中间的小黑框是机器学习代码。
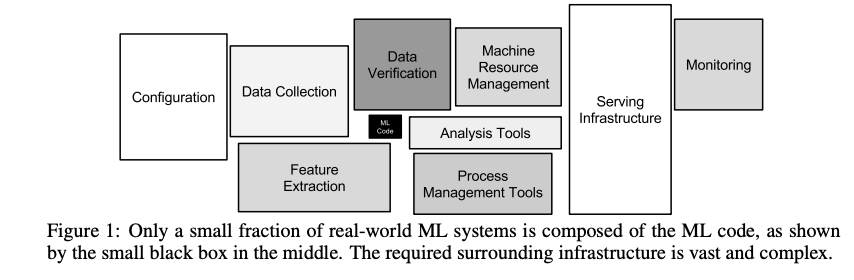
我记得读过谷歌 2015 年发表的《机器学习中的隐藏技术债务》论文,当时我就想,机器学习应用中有多少是真正的机器学习。
绝大多数是基础设施、数据管理和运营复杂性。
随着人工智能的兴起,大型语言模型似乎会取代这些框架。它承诺的是简单易用:只需一个法学硕士 (LLM) 学位,就能看着它处理从客户服务到代码生成的所有事情。不再需要复杂的流程或脆弱的集成。
但在构建内部应用程序时,我们观察到了 AI 的类似动态。
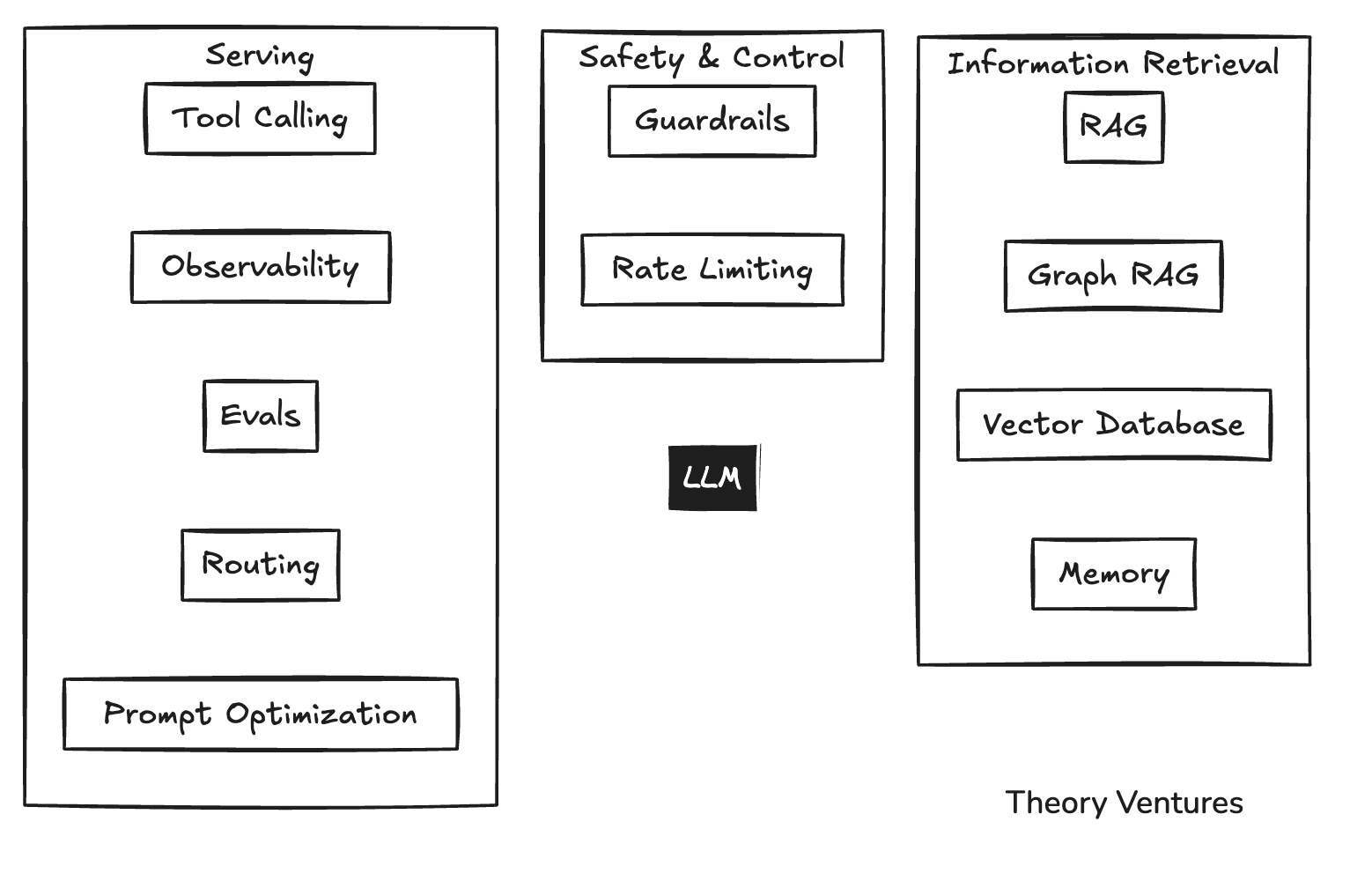
代理需要大量的背景信息,就像人类一样:CRM 是如何构建的,我们在每个字段中输入什么 – 但输入对于Hungry, Hungry AI 模型来说是昂贵的。
降低成本意味着编写确定性软件来取代人工智能的推理。
例如,自动化电子邮件管理意味着编写工具来创建 Asana 任务和更新 CRM。
随着工具数量超过十到十五个,工具调用就不再有效了。是时候启动一个经典的机器学习模型来选择工具了。
然后,利用可观测性来监控系统,评估其性能,并路由到正确的模型。此外,还有一整套软件可以确保人工智能按预期运行。
护栏可防止不适当的响应。速率限制可防止系统失控时成本失控。
信息检索(RAG – 检索增强生成)对于任何生产系统都至关重要。在我的电子邮件应用中,我使用 LanceDB 矢量数据库来查找来自特定发件人的所有电子邮件并匹配其语气。
还有其他围绕图形 RAG 和专门矢量数据库的知识管理技术。
近年来,记忆变得越来越重要。AI工具的命令行界面将对话历史记录保存为markdown文件。
当我发布图表时,我希望在右下角显示 Theory Ventures 的标题,以及特定的字体、颜色和样式。这些现在都保存在一系列层叠目录中的 .gemini 或 .claude 文件中。
大型语言模型原本的简单性已经被企业级的生产复杂性所取代。
这与上一代机器学习系统并不完全相同,但两者有着明显的相似之处。看似简单的“人工智能魔盒”其实只是一座冰山,大部分工程工作都隐藏在水面之下。