好吧,现在使用人工智能的人越来越多,人们也在尝试探索人工智能的用途。人们可能会认为这两者是相辅相成的,但很可惜。世界上大约有10%的人已经在使用人工智能了。几乎每家公司都有人在使用它。电话会议上,人们几乎都能谈论它。现在你几乎找不到一封电子邮件或一份文档不是用ChatGPT编写的。好吧,考虑到这种情况,就有一个问题:这些模型有多好,对吧?我们用过的任何标准,无论是数学运算能力、文字题能力、逻辑谜题能力,还是网上买机票、查演唱会门票的能力,它都胜任所有这些任务,甚至更多。
那么,考虑到这一点,有什么问题,有什么好方法可以弄清楚它们最终能做什么呢?其中一个模型实际上表现得相当不错,可以绘制成某种曲线,这样就不会受到“应试教育”问题的影响。
答案之一就是,你可以看看它预测未来的效果如何,对吧?我的意思是,很多人都在谈论预测市场,以及应该听取那些真正擅长预测市场的人的意见。我想,按理说,我们应该能够用大型语言模型做同样的事情。
因此,显而易见的下一步就是测试它,尝试获取大量新闻,然后询问模型接下来会发生什么。我就是这么做的。我称之为“预见熔炉”,因为这是模型为自己取的名字。(它使用 GPT-5 发布每日预测,以前是 o3 1。 )我想让它做所有的决定,从选择来源到预测,再到事后用概率进行排序,以及定期进行事后分析。
就像一个完全自动化的研究引擎。

这项工作进展顺利,因为它给出了一些有趣的预测,而且我真的很享受阅读它们。它很有洞察力!虽然有点偏向积极的结果。总之,它仍然很有用,并且预示着未来的发展。
但我一直在问自己一个更大的问题:这究竟能告诉我们人工智能预测下一步的能力吗?毕竟,观察预测只是评估的一部分,理解、学习或评分预测则不是。
我们与众不同的关键在于我们能够不断学习。比如,如果一位交易员的预测能力越来越强,那么他/她之所以能够做到这一点,是因为他/她能够回顾自己之前做过的事情,并以此为跳板,不断学习其他东西,如此循环往复。这是一个不断进步的过程,并非完美无缺。甚至也不是说你连续预测一两个月,然后综合运用这些经验,就能让自己变得更聪明,或者瞬间变得更优秀。学习是一个持续的过程。
所有主流人工智能实验室都在讨论持续学习,他们希望实现持续学习。他们希望能够实时看到模型不断改进,这虽然相当复杂,但这就是目标,因为这就是人类学习的方式。
关于训练,我稍微补充一下。我对强化学习(或许是所有模型训练)最大的想法之一就是,它本质上是在试图寻找进化的变通方法,因为我们无法重现实际自然环境的复杂性。但自然环境的创造极其困难,因为它不仅需要不假思索地评判你的数学题是否正确,还需要与世界上所有其他复杂元素进行互动,而这些元素的无限多样性教会我们各种各样的东西。
所以我想,好吧,我们应该能够解决这个问题,因为你需要做的就是做和我们或模型训练完全相同的事情,但要定期进行。比如,每天你都能获得当天的头条新闻和一些文章,你可以让模型预测接下来会发生什么,并保持策略的执行。一旦模型预测到接下来会发生什么,第二天你就可以利用你掌握的信息来更新所有内容。
因为我想在笔记本电脑上运行整个程序(这是我个人的限制,这样我就不用每周在 GPU 上耗费数千美元了),所以我决定先从一个微型模型开始,看看能把它推到多远。你知道,用微型模型运行的有趣之处在于,它们能做的事情有限。我在 MLX 上使用了 Qwen/Qwen3-0.6B。
