E-Core 是英特尔 CPU 战略的核心。其较小的面积占用有助于英特尔在较小的面积占用下实现高多线程性能。但 E-Core 的优势不仅仅在于数量,因为它们仍然具有显著的单核性能。Skymont 是英特尔最新 Arrow Lake 台式机平台的 E-Core,主频可达 4.6 GHz,每周期可执行 8 个微操作。对于游戏等对单线程性能敏感的工作负载,仍然受益于 Lion Cove 更高的时钟速度和更深的重新排序能力。尽管如此,Skymont 对游戏工作负载的处理仍然令人感兴趣,一方面是出于好奇,另一方面是因为它能够在各种游戏中提供可玩的性能。此处的测试使用英特尔 Arc B580 和 DDR5-6000 28-36-36-36 内存进行。

自上而下的分析通过查看重命名/分配阶段来解释核心宽度未得到充分利用的原因。它是流水线中最窄的阶段,这意味着在该阶段丢失的流水线槽会降低平均吞吐量。Skymont 经常受到后端限制,即重命名器有微操作需要发送到下游,但乱序的后端无法接收它们。Lion Cove 的情况类似,这并不奇怪,因为两个核心在 L2 之后共享一个内存子系统,而内存访问延迟经常导致后端限制损失。
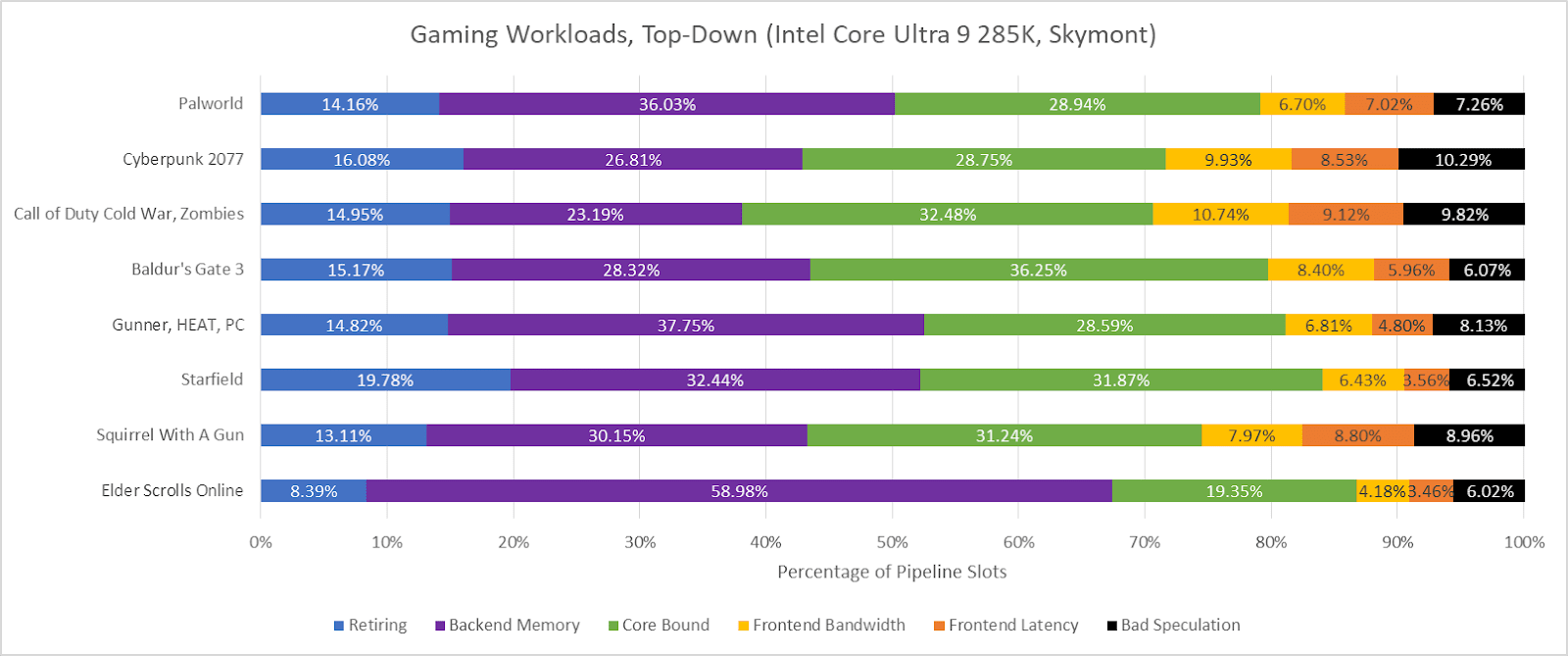
Skymont 没有事件或单元掩码来将后端绑定槽位分类为核心绑定槽位和内存绑定槽位。AMD 建议通过查看指令退出被负载阻塞的频率(相对于其他指令类型)来做到这一点。该方法可以在 Skymont 上粗略复制,它有一个事件,用于计算退出被负载阻塞时的周期数。设置 cmask=1 并反转退出槽位计数事件的位,可以提供退出停滞的总周期数。
