自从EvoBlog内部上线以来,我一直想改进它。其中一个方法就是让法学硕士来评判最佳帖子,而不是采用静态的评分系统。
我指定 Gemini 2.5 来担任评委。这篇文章就是我的成果。
最初的系统依赖于固定的评分算法。它计算字数、检查可读性分数,并应用严格的风格指南。这些算法虽然能够控制基本的质量,但却忽略了优秀写作的细微之处。
是什么让一段话比另一段更流畅?如何衡量真实的声音和公式化的内容?
EvoBlog 现在采用了不同的方法。LLM 评估员不再采用静态规则,而是从五个维度对每次尝试进行评分:结构流畅性、开场白、结论影响力、数据整合和语气真实性。
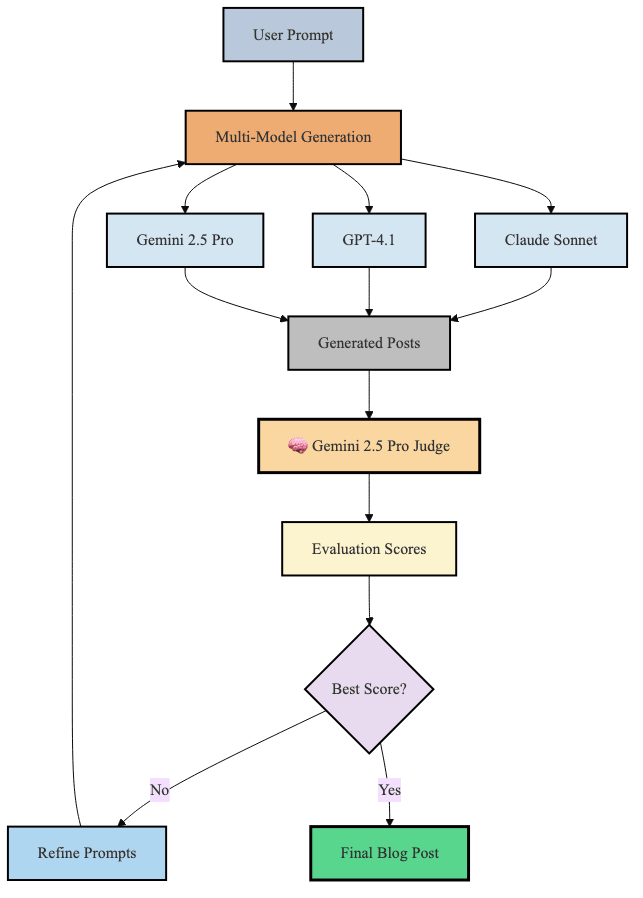
理论上,奇迹发生在迭代改进周期中。
每一轮迭代之后,系统都会分析哪些内容有效,哪些无效。开头的引子得分低吗?下一轮迭代会强调第一段的强化。数据集成是否薄弱?

LLM 评委实验的结果好坏参半。图表显示了 20 次迭代中性能的波动,没有明显的收敛模式。最佳运行结果与我的写作风格相似度达到 81.7%,比最初的 78.6% 提高了 3.1 个百分点。
但最终迭代得分为 75.4%,实际上比开始时的得分还要低。
让法学硕士担任评委听起来不错。但生成和评分的不确定性导致结果并不理想。
而且它价格昂贵。每 20 次迭代运行大约需要 60 次 LLM 调用,或者每篇文章大约 1 美元。所以,可能没那么贵!
但就目前而言,AI法官的效率还不够高。结论是:AI法官需要更多培训才能胜任庭审。
原文: https://www.tomtunguz.com/evolution-of-ai-judges-improving-evoblog/