从本地文件夹在浏览器中加载 Llama-3.2 WebGPU
受到 Hacker News 上一条评论的启发,我决定看看是否可以修改transformers.js-examples/tree/main/llama-3.2-webgpu Llama 3.2 聊天演示(此处在线,我去年 11 月写过相关文章)以添加一个选项,直接从磁盘上的文件夹打开本地模型文件,而不是等待它通过网络下载。
我向 OpenAI 支持 GPT-5 的 Codex CLI 提出了这个问题,如下所示:
git clone https://github.com/huggingface/transformers.js-examples cd transformers.js-examples/llama-3.2-webgpu codex然后出现这个提示:git clone https://github.com/huggingface/transformers.js-examples cd transformers.js-examples/llama-3.2-webgpu codex
Modify this application such that it offers the user a file browse button for selecting their own local copy of the model file instead of loading it over the network. Provide a "download model" option too.
Codex 花了几分钟时间,甚至运行诸如curl -sL https://raw.githubusercontent.com/huggingface/transformers.js/main/src/models.js | sed -n '1,200p'之类的命令来检查底层 Transformers.js 库的源代码。
经过总共四次提示( 如图所示)后,它构建了一些可以工作的东西!
要试用,您需要一个本地的 Llama 3.2 ONNX 模型副本。您可以像这样下载(大约 1.2GB):