很大一部分退出停顿是由内存负载引起的,但令人惊讶的是,也有相当一部分是由其他原因引起的。这种方法与 AMD 的方法有所不同,因为退出停顿可能由于指令不完整以外的其他原因而发生。例如,在代价高昂的错误预测或异常之后,ROB 可能为空。不过,这些“核心绑定”的槽位仍然值得仔细研究。
后端停顿和核心限制
资源不可用是后端无法接受传入微操作的最常见原因。由于微操作在长延迟微操作之前堆积,核心的重排序缓冲区、寄存器文件、内存排序队列和其他结构可能会被填满。第一个填满的结构会导致重命名器停止。Skymont 拥有一个包含 416 个条目的大型重排序缓冲区 (ROB),理论上,它可以保持与 Zen 5 (448) 和 Lion Cove (576) 等高性能核心几乎一样多的微操作。然而,Skymont 在其 ROB 填满之前经常会遇到其他限制。其主要分布式调度方案不如 Zen 5 更统一的方案。微基准测试表明,Zen 5 和 Skymont 在广泛的指令类别中具有相似的调度程序条目数,但对于相似的条目数,统一调度程序通常更高效。Zen 5 很少耗尽调度程序条目,并且更频繁地填充其 ROB,展现了这一优势。 Skymont 的寄存器文件和内存排序队列大小适中,很少出现性能限制。但资源停滞并非后端吞吐量损失的唯一原因。
