所有现代应用程序都需要处理事务。这些操作要么完全成功,要么完全失败。
在单体系统中,这个过程通常很简单。应用程序只需与一个数据库通信,所有业务操作所需的数据都存储在同一个地方。开发人员可以使用内置的数据库事务或自动管理事务的框架,以确保即使出现问题,系统也能保持一致性。
例如,当您进行在线支付时,应用程序可能会从您的账户中扣款并将交易记录在账簿中。这两个操作都在同一个数据库事务中完成。如果其中一个操作失败,数据库会自动回滚所有操作,确保不会遗留任何部分更新。这种行为符合 ACID 特性(原子性、一致性、隔离性和持久性),从而保证了结果的可靠性和可预测性。
然而,随着系统不断发展壮大,许多组织开始采用基于服务的架构或微服务架构。在这种架构中,一个业务流程通常涉及多个服务,每个服务都管理着自己的数据库。例如,一个电子商务系统可能包含订单、支付、物流和库存等独立服务。每个服务都拥有自己的数据存储并独立运行。
现在想象一下,一笔业务交易涉及所有这些服务。下单可能需要更新订单数据库、在库存数据库中预留库存,以及在另一个数据库中记录付款详情。如果其中任何一个步骤失败,系统必须找到一种方法来保持所有服务的一致性。问题就出在这里。
请看下图:
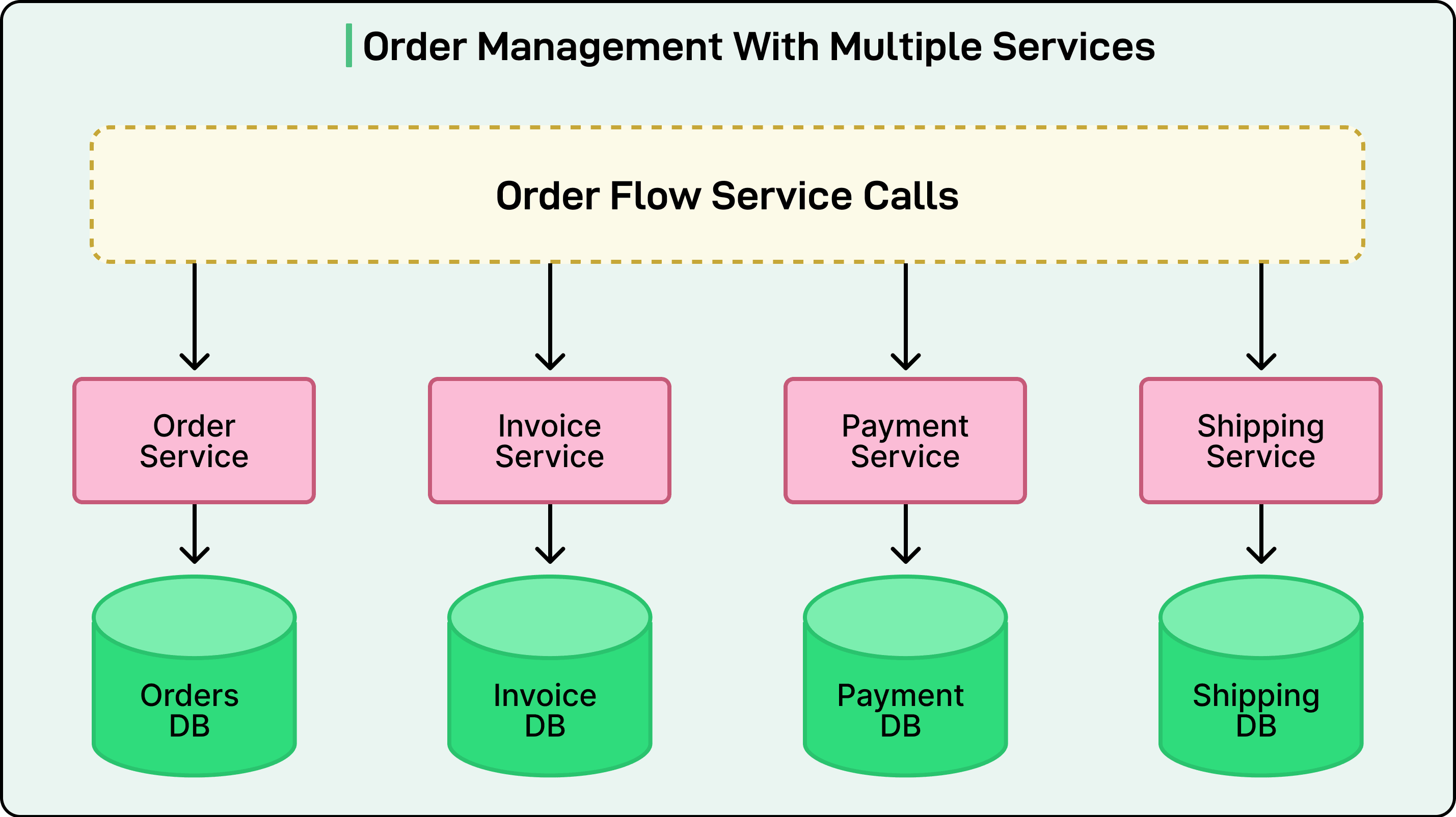
这种挑战被称为分布式事务问题。传统的两阶段提交(2PC)等技术试图协调多个数据库之间的提交操作,但它们会降低性能、限制可用性并显著增加复杂性。随着应用程序变得越来越分布式,并使用不同类型的数据库或消息代理,这些传统方法的实用性逐渐降低。
为了克服这些局限性,现代架构依赖于一些替代模式,这些模式能够在不引入严格耦合或阻塞行为的情况下保持一致性。其中最有效的模式之一就是 Saga 模式。
在本文中,我们将探讨 Saga 模式的工作原理,以及实现该模式的各种方法的优缺点。
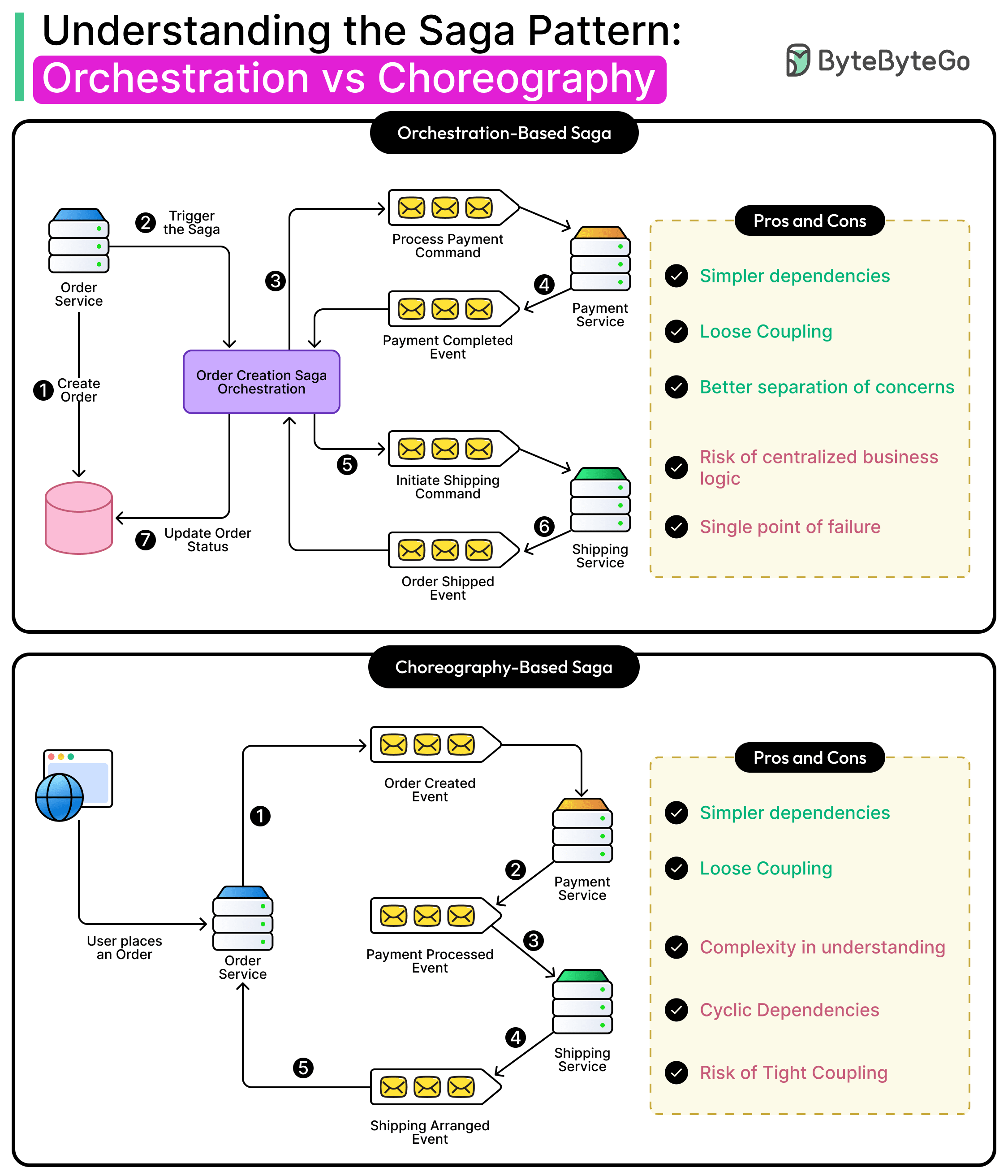
理解萨迦模式
原文: https://blog.bytebytego.com/p/saga-pattern-demystified-orchestration