前几天,Artificial Analysis 发布了一个新的基准,这次重点关注单个模型——OpenAI 的 gpt-oss-120b——在不同托管提供商中的表现。
结果显示了一些令人惊讶的差异。以下是方差最大的一个,在 2025 年 AIME(美国数学邀请赛)的一次运行中,每个模型平均运行了 32 次,使用了 gpt-oss-120b,推理难度设置为“高”:
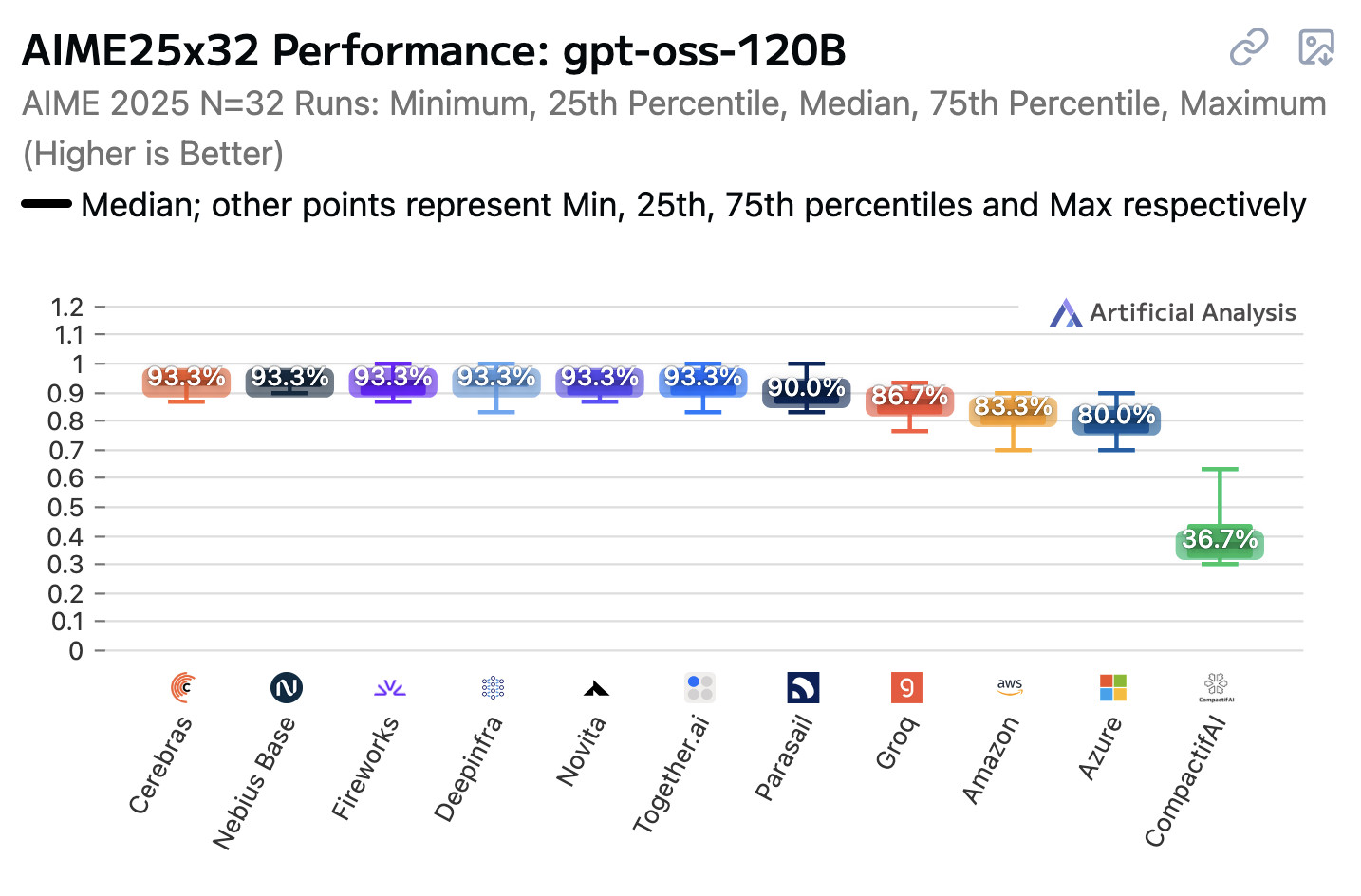
这些是一些不同的结果!
- 93.3%:Cerebras、Nebius Base、Fireworks、Deepinfra、Novita、Together.ai、vLLM 0.1.0
- 90.0%:滑翔伞
- 86.7%:Groq
- 83.3%:亚马逊
- 80.0%:天蓝色
- 36.7%:CompactifAI
看起来大多数得分为 93.3% 的提供商都在使用最新的vLLM运行模型(Cerebras 除外,我相信他们有自己的定制服务堆栈)。
我之前没有听说过 CompactifAI – 我发现了一份 2025 年 6 月 12 日的新闻稿,其中说“CompactifAI 模型是领先的开源 LLM 的高度压缩版本,保留了原始准确性,速度提高了 4 倍至 12 倍,推理成本降低了 50%-80%”,这有助于解释它们明显较低的得分!
Microsoft Azure 的 Lucas Pickup证实,Azure 的 80% 分数是由于运行较旧的 vLLM 造成的,现已修复:
就是这样,截至昨天下午,所有服务实例(托管的 120b 服务)都已修复此问题。旧的 vLLM 提交未遵循 reasoning_effort 原则,因此所有请求默认为“中等”。
目前还没有关于 AWS Bedrock 版本出了什么问题的消息。
开放式重量模型客户面临的挑战
作为开放式重量模型提供商的客户,这真的不是我想要考虑的事情!
不过这并不奇怪。我自己运行模型时,不可避免地要做出选择——选择使用哪个服务框架(我通常在自己的 Mac 笔记本电脑上选择 GGPF/llama.cpp 和 MLX),以及选择使用多大的量化尺寸。
我知道量化有影响,但我很难量化这种影响。
看起来,即使知道托管模型所使用的量化也不一定有足够的信息来预测该模型的性能。
我认为这种情况对开放权重模型来说是一个普遍的挑战。它们通常以一组不透明的模型权重以及在单一平台上运行它们的松散指令的形式发布——如果我们幸运的话!大多数人工智能实验室将量化和格式转换留给社区和第三方提供商。
很多事情都可能出错。工具调用尤其容易受到这些差异的影响——模型已经根据特定的工具调用约定进行了训练,如果提供商没有完全正确地掌握这些约定,结果可能会变得难以预测,而且很难诊断。
某种一致性套件将会在这里大有裨益。如果模型具有可靠的确定性,那么这将很容易:发布一组测试用例,让提供商(或其客户)运行这些用例来检查模型的实现。
然而,即使在 0 的温度下,模型也不是确定性的。也许人工分析的这一新努力正是我们所需要的,特别是因为针对提供商运行完整的基准测试套件在代币支出方面可能非常昂贵。
更新:通过 OpenAI 的 Dominik Kundel,我了解到 OpenAI 现在在 gpt-oss GitHub 存储库中包含一个兼容性测试,以帮助提供商验证他们是否正确实现了工具调用模板等功能,这在他们的验证 gpt-oss 实现手册中有更详细的描述。
标签: ai 、 openai 、 generative-ai 、 local-llms 、 llms 、 evals 、 gpt-oss 、人工智能分析
原文: https://simonwillison.net/2025/Aug/15/inconsistent-performance/#atom-everything