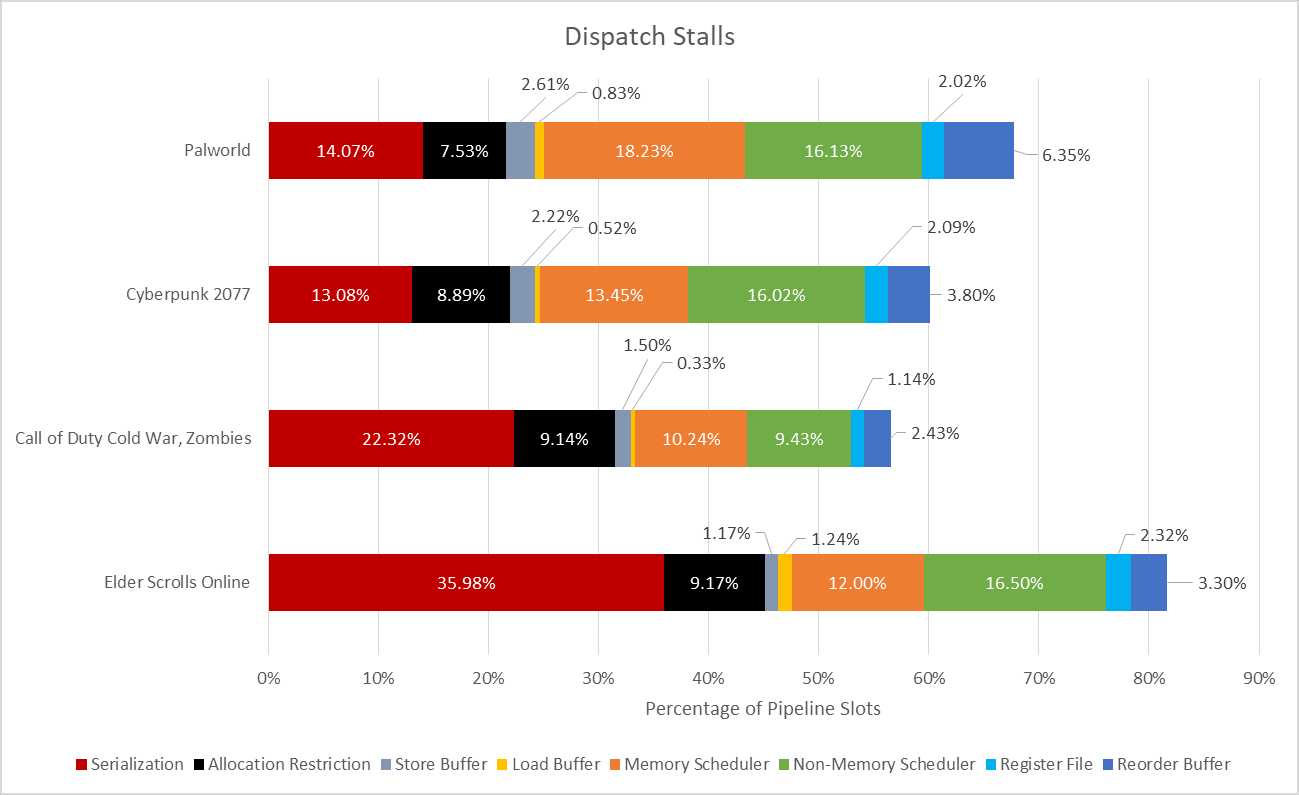
除了性能监控事件外,分配限制并没有直接记录。一种理论认为,分布式调度器对每个周期从重命名器接收的微操作数量有所限制。Arm 在其 Cortex X1 核心中明确记录了这些限制。Skymont 或许也有类似的限制。无论如何,这都不是大问题。取消分配限制可以让微操作更快地进入后端,但如果长延迟指令退出速度不够快,后端将不可避免地陷入资源停滞。

最后,“序列化”指的是核心无法重新排序超过某条指令的情况。我不确定这种情况在其他核心上发生的频率,但 Zen 5 的性能计数器确实将很大一部分后端停顿归因于其他原因。Skymont 可以将与序列化相关的停顿细分为几个子类别,以便进行更深入的分析。
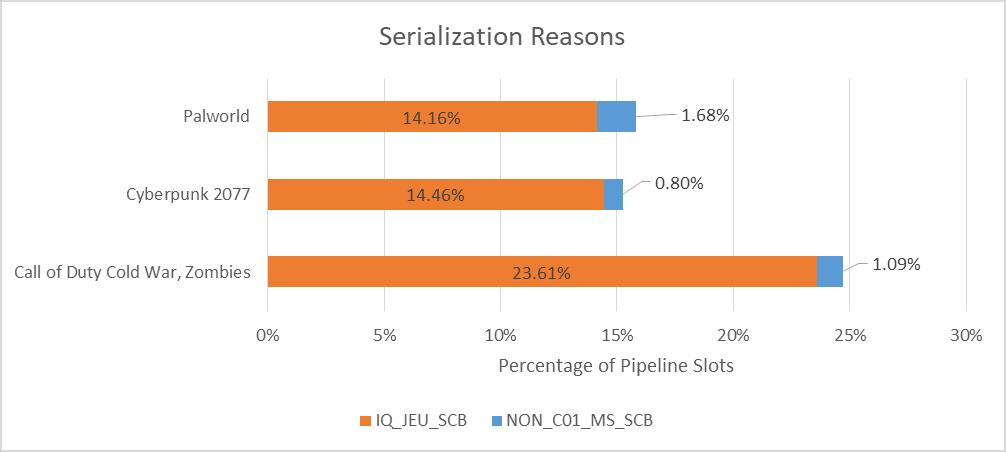
IQ_JEU_SCB 指的是“一个 IQ(指令队列)记分板,它会暂停分配,直到指定的旧微指令退出或(在跳转记分板的情况下)执行。IQ 记分板的常用执行指令包括 LFENCE 和 MFENCE。” 英特尔的描述暗示,Skymont 在某些情况下必须阻止其他指令进入后端,直到 JEU(跳转执行单元?)完成跳转指令的执行。我不确定是什么触发了这种情况。LFENCE(负载围栏)和 MFENCE(内存围栏)是显式软件内存屏障,要求内核对内存访问进行序列化。我认为内核几乎无法避免这种强制序列化。