(瓦罗这个名字也是我选的。瓦罗是一位罗马博学者和作家,被广泛认为是古罗马最伟大的学者,所以这个名字似乎很合适。彼特拉克曾称他为继维吉尔和西塞罗之后的“罗马第三大光芒”。)
比如说,最好的方法是先做一堆预测,然后第二天回顾一下,看看你离这些预测有多近,并更新你的观点。这基本上就是一个奖励函数,如果你想进行强化学习的话。
但这样做有一个问题,那就是预测自己是否正确的方法非常有限。如果你愿意,你可以只使用某些类型的预测作为衡量标准,例如,你可以只使用金融市场预测,然后在第二天再检验你的预测是否准确。这感觉太局限了。毕竟,如果人们最终对世界有了更深入的了解,他们所做的预测类型就不仅限于明天早上英伟达的股价可能是多少。
更不用说这其中也有很多噪音。看看CNBC就知道了。你应该能够预测各种各样的事情,比如国会投票结果如何,企业对法规的反应如何,或者宏观经济对公告的反应如何。所以,虽然我根据你可能预测的事情类型划分了一些限制,但我希望让它保持开放。尤其是因为保持开放似乎是向规模较小的法学硕士(LLM)教授正确世界模型的最佳方式。
我认为检查答案的最佳方法是使用相同类型的法学硕士 (LLM) 来观察接下来发生的事情,然后看看是否接近答案。事后看来,我显然遇到了一个问题:小型模型不太擅长扮演法学硕士 (LLM) 的法官角色。它们错得太离谱了。我本可以使用更大的模型,但那感觉像是作弊(因为相比纯粹从环境中学习,小型模型可以更好地了解世界)。
所以我说好的,我可以先教它格式,然后我得想个其他方法,看看它的预测是否接近第二天发生的情况。我想用我在 RLNVR 论文中对Walter用过的方法,看看语义相似性是否真的能帮我们走得更远。显然,这是一把双刃剑,因为你可能在语义上相当接近,但实际上含义相反,或者只是低质量的2 。
但是,由于我们研究的是小型模型,而且目标是首先尝试弄清楚某种方法是否有效,所以我认为这或许是一个不错的起点。我们也确实这么做了。最难的部分是找到确切的奖励组合,让模型真正按照我的意愿行事,而不是为了追求最大化奖励而做一些奇怪的事情。比如,你不能让它列出要点,因为它会重复指令,所以为了教它思考和回应,你必须选择段落式思考。
长话短说,它确实有效(一如既往,大概3个)。我在这里想要回答的关键问题,基本上是,我们能否在一个模型上进行一个常规的强化学习实验,使其能够使用来自外部世界的稀疏噪声奖励,并能够持续更新,使其仍然能够相对良好地完成一项工作。虽然我选择了一种更难的方法——预测整个世界,但我非常惊讶地发现,即使是一个小型模型,也能学会更好地预测第二天的头条新闻。
我没想到会这样,因为没有逻辑理由相信微型模型仍然能够学习到足够的世界模型信息,从而做到这一点。可能是因为样本量太小,可能是因为噪音,也可能是因为其他十几种原因,导致这种现象无法完美复制。
但这不是重点。重点是,如果这种方法能像在微型模型上那样有效,那么这意味着,对于奖励更容易理解的大型模型,你或许也能很容易地在策略强化学习上做到这一点4 。
这是一个巨大的突破。因为这意味着,这个充满稀疏奖励的世界现在基本上可以用来让模型表现得更好。没有理由相信这只是一个孤立事件,就像RLNVR论文一样,没有理由相信它无法扩展到做更有趣的事情。
自从我做了这项工作之后,我了解到 AI IDE Cursor 也为他们的自动完成模型做了类似的事情。他们接收更强的奖励信号,根据人类是否接受它实际提出的建议,他们能够每隔几个小时更新策略并推出一个新模型。这意义非凡!