git lfs install git clone https://huggingface.co/onnx-community/Llama-3.2-1B-Instruct-q4f16然后访问我的git lfs install git clone https://huggingface.co/onnx-community/Llama-3.2-1B-Instruct-q4f16
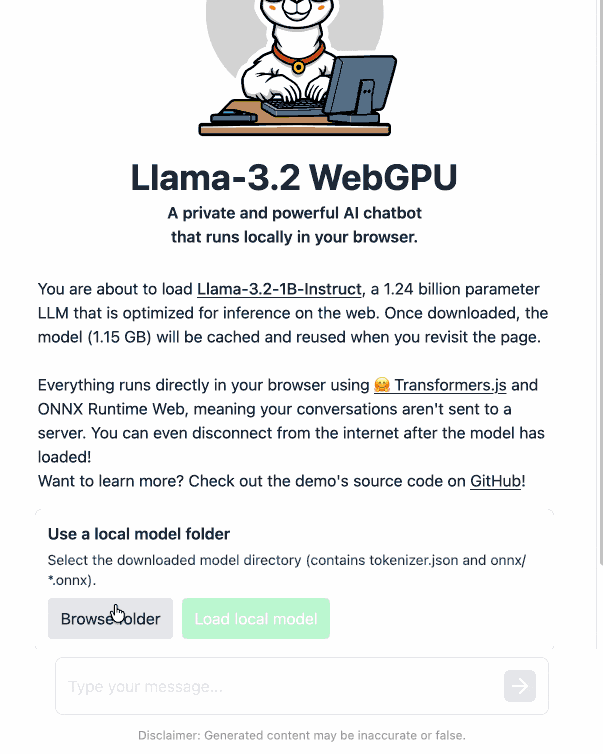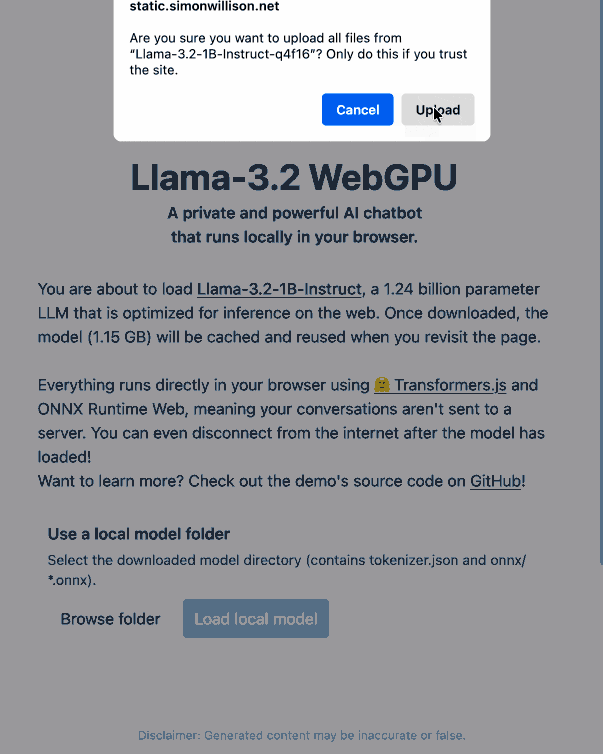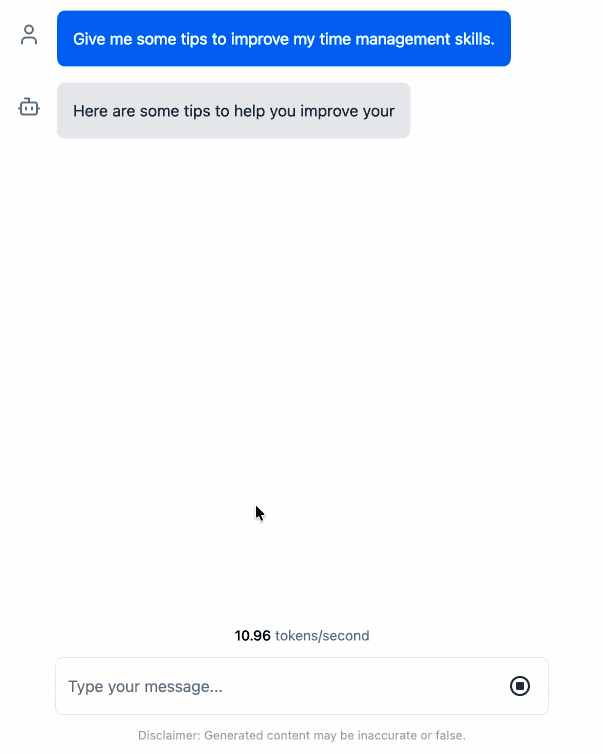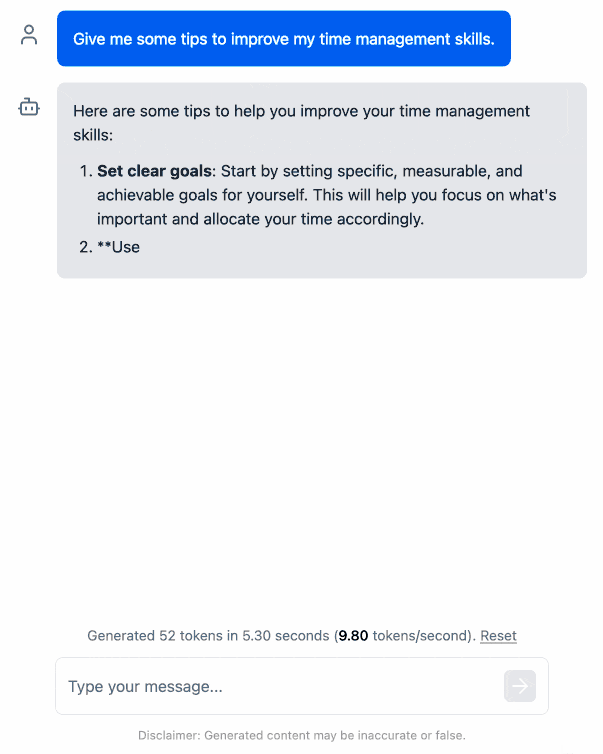
Chrome 或 Firefox Nightly 中的llama-3.2-webgpu页面(因为需要 WebGPU),单击“浏览文件夹”,选择刚刚克隆的文件夹,同意“上传”确认(令人困惑,因为没有从浏览器上传任何内容,模型文件在您的机器上本地打开)并单击“加载本地模型”。
这是一个动画演示。
我在这里推送了一个包含这些更改的分支。下一步是修改它,使其除了支持 Llama 3.2 演示版之外还能支持其他型号。不过,除了向 Codex 提几个问题看看它能否解决之外,我几乎不用费什么力气就完成了这个概念验证,这已经让我很开心了。
根据 Codex /status命令, 此操作使用了169,818 个输入令牌、17,112 个输出令牌和 1,176,320 个缓存输入令牌。按照当前 GPT-5 令牌价格(每百万个输入 1.25 美元、每百万个缓存输入 0.125 美元、每百万个输出 10 美元),这笔费用为 53.942 美分,但 Codex CLI 已绑定到我现有的每月 20 美元的 ChatGPT Plus 套餐中,因此这笔费用已捆绑到套餐中。
通过我的黑客新闻评论
标签: javascript 、 ai 、 generative-ai 、 llama 、 local-llms 、 llms 、 ai-assisted-programming 、 transformers-js 、 webgpu 、 llm-pricing 、 vibe-coding 、 gpt-5 、 codex-cli
原文: https://simonwillison.net/2025/Sep/8/webgpu-local-folder/#atom-everything