大约两年半前,谷歌遭遇了GPT技术的浪潮。桑达尔·皮查伊或许(也或许没有)宣布了“红色警报”。本周,人们不再用言语来描述,而是用实际行动来解释垂直整合的原理。

当大质量物体扭曲时空时,较小的物体要么会被引力阱捕获,要么达到逃逸速度。谷歌正在人工智能领域投入巨资:930亿美元的资本支出、定制芯片、从上到下的垂直整合,再加上谷歌DeepMind研究团队的突破性进展。
这是否意味着竞争对手的游戏结束了?只有当智能被视为一个单一的整体,一个维度,其中最大的模型总是获胜时,游戏才会结束。但这种“上帝模型”谬误,即智能是单一整体的观点,与我的直觉相悖,正如我之前所写。最近的研究表明……他赞同这一观点,认为智能是多方面的。如果真是如此,谷歌的引力井有底限而无顶限。仅仅依靠质量匹配很难逃脱。逃脱需要在其他维度达到不同的密度。
请记住这个框架,我们来看看谷歌本周刚刚发布了哪些产品。
发射内部
本周,谷歌发布了新款旗舰级机器学习机器人 Gemini 3,它包含一项名为 DeepThink 的高级思维功能。与此次发布同时推出的还有一款名为 Nano Banana 3 的全新图像生成器以及一些开发者工具。
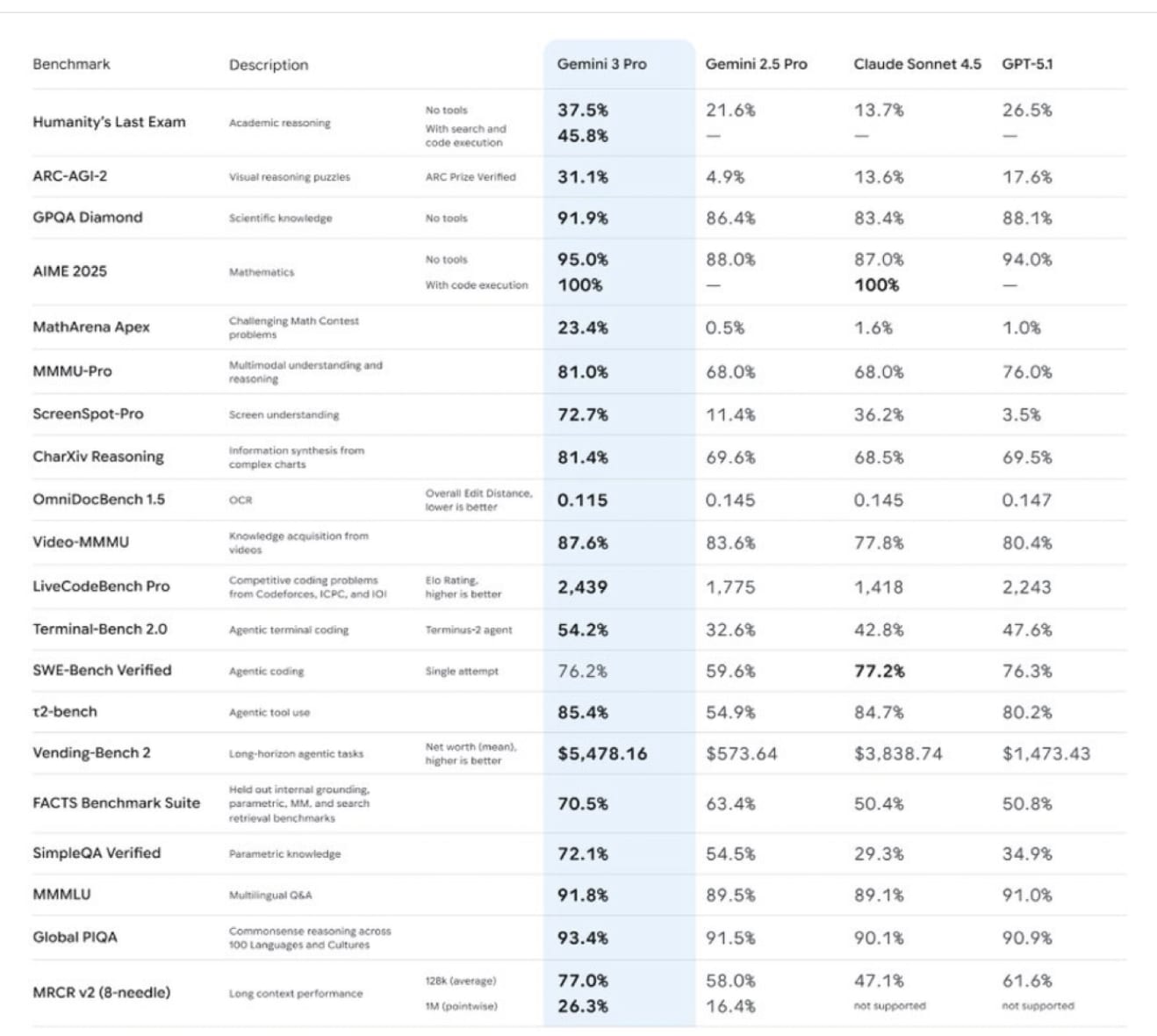
在Gemini 3本周正式发布前,我按照惯例对其进行了一系列测试。它相比Gemini 2.5有了显著提升——推理能力更强,处理复杂理论问题的能力也大幅提高。此外,它的表达也更加简洁明了。
与 GPT-5 相比,差异很快就显现出来。GPT-5 倾向于堆砌复杂的层层信息;而 Gemini 3 则直奔主题。这种清晰度在数百次查询中不断累积。现在,我大约三分之一的提示都默认使用 Gemini 3。我还将一个高风险的多智能体“长老会”工作流程从 GPT-5 迁移到了 Gemini 3,在这个工作流程中,多个不同的提示会对分析结果提出质疑和批评。在这个工作流程中,GPT-5 的表现明显优于 Claude 4.5;而 Gemini 3 Pro 则是其中最佳选择。
