1997 年 8 月, Microsoft Word 敦促一位朋友将“我们不会开具信用票据”这句话替换成截然相反的一句话——这是一种自动虚构,可能会引发代价高昂的承诺。
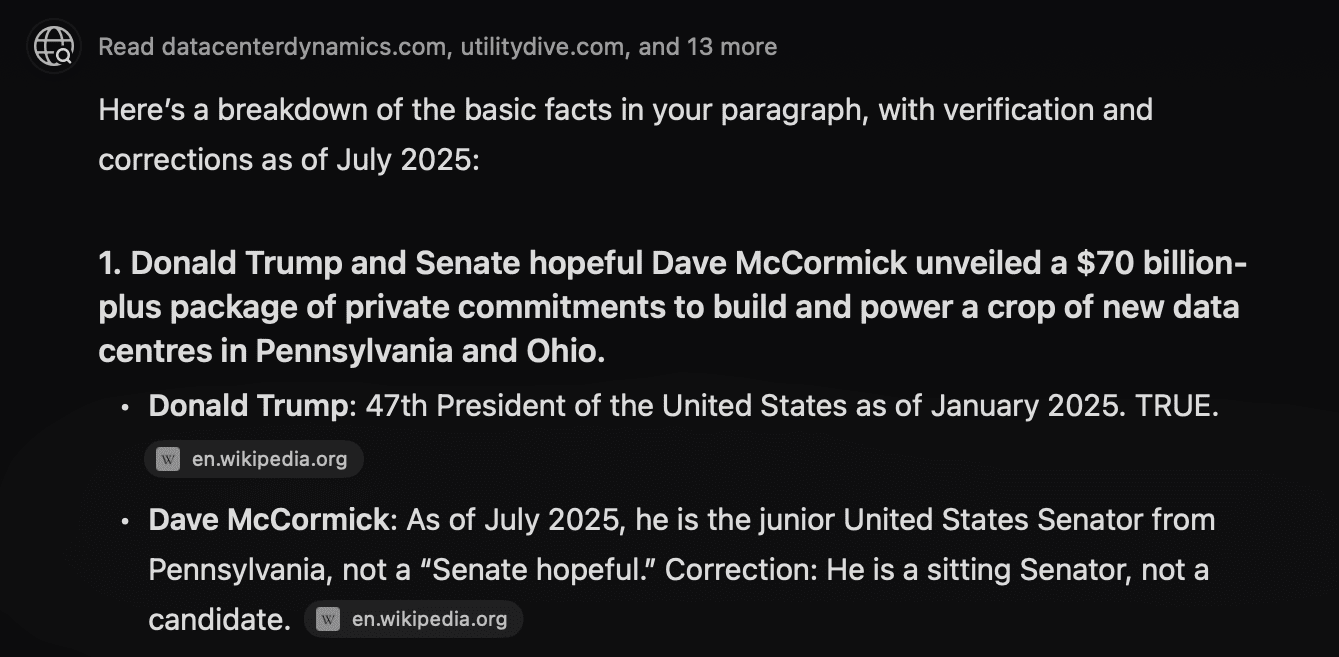
快进到2025年7月17日:我们的人工智能事实核查程序读到一句话,声称参议员戴夫·麦考密克仅仅是“有希望的候选人”。它把这个事实标记为正确。两个时代,两台比我们更聪明的机器,却有一个始终存在的缺陷:当软件带着错误的确定性说话时,人类会点头。让我们来揭秘其中的原因。
我们使用由法学硕士 (LLM) 驱动的事实核查系统来审核每个版本。该事实核查系统使用 o3(可以访问网络搜索)将草稿分解成独立的声明,并与外部来源进行核对。该系统与人工核查人员同时运行。
对于此事,人们错误地认为麦考密克是参议院候选人而不是现任参议员。
平心而论,这句话乍一看似乎并无不妥。其核心在于美国在清洁能源领域的投资规模——数千亿美元的潜在资金。机构细节——参议员或参议员候选人——似乎处于次要地位。但这恰恰是问题所在。该模型,以及某种程度上我们的人工审核员,优先考虑了重要的主题事实,而忽略了具体细节。
最后的发现并非来自法学硕士,而是来自眼尖的读者,他们了解上下文,很快就发现了错误。

意识到问题所在后,我们尝试诊断问题所在。我们用多种不同的 LLMS 软件(包括 o3、o3 Pro、Perplexity 和 Grok)测试了该部分内容。但都没有发现问题。
我们根据模型的反馈改进了提示,但问题仍然存在,即使我们明确指示模型验证人们的角色。以下是第三次迭代:

LLM 注意到了我们原文和它自己发现的差异。这个过程一直持续到我们找到一个繁琐的提示来识别错误。
奇怪的是,通过 Dia 浏览器运行了文本和我们最基本的提示。Dia 从一系列不同的法学硕士 (LLM) 中汲取灵感,并立即发现了问题所在。
换句话说,最基本的工具表现优于最先进的工具。这是人工智能锯齿状边界的典型例证,它描述了人工智能如何在某些认知任务上表现出色,而在其他任务上却出乎意料地失败,两者之间没有平滑的界限。
这是一次富有启发性的失败。以下是它给我们的启示。
1.我们的人机混合工作流程需要重新思考
我们目前的编辑流程使用 LLM 作为第一道审查线,然后才由人工编辑介入。我们的假设是,模型会发现明显的错误,而我们的团队会发现细微的错误。
但这个案例暴露了一个更深层次的缺陷:模型没有捕捉到本应显而易见的东西,因为报道的重点是美国的新产业政策。一个优秀的人类助理编辑应该能够捕捉到(或者至少核实一下关于麦考密克的说法,因为他不像特朗普那么出名)。这就是信任陷阱。沉默伪装成确定性。当法学硕士没有提出任何异议时,我们的认知警惕性就会下降;我们会把没有警觉误认为是证据,而不是无知。该如何避免这种情况?
显然,我们的人工流程需要重新审视,而且会变得更加繁琐。同样,我们的自动化事实核查流程可能需要变成一个多步骤或并行的流程,由不同的系统评估不同类型的论断。我在研究过程中早期就已经这样做了。我倾向于参考几位不同的法学硕士(LLM)来构建一个问题,并利用他们一致和不一致的观点作为进一步研究的起点。
2.随着人工智能融入工作流程,这些风险也会随之扩大
原文: https://www.exponentialview.co/p/ai-fact-checking-failed-us-heres