那么,如果 Cursor 能做到这一点,那么是什么阻碍了我们更频繁地使用它来解决各种问题呢?部分原因在于数据的可用性,但更重要的是创建一个足够有趣的奖励函数,让它能够学到一些东西,以及一些人工智能基础设施。
我打算把 Varro 环境贡献给 Prime Intelligence 强化学习中心,以防有人想玩,也可能把它做成代码库或论文。但看到这一点非常酷,即使是像预测第二天头条新闻这样模糊不清的事情,即使是对人类来说也极其困难,因为它本质上是一项对抗性任务,如果我们设法将任务转化为 LLM 能够理解、学习和爬坡的东西,我们就能取得长足进步。未来看起来就像电子游戏一样。
看看你是否能找出它是哪一天改变的
无论如何,我们的方法是创建一个简短的预测段落,包含五个要点:目标、方向 + 小幅度、紧凑的时间框架、命名的驱动因素以及具体的验证草图。这种风格为我们提供了一个可以计算的损失函数。每天:采集标题 → 每个标题生成 8 个候选 → 评分(结构 + 语义;稍后确定真实性)→ 通过 GSPO 更新策略。
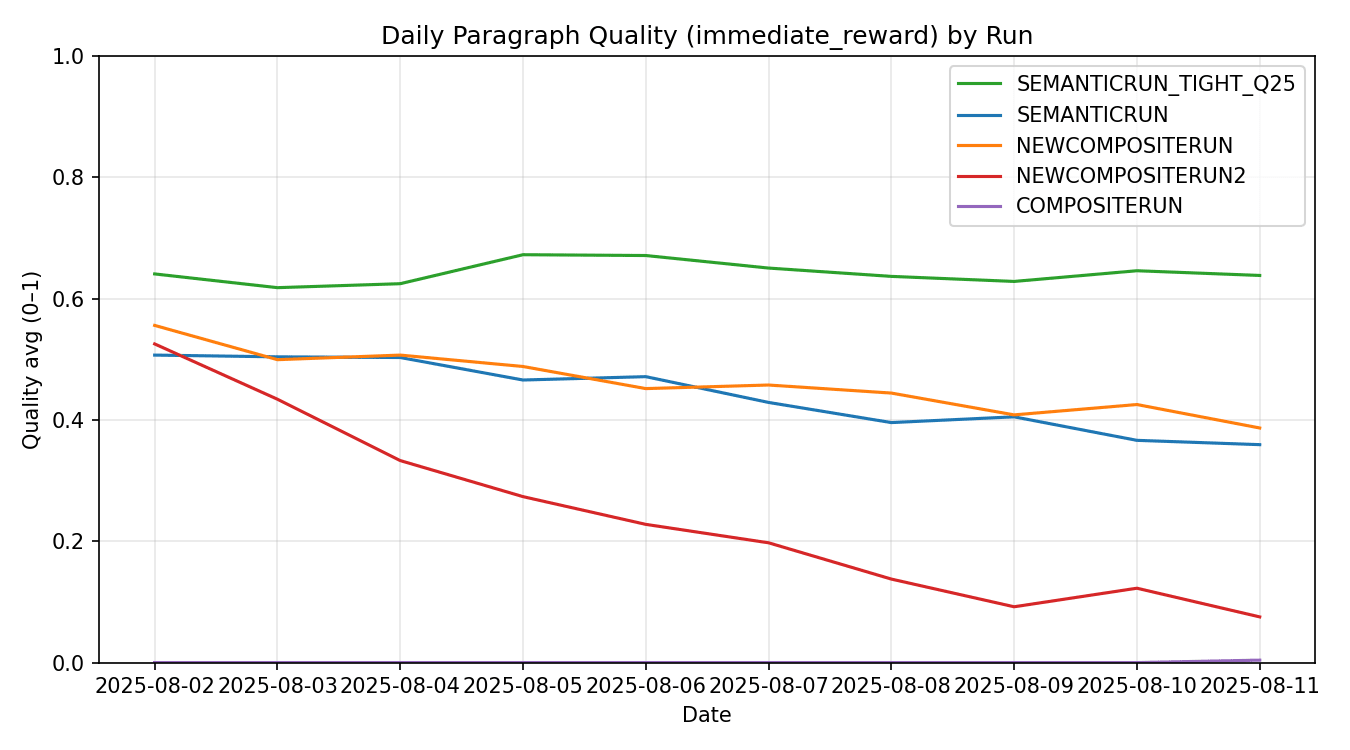
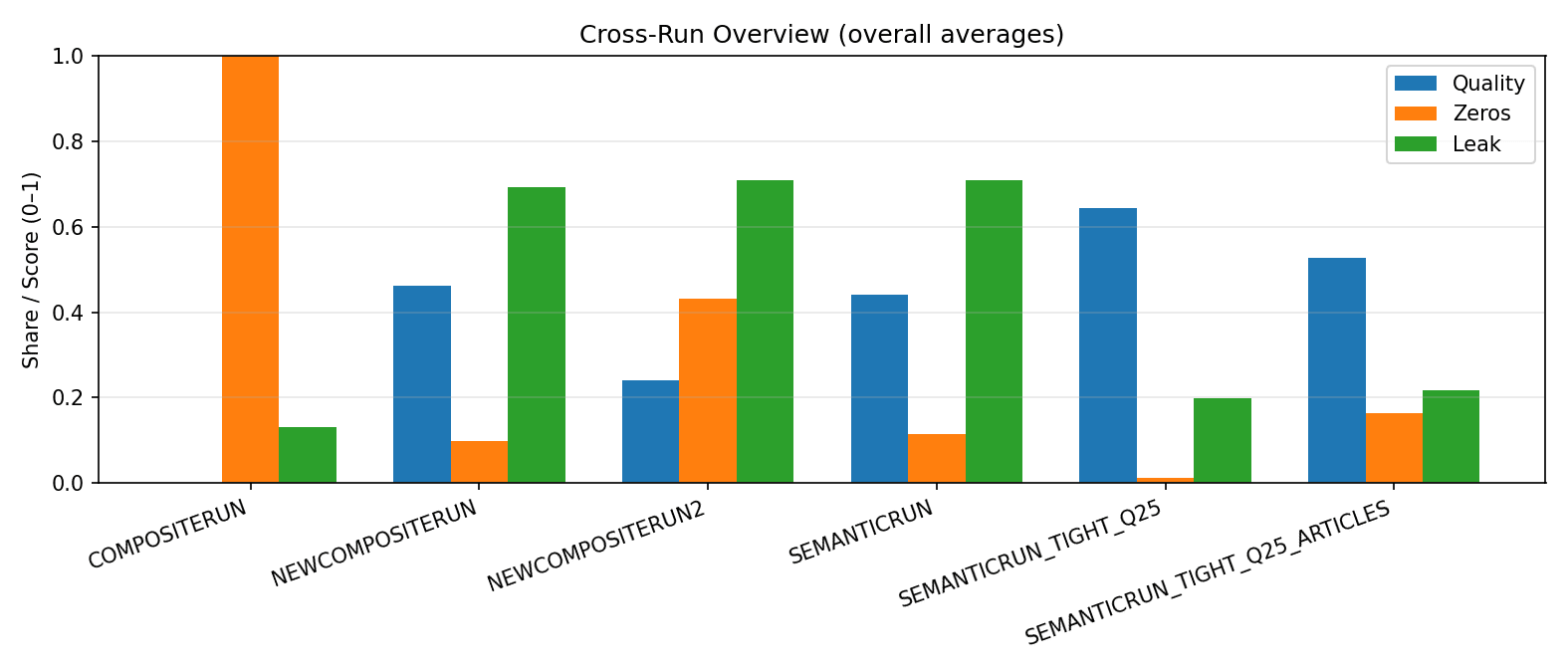
从运行结果来看,这些数字讲述了一个简单的故事。
-
COMPOSITERUN (单行模式):质量 0.000,零 1.000,泄漏 0.132,字数 28.9。模板缺乏学习。
-
