rmax 值指的是“持续性能超过 1 Exaflop/s 的 HPL 性能”,并且 Rmax 与 Rpeak 的比率约为 70%(与 Frontier 的比率类似),那么 Alice Recoque 的 HPL Rpeak 至少为 1.43 Exaflops。将 HPL Rpeak 值除以 MI430X 的数量,即可得出 MI430X 的 FP64 向量浮点运算性能约为 211 Teraflops。
MI430X 将约 211 Teraflops 的 FP64 向量运算能力与 432 GB 的 HBM4 显存相结合,使其拥有 19.6 TB/s 的内存带宽;不出所料,这与 MI450X 的内存子系统相同。高性能计算 (HPC) 的一个重要指标是给定内存带宽下的计算量,通常用每字节浮点运算次数 (FLOPs per Byte,简称 F/B) 表示。对于许多 HPC 任务而言,其运算强度较低,因此较低的 F/B 值更受欢迎,因为大多数 HPC 代码都受限于内存带宽。
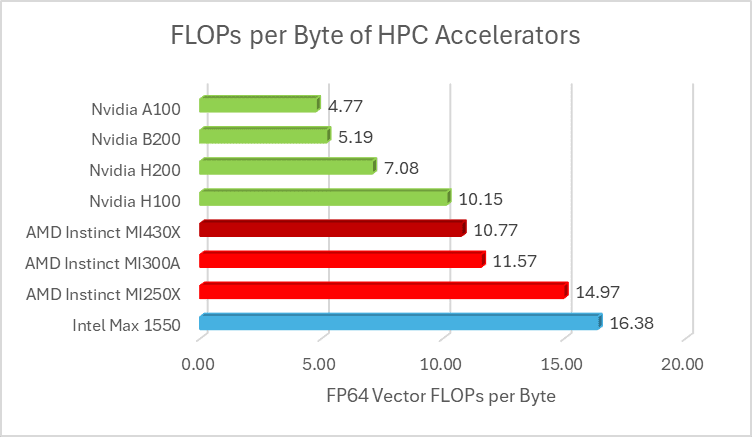
假设 MI430X 的 FP64 向量运算能力为 211TF,那么在每字节浮点运算次数 (FLOPs per Byte) 方面,MI430X 就超越了 AMD 此前两款专注于高性能计算 (HPC) 的加速器。然而,与英伟达的产品相比,MI430X 的 FP64 每字节浮点运算次数仍然更高。但与英伟达最新和即将推出的加速器相比,MI430X 还有两张王牌。
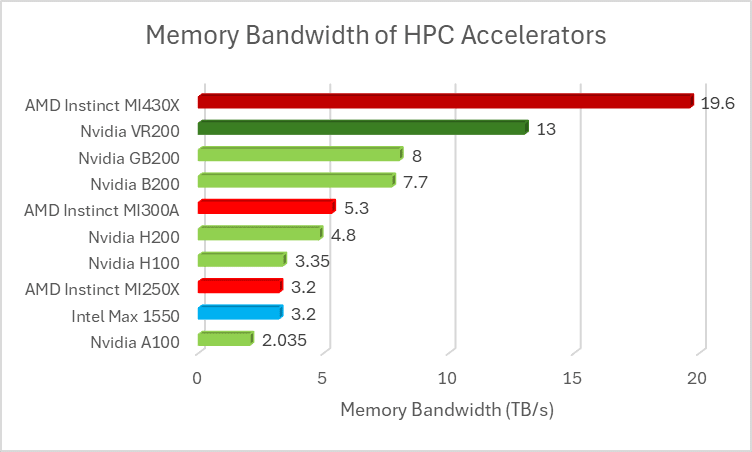
第一个优势是,MI430X 的带宽比 AMD 之前的产品要高得多,而且其内存带宽甚至比 Nvidia 即将推出的 Rubin 加速器还要高,这对于 HPC 中大量受限于内存带宽的任务来说非常重要。
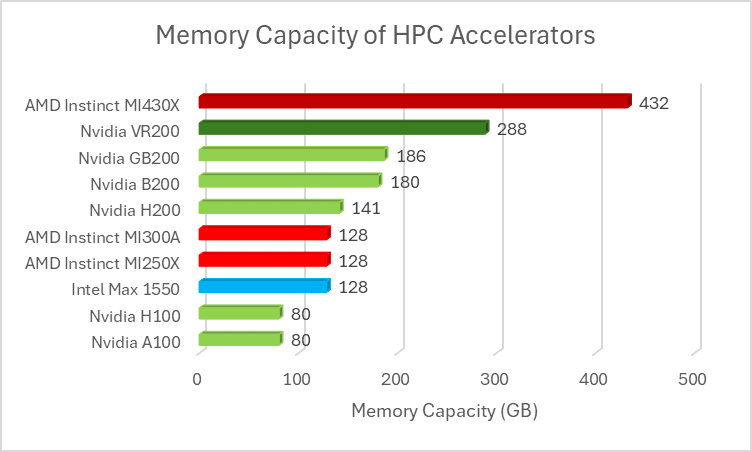
第二个优势是,MI430X 的 HBM 容量几乎是 AMD 先前加速器的 3.5 倍,比英伟达即将推出的 Rubin 的 HBM 容量高出 50%,这意味着单个 MI430X 可以容纳更大的数据集。
ORNL即将推出的Discovery超级计算机
在 2025 年超级计算大会召开前夕,AMD、HPE 和美国能源部宣布将替换 Frontier 超级计算机,代号为 Discovery,该计算机将于 2028 年交付,并于 2029 年在田纳西州橡树岭国家实验室启用。
除此之外,我们对 Discovery 了解甚少,只知道它将使用 HPE 的新型 GX5000 平台,并且将使用 AMD 的 Venice CPU 和 MI430X 加速器。
说到 HPE 的 GX5000 平台,它有 3 种初始计算刀片配置:
-
GX250:GX250刀片服务器配备8个Venice CPU,每个机架最多可容纳40个刀片服务器,因此每个GX5000机架最多可容纳320个Venice CPU。
-
GX350a:GX350a刀片服务器配备1个Venice CPU和4个MI430X加速器,每个机架最多可容纳28个刀片服务器,因此每个GX5000机架总共可容纳28个Venice CPU和112个MI430X加速器。
-
GX440n:GX440n刀片服务器每个刀片配备4个Nvidia Vera CPU和8个Rubin加速器,每个机架最多可容纳24个刀片服务器,因此每个GX5000机架总共配备96个Vera CPU和192个Rubin加速器。