其他序列化情况很少见。C01_MS_SCB(上文未显示)统计了 UMWAIT 或 TPAUSE 指令将核心置于轻度 C0.1 睡眠状态的情况。NON_C01_MS_SCB 指向“微序列器 (MS) 记分板,它会暂停前端从 UROM 发出指令,直到指定的较旧微指令退出。MS 记分板最常执行的指令是 PAUSE”。这些暂停偶尔会出现,所以游戏可能正在将自旋锁与 PAUSE 指令一起使用。
重访克雷斯特蒙特
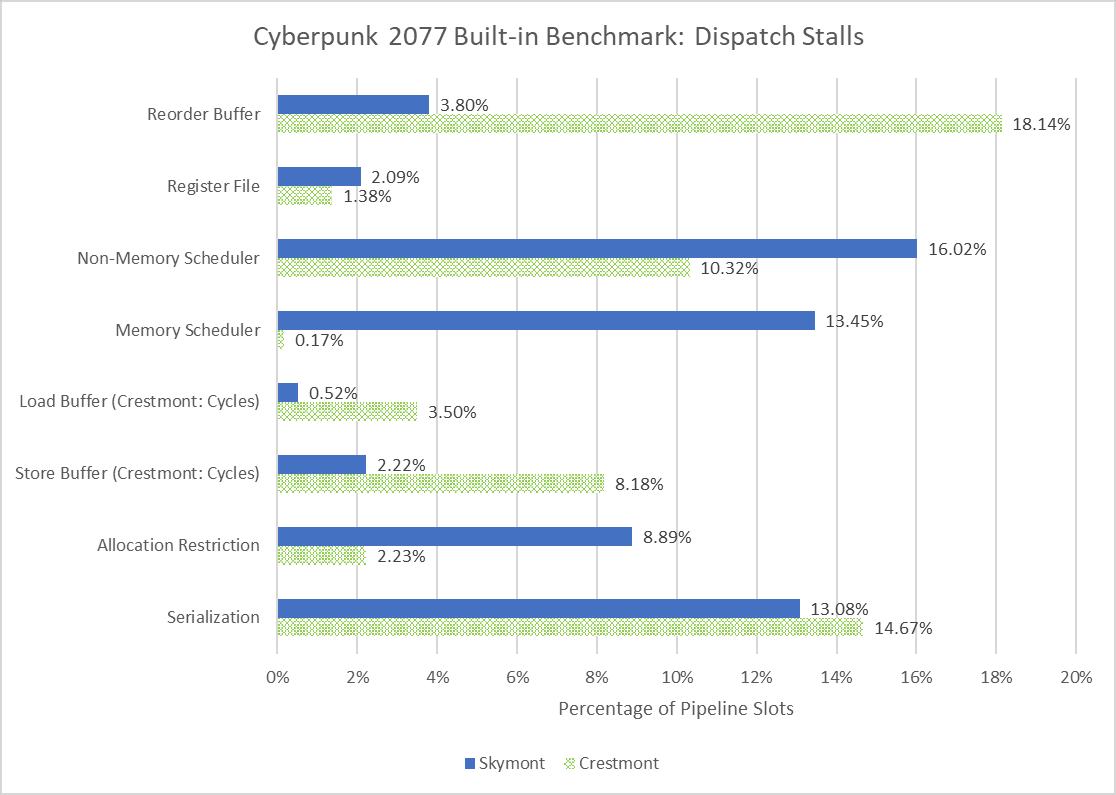
与其前身 Crestmont 相比,Skymont 以大幅提升的重新排序能力而著称。由于我的 Crestmont 安装在没有独立 GPU 的 Meteor Lake 笔记本电脑中,因此无法直接比较两者。但是,运行 Cyberpunk 2077 的内置基准测试以了解总体情况,结果表明 Crestmont 更容易达到其 256 个条目重新排序缓冲区的极限。Crestmont 上的其他限制因素仍然很重要,但与 Skymont 相比,资源停滞的原因已经有所改变。例如,Cresmont 很少耗尽内存调度程序条目,尽管非内存调度程序条目仍然感到压力。分配限制在 Skymont 上更成问题,可能是因为 8 宽的重命名/分配组更有可能包含更多发往同一调度程序的微操作。序列化在两个内核上仍然是一个问题。
数据端缓存和内存访问