NEWCOMPOSITERUN (段落,较松散):质量0.462,零分0.100,泄漏0.693,字数124.5。收益解锁,卫生状况恶化。
-
NEWCOMPOSITERUN2 (KL 极低):质量 0.242,零值 0.432,泄漏 0.708,字数 120.8。探索不足,表现不佳。
-
SEMANTICRUN (中等设置):质量 0.441,零点 0.116,泄漏 0.708,词汇量 123.8。稳定,但易产生回声。
-
SEMANTICRUN_TIGHT_Q25 (紧密解码 + Q≈0.25):质量 0.643,零值 0.013,泄漏 0.200,字数 129.2。最佳权衡。
每日节奏适中但清晰易懂。我在MLX上运行了一个小型Qwen-0.6B,并启用了GSPO,每个标题发布8次,通常每天发布约200-280次(例如,32×8、31×8)。紧凑运行训练了2136步,平均奖励约为0.044;在最佳的日子里,KL在7-9的范围内浮动,以获得最佳的探索稳定性。熵控制非常重要。工作秘诀:段落包含五个节拍;LLM=0;语义≈0.75;格式(Q)≈0.25;采样器=紧凑;约160-180个标记;3-5句正面提示;对齐评分器和检测器。如果出现漫无目的的内容,则将Q值推向0.30;如果输出过于笼统,则将Q值调低。
原文: https://www.strangeloopcanon.com/p/prediction-is-hard-especially-about