选择模型并非为了追求新奇。你是在重新调整一位你每天咨询数十次的同事的思路。对于那些需要具体数据的人来说,Gemini 3 Pro 在众多基准测试中都优于 Anthropologie 和 OpenAI。
如果我们只关注Alphabet的技术里程碑,就会忽略其全貌。真正默默无闻的功臣是该公司强大的基础设施。
市场对人工智能领域的支出和泡沫的担忧感到不安。这是“指数级缺口”带来的紧张局势,线性融资被指数级增长的技术所拖累。就连桑达尔·皮查伊也指出其中存在一些“非理性”因素。
Alphabet今年三次上调了资本支出预期。该公司目前预计2025年的资本支出将达到910亿至930亿美元,高于2024年的约525亿美元,并且已经暗示2026年将再次“大幅增长”。
迄今为止,这笔巨额支出并未迫使Alphabet放弃其对投资者的优厚财务待遇。该公司已批准在2025年进行700亿美元的股票回购,并在2024年斥资约620亿美元用于股票回购,70亿美元用于分红,目前仍保持着每季度约100亿至120亿美元的股票回购,同时支付每股0.21美元的季度股息。
绝大部分资本支出都投入到了技术基础设施,包括服务器、定制张量处理单元以及承载它们的数据中心和网络。最近的几轮融资主要用于向新型 Ironwood TPU 以及连接它们的 AI 超级计算机架构过渡。英伟达仍将分得一杯羹。谷歌云持续推出高端 Hopper 和 Blackwell 系列 GPU 实例,而 Gemini 和 Gemma 系列显卡也正在针对英伟达硬件进行优化,以满足有需要的客户的需求。