缓存未命中往往是最常见的长延迟指令,因此会严重影响资源停顿。Skymont 具有典型的三级数据缓存层次结构,在四核集群中共享 32 KB 的 L1D 和 4 MB 的 L2。Arrow Lake 提供 36 MB 的 L3,由所有核心共享。由于 L2 较大、L1D 较小且没有 L1.5D,与 Lion Cove P-Core 相比,Skymont 更依赖 L2。与 Lion Cove 一样,L2 未命中需要应对约 14 纳秒的 L3 延迟,这与 AMD 低于 9 纳秒的 L3 延迟相比相当高。
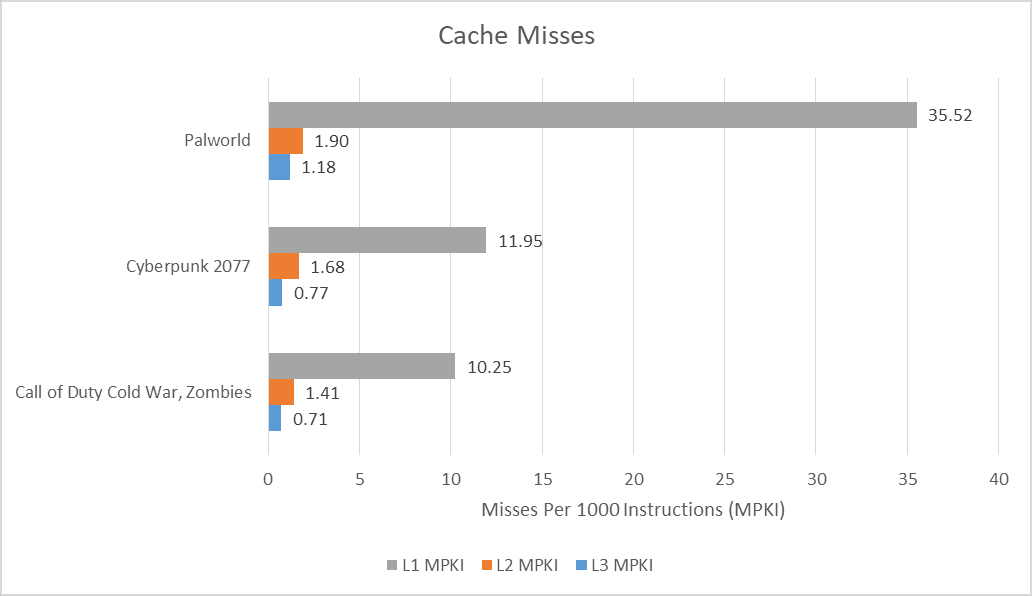
Skymont 可以细分由于 L1D 请求未命中导致核心停滞的频率。“请求”表示访问是由指令(而非预取)发起的,但并不保证该指令确实退出。英特尔并未说明其使用什么标准来确定核心是否停滞。像 Skylake 这样的老款核心也存在类似的情况,例如,如果 L2 中有待处理的加载,且没有 L2 未命中,并且该周期内没有微操作可以开始执行,则认为核心 L2 已绑定。
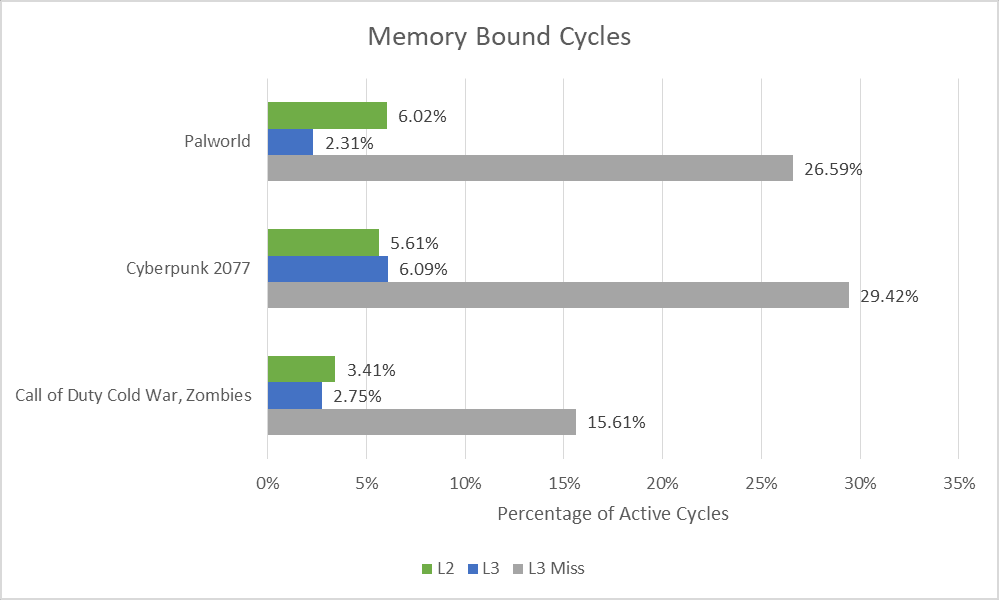
DRAM 延迟是 Skymont 面临的最大挑战。L2 绑定周期较低,这表明 Skymont 的乱序引擎通常可以保持足够多的指令在执行中,从而隐藏 L2 延迟。L3 延迟较高并不会造成太大影响,可能有两个原因。最明显的是,Skymont 拥有 4 MB 的大型 L2 缓存,使其许多访问无需经过 L3 缓存。