目前的 GX5000 平台每个机架可提供高达 400 千瓦的功率,这很可能适用于完整的 GX440n 配置,其中 192 个 Rubin 处理器(每个额定功率 1800 瓦)本身就消耗约 350 千瓦的功率,更不用说 CPU、内存等其他组件的功耗了。GX5000 的占地面积也只有上一代 EX4000 的一半左右(1.08 平方米对比 2.055 平方米)。这意味着,一个 EX4000 机架的空间可以容纳两个 GX5000 机架。
对于 Discovery 来说,我们感兴趣的配置是 GX5000 的 GX350a 配置。目前尚未公布的是 HPL 加速目标,但预计 Discovery 在基准测试和科学应用方面的计算吞吐量将比 Frontier 高出三到五倍。
由于“性能提升三到五倍”的具体含义尚不明确,无论是指实际高性能计算工作负载下的速度提升三到五倍,还是指 LINPACK 测试中的速度提升三到五倍,我拟提出两种不同的 Discovery 配置:
-
这种配置方案能够适应 Frontier 大楼目前的电力和占地面积。
-
2024年8月30日,最终选定的配置方案性能约为当时Frontier Rpeak的4倍,约为1.714 Exaflops。
第一种配置方案中,Frontier 的计算系统使用了 74 个 EX4000 机架,这意味着该楼层空间大约可以容纳 140 个 GX5000 机架。这意味着 Discovery 将拥有总共 3,920 个 Venice CPU 和 15,680 个 MI430X 加速器,HPL Rpeak 的计算能力约为 3.3 Exaflops。
假设每个 GX5000 机架的功耗约为 250 千瓦,那么 3 Exaflops 的 Rpeak 性能将大致消耗 35 兆瓦的电力。虽然这比 Frontier 在 HPL 的功耗高出 10 兆瓦,但 Frontier 的办公楼设计容量可达 40 兆瓦,因此这 140 个机架的配置刚好符合 Frontier 办公楼的电力和占地面积要求。然而,如果将每个机架的功耗降低到 160 千瓦,那么 Discovery 就能轻松满足 Frontier 的电力需求。
对于第二种配置,我采用Discovery的最高速度预估值,即比Frontier快五倍,并采用大约是Frontier在2024年8月左右达到的Rpeak性能五倍的配置,这将使Discovery成为一个约8.5 Exaflop的系统。这将需要大约360个GX5000机架,总共需要10,080个Venice CPU和40,320个MI430X加速器。
这种配置可能需要对电力和机房空间进行升级才能容纳该系统。机房空间方面,这种配置可能需要超过 1600 平方米。电力方面,假设每个 GX5000 机架的功率为 250 千瓦,则这种配置的总功耗将超过 90 兆瓦;但是,如果将每个机架的功率降低到 160 千瓦左右,则 Discovery 的总功耗将控制在 55 至 60 兆瓦之间。
Discovery 最可能的配置可能介于这两种配置之间。然而,有传言称中国可能拥有一台超级计算机,其 HPL Rmax 运算速度超过 2 Exaflops,功耗为 300 兆瓦;此外,还有一台潜在的配套计算机,功耗为前者的 2.5 倍,达到 800 兆瓦,运算速度可能超过 5 Exaflops。因此,这或许会促使美国能源部选择最大的配置,甚至可能是 Frontier 五倍以上的配置。
无论 Discovery 最终的配置如何,对于高性能计算领域来说,这无疑是一个激动人心的时刻!
如果你喜欢这些内容,可以考虑前往Patreon或PayPal为 Chips and Cheese 捐赠一些钱。也欢迎加入我们的 Discord 服务器。
原文: https://chipsandcheese.com/p/sc25-estimating-amds-upcoming-mi430xs