但Gemini的核心技术栈——包括训练和谷歌自家的第一方服务——现在几乎完全运行在谷歌自主研发的TPU上。这些Ironwood TPU性能卓越,堪比英伟达的Blackwell B200芯片,提供类似的原始处理能力(Ironwood的FP8浮点运算能力为42 exaFLOPs),并配备相同的192GB HBM3e显存。但谷歌的芯片只需擅长一件事:构建“谷歌式”的内部模型,即采用混合专家推理的大规模LLM模型,以实现高吞吐量服务。因此,Ironwood有望降低谷歌服务的单令牌成本和延迟。
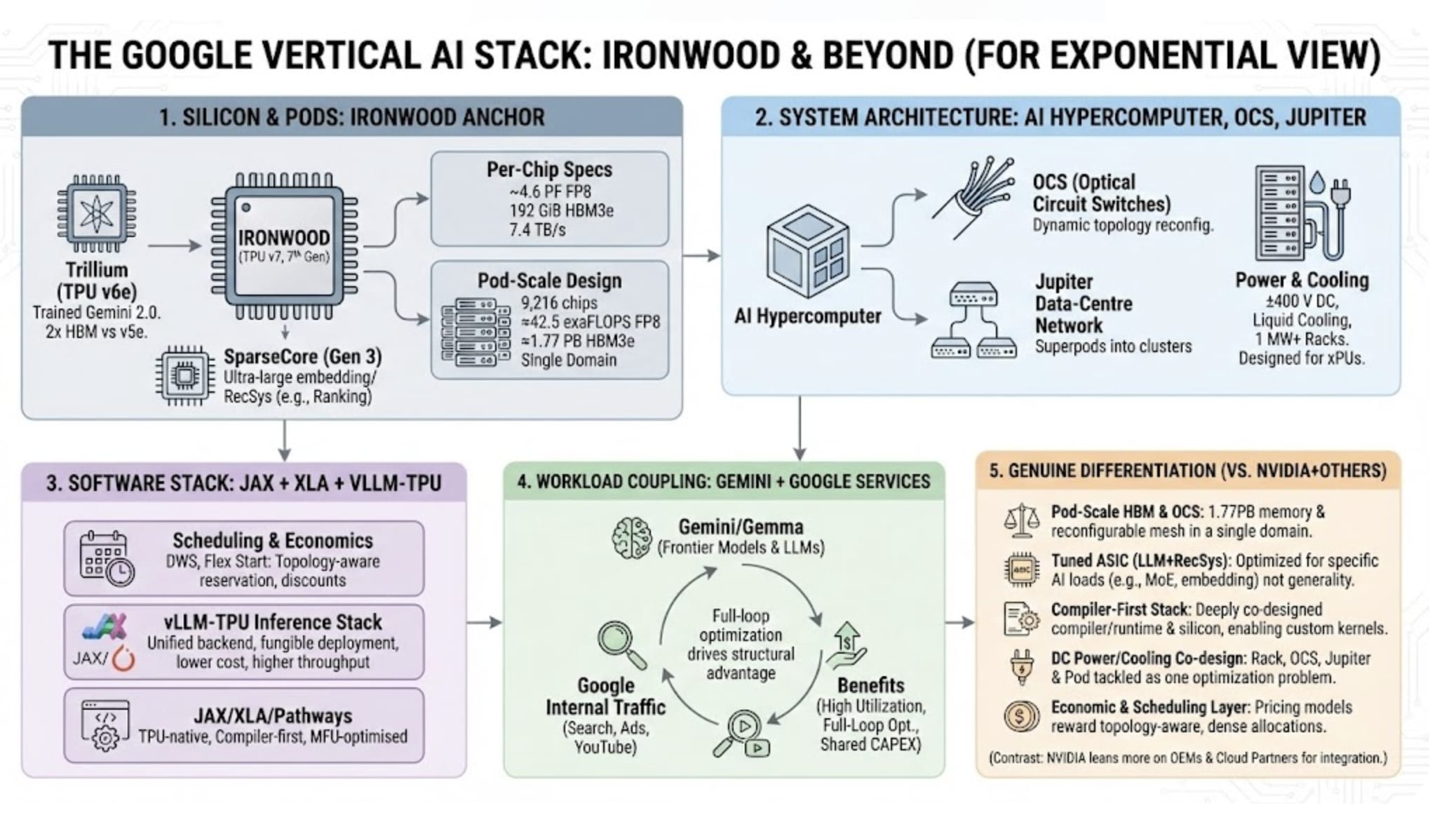
Gemini 3 就是这笔投资的回报。
至关重要的是,新模型还回应了该领域一直以来受到的批评。过去几年,基础模型实验室一直押注于扩展性定律,该定律指出,增加数据和计算投入能够可靠地提升性能。许多外部评论员声称,扩展性本身已经失败。我去年的观点是,虽然其他创新值得欢迎,但扩展性仍需数年时间才能真正发挥作用。
用谷歌研究员奥里奥尔·维尼亚尔斯(Oriol Vinyals)的话来说,关于预训练扩展:
与普遍认为扩展性已经过时的观点相反,团队实现了巨大的飞跃。[Gemini] 2.5 和 3.0 之间的差距是我们前所未见的。扩展性瓶颈似乎已经消失!
至于训练后阶段,也就是对已训练模型进行进一步优化的步骤,Vinyal 的描述更加明确:
这仍然是一片全新的领域。算法发展和改进的空间还很大,3.0 版本也不例外。
谷歌已经证明,只要拥有能够支撑资源消耗的垂直整合架构(基础设施、数据、研究人员),规模化依然有效。Anthropologie 或 OpenAI 能在多大程度上效仿这种策略?
智能的形态