从长远来看,4 MB 的缓存大小与移动版和主机版 Zen 2 处理器上的 L3 缓存大小相当。其次,Skymont 的时钟速度较低,这意味着它的潜在性能本来就较低。打个比方,流线型较差的飞机可能不太担心空气阻力,因为它的飞行速度较低。从技术上讲,这不算优势,但它确实意味着内核在等待 L3 数据时损失较小。
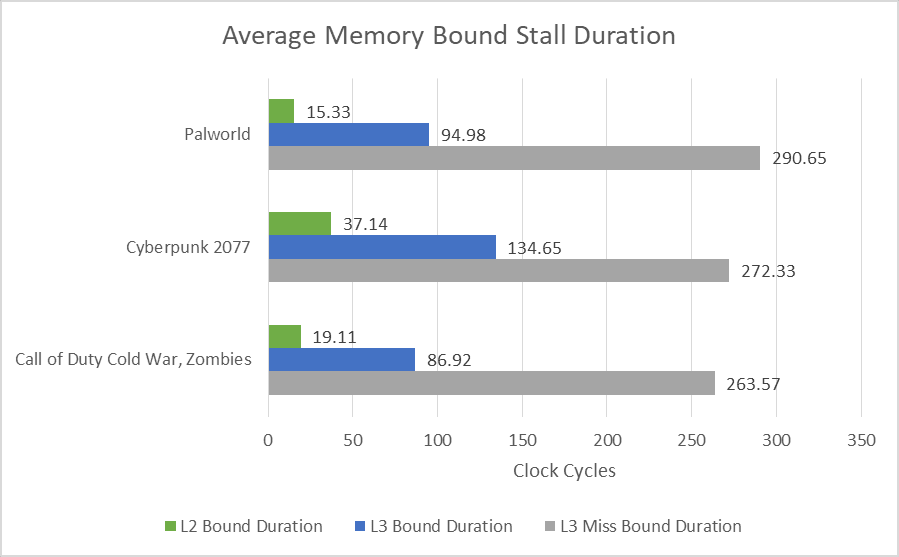
设置边沿位可以计算停顿发生的次数。将停顿周期数除以发生次数,即可得出平均停顿持续时间。这些数字很奇怪,因为平均停顿持续时间超过了 L2 和 L3 缓存的测量延迟。或许很多被阻塞的指令有多个来自指定缓存级别的输入。又或许,Skymont 可能使用与 Skylake 不同的标准来确定核心何时受内存限制。例如,它可能指示核心指令卡在等待来自指定内存层级的数据的时间,即使其他指令在此期间能够执行。
前端
由于后端相关的吞吐量损失,Skymont 的前端很少成为限制因素。不过,Skymont 在前端确实有一些有趣的性能计数器,值得一看。英特尔通过研究前端无法满足核心需求的原因,将与前端相关的停顿细分为带宽限制和延迟限制。相比之下,如果前端在周期内未提供任何微操作,则 Zen 5 和 Lion Cove 认为插槽前端延迟受限;如果前端提供了一些微操作,但不足以填满所有重命名器插槽,则认为插槽前端延迟受限。具体来说:

