您好,欢迎阅读新一期的高级简报。感谢您一如既往的订阅,欢迎发送电子邮件至 [email protected] 与我联系。
正如我反复写道的,运行生成式人工智能的成本不合理。根据我能找到的每份报告,所有提供生成式人工智能服务的公司——除了像Turing和Surge这样提供训练数据和服务的公司——都在亏损,而且亏损的方式强烈表明,它们的利润率根本无法提高。
事实上,让我用一个例子来解释一下这一切有多么荒谬,我将在高级休息后重复这些观点。
Anysphere 是一家销售其 AI 编程应用 Cursor 订阅服务的公司,该应用主要使用 Anthropic 的计算资源,通过其模型 Claude Sonnet 4.1 和 Opus 4.1 进行计算。据 Newcomer 的 Tom Dotan 报道,Cursor 将其全部收入都交给了 Anthropic,Anthropic 随后将这些收入用于开发 Cursor 的竞争对手 Claude Code。Cursor 是 Anthropic 最大的客户。Cursor 的盈利能力极其低下,甚至在 Anthropic 选择增加“服务层级”并抬高 Cursor 等企业应用的价格之前,Cursor 就已经如此。
我的直觉是,这是一个全行业的问题。Perplexity 在 2024 年将其 164% 的收入花在了 AWS、Anthropic 和 OpenAI 上。更抽象一点(我稍后会讲到),OpenAI仅在推理计算成本上就花费了 50% 的收入,在训练计算上也花费了 75% 的收入(最终花费 90 亿美元,却损失了 50 亿美元)。没错,这些数字加起来超过了 100%,这就是我的观点。
大型语言模型过于昂贵,以至于任何资助“人工智能初创企业”的人实际上都是将钱发送给 Anthropic 或 OpenAI,然后后者又立即将钱发送给亚马逊、谷歌或微软,而这些公司尚未表明他们通过销售这些模型获得了任何利润。
请不要浪费口舌说“成本会下降”。成本还没有下降,而且也不会下降。
尽管绝对错误的支持者声称并非如此,但推理的成本(从输入提示到从模型生成输出时发生的一切)正在增加,部分原因是“推理”模型生成其输出所需的令牌密集型生成,并且推理是获得“更好”输出的唯一方法,它们将继续存在(并继续消耗大量令牌)。
这会带来非常非常现实的后果。《华尔街日报》的克里斯托弗·米姆斯(Christopher Mims) 上周报道称,软件公司 Notion(该公司提供的人工智能服务可以归结为“生成内容、搜索、会议记录和研究” )的人工智能成本吞噬了其 10% 的利润率,而其提供的服务却与其他人提供的服务一模一样。正如我一两个月前所讨论的那样,人工智能成本的不断上涨已经引发了一场次贷人工智能危机,Anthropic 和 OpenAI 不得不提高其模型的价格,同时还提高了企业客户的价格。
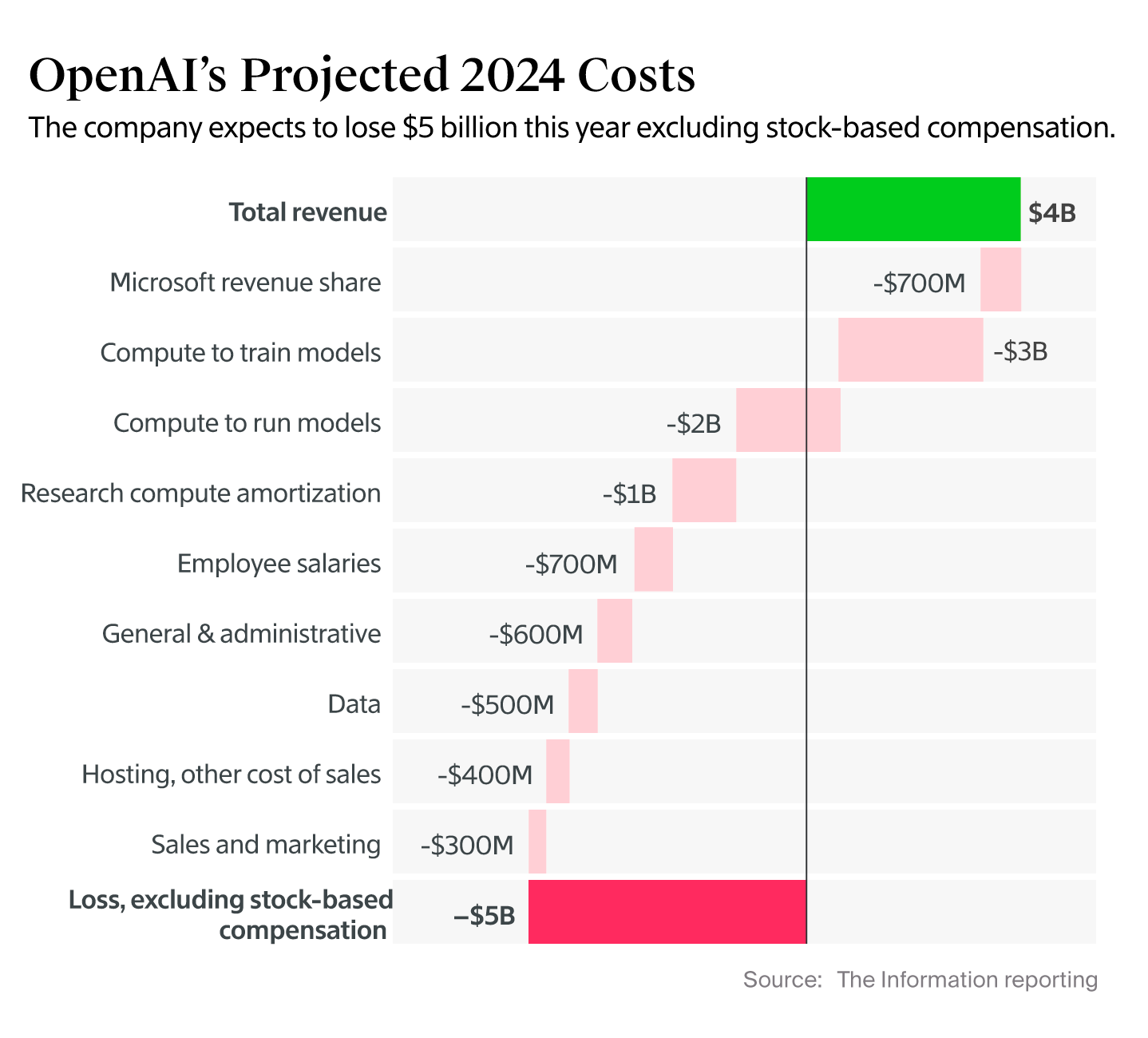
如前所述,2024 年OpenAI 亏损 50 亿美元, Anthropic 亏损 53 亿美元,OpenAI 预计亏损将超过 80 亿美元,而 Anthropic — — 不知何故 — — 到 2025 年仅亏损 30 亿美元。我非常怀疑这些数字是否真实, 因为仅今年一年,OpenAI 在工资上就至少烧掉 30 亿美元现金,而 Anthropic 的收入却少烧掉 20 亿美元,而如果你相信他们的泄密,自今年年初以来,收入增长了 500% 。虽然我不能肯定地说,但我预计 OpenAI 仅今年一年的计算成本就至少会达到 150 亿美元,如果烧掉 200 亿美元或更多,我也不会感到惊讶。