要了解谷歌的引力井是否可以逃脱,我们需要首先了解是什么样的质量产生了人工智能的引力。他认为,智能并非铁板一块;它是由一般推理能力和通过针对性数据和训练而形成的独特、来之不易的能力组成的综合体。在实践中,这种广泛的推理能力就像谷歌的弥散引力质量一样,改变了竞争格局¹ 。
但还有第二类应急能力,即一些具有领域特定性的技能,例如高级编程、法律取证或蛋白质组学分析,这些技能并非自然而然就能获得。它们需要对特定数据和培训进行有计划且昂贵的投资。可以把它们理解为特定能力维度上的集中密度。
这彻底改变了逃逸动力学的本质。在经典引力体系中,你不可能逃脱质量更大的物体,这是绝对的。但在复合系统中,即使总质量远小于主导粒子,你也可以在特定维度上实现局部密度超过主导粒子的密度。
顾客在选择时,问的不是“哪个产品的总质量更大?”,而是“哪个产品在我关心的维度上的密度最高?”
这是未来五年的关键。如果各项能力是异构且正交的,你就无法构建一个能够同时最大化所有维度的“上帝模型”——即使是谷歌也面临资源限制。
规模创造数量,专业化创造密度。选择一项核心能力,全力投入,在这个领域凭借性价比取胜。这样就能摆脱谷歌的引力——不会有正面交锋。
为什么谷歌拥有“足够好”的理念
谷歌同时掌控着三个方面: (1)研究实验室的人才密度可与 OpenAI 相媲美;(2)基础设施投资每年接近 930 亿美元;以及——最关键的是——(3)任何初创公司都无法复制的分销渠道。

最后一个因素,即分发渠道,正变得至关重要。人工智能概览每月出现在20亿搜索用户面前,这意味着Gemini一天内触达的用户数量超过了大多数竞争对手一年的触达量。其助手已拥有6.5亿月活跃用户,仅次于ChatGPT。Gemini无需赢得每一项任务;它只需达到“足够好”的标准,融入人们已经使用的产品即可。
原文: https://www.exponentialview.co/p/can-ai-escape-googles-gravity-well