以这种方式划分延迟和带宽限制时隙对 Skymont 来说可能更有意义,因为与传统的直线解码器相比,其集群解码器更不容易因分支执行而损失吞吐量。基本上,如果解码器接收到指令,但无法高效处理,英特尔会认为 Skymont 前端带宽受限。如果前端由于分支预测器延迟、缓存未命中或 TLB 未命中而导致数据不足,则认为其延迟受限。
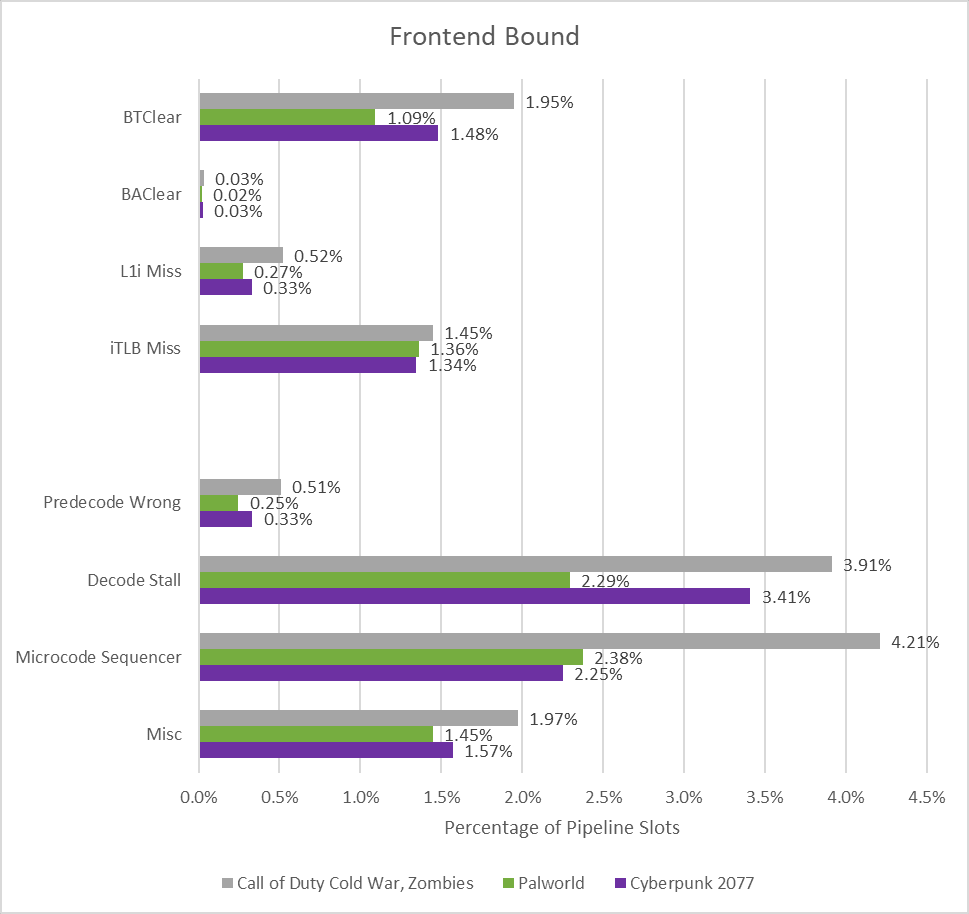
所有来源的延迟都很小,但解码停顿和微码命中会降低一些吞吐量。我不确定是什么原因导致了 Skymont 的解码停顿。英特尔的优化指南指出,解码器之间的负载平衡问题或“其他解码限制”通常会由解码停顿单元掩码指示。微码通常用于执行引擎中快速路径硬件无法处理的指令。密度优化的内核往往为较少见、难度较大的操作预留较少的面积预算,并且可能会使用多个微操作(可能来自微码)来执行这些操作。CPU 设计人员会尝试仔细研究应用程序使用的指令,并尽量减少微操作扩展。但对于像 Skymont 这样的密度优化内核来说,这项任务会更加艰巨。
Skymont 的分支预测准确度在游戏中已经足够好了。我不会深入研究 Palworld 和《使命召唤》,因为我怀疑它们的误差幅度相当高。有趣的是,在《赛博朋克 2077》的内置基准测试中,Skymont 的预测准确度更高,每条指令的错误预测次数减少了大约 25%。
最后的话