事到如今,尽管Sam Altman 最近声称OpenAI 盈利,但提供模型推理服务显然无利可图,这一点已变得愈发明显。他无疑是在玩弄毛利率这个概念——暗示只要不包括培训、员工、研发、销售和营销以及任何其他间接成本,推理服务就是“盈利”的。
无论如何,我们甚至没有一家——确切地说是一家——盈利的模型开发商,没有一家提供这些服务的公司没有出现数百万甚至数十亿美元的亏损。事实上,即使从 OpenAI 2024 年的收入中剔除模型训练成本( 数据来自 The Information ),OpenAI 仍然会亏损22 亿美元。
你们中有人会说:“哦,实际上,这是标准会计。” 如果是这样的话,OpenAI 在 2024 年的毛利率为 10%,而虽然 OpenAI 透露其 2025 年的毛利率为 48% , 但 Altman 还声称 GPT-5 让他害怕,并将其与曼哈顿计划相提并论。我不信任他。
生成式人工智能存在一个巨大的问题,大多数科技和商业媒体一直极力回避讨论:每家公司都无利可图,即使是那些提供模型的公司。多年来,记者们一直在回避这个问题,坚称“这些公司最终会找到解决办法”,却从未真正解释过他们将如何做到这一点,除了“推理成本会下降”或“新芯片会降低计算成本”之外。
这两件事都没有发生,现在是时候严肃审视大型语言模型时代腐败的经济学了。
包括 OpenAI 和 Anthropic 在内的生成式 AI 公司损失了数百万甚至数十亿美元,而基于这些模型构建的公司也面临同样的损失,部分原因是交付模型的成本持续上涨。将大型语言模型集成到产品中已经会让你损失惨重,而大型语言模型提供商(例如 OpenAI 和 Anthropic)的损失更是雪上加霜。
我认为,生成式人工智能从本质上来说是无利可图的,并且没有任何一家公司在 Anthropic 或 OpenAI 的模型上构建其核心服务,除了大规模、不切实际的价格上涨之外,能够实现盈利。
对于生成式人工智能公司来说,唯一现实的前进道路是开始向用户收取运行其服务的直接成本,但我不相信用户会热衷于这样做,因为平均每个用户花费的计算量远远超过公司每月从每个用户身上获得的收入。
正如我将要讨论的,我认为即使采用基于使用情况的定价,这些公司也不可能盈利,因为要使 LLM 编码等变得有用,所需的计算量远远超出了个人或企业能够支付的范围。
例如,一位 Cursor 用户发现,自己在几分钟内就花了近 4 美元来创建模型需要遵循的 Todo 文件。人工智能的支持者会辩称,这位用户“缺乏经验”或“使用了错误的模型”,但这些都是对大型语言模型固有问题的合理化解释——它们什么都“不知道”,它们并不“智能”,它们无法被信任高效甚至正确地执行任务,而人工智能模型的核心缺陷在于,它们唯一一致的用例就是让 Anthropic 或 OpenAI 亏损。
我还将探讨生成人工智能背后的经济学变得多么荒谬,公司将其 100% 或更多的收入直接发送给云计算或模型提供商。
我将解释为什么生成式人工智能从本质上来说与软件销售方式背道而驰,以及为什么我认为这从一开始就注定了它的失败。
原文: https://www.wheresyoured.at/why-everybody-is-losing-money-on-ai/