Skymont 可能并非 P 核心,也不具备极致性能。然而,主观上它在游戏中的表现不错。我在 Core Ultra 9 285K 上玩了各种游戏,并将亲和力设置为 16 个 E 核心。所有游戏都能够达到超过可玩帧率的水平,并且几乎没有卡顿或其他问题。它很好地展示了密度优化的核心在现代工艺节点上的性能,同时也凸显了追求极致性能时收益递减的问题。我认为,一款仅搭载 Skymont 核心的芯片单独来看应该会表现相当不错。
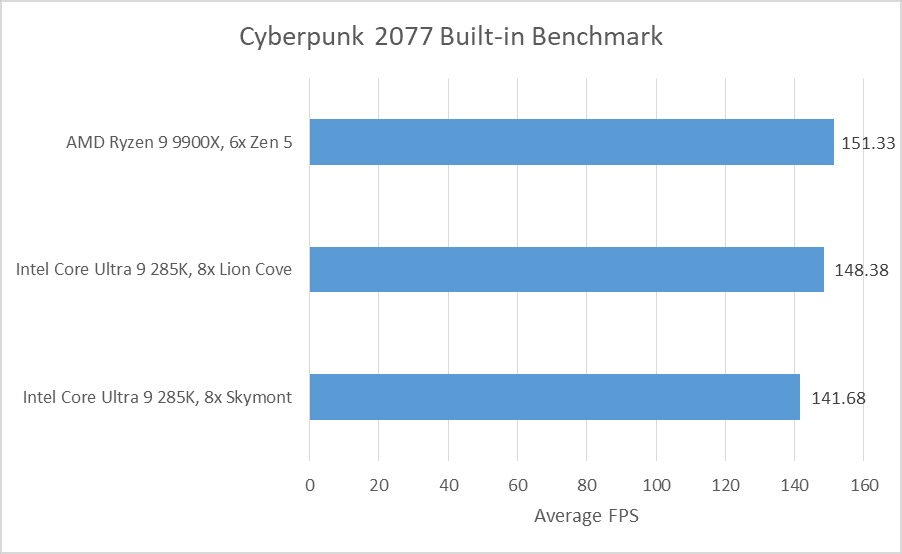
这并不意味着所有 E-Core 芯片都能很快成为主流,也不意味着英特尔的 E-Core 系列可以取代 P-Core。如果历史可以作为参考,那么 E-Core 需要在许多应用程序中超过 P-Core 性能才能兼顾两者。很久以前,英特尔基于 P6 的奔腾 M 在各种工作负载中都能够胜过基于 Netburst 的奔腾 4 芯片,这预示着英特尔将放弃 Netburst 转而支持 Core 2 系列中增强的 P6 变体。Skymont 不再是奔腾 M 在那个时代的水平,英特尔的 Lion Cove P-Core 也不会像 Netburst 那样效率低下。但不可否认的是,Skymont 本身就是一个非常强大的核心。英特尔的 E-Core 团队值得称赞,他们将所有的性能都集中在这么小的面积上。
如果你喜欢这些内容,可以考虑去Patreon或PayPal给 Chips and Cheese 打个广告。也可以考虑加入Discord 。
原文: https://chipsandcheese.com/p/skymont-in-gaming-workloads