
[Cal Bryant] 几年前开发了一套家庭自动化系统,该系统最近将 Piper TTS(文本转语音)语音用于各种未公开的用途。由于不满足于现有的机械式标准语音,[Cal] 着手进行一项实验 ,以商用 TTS 语音生成的单个短语的克隆版本为起点,对 Piper TTS AI 语音模型进行微调。
在 2023 年Piper TTS发布之前,现有的免费 TTS 系统(例如espeak和Festival)听起来机械且单调。Piper 的输出听起来更加自然,且无需大量资源即可运行。为了改变语音风格,Piper AI 模型可以从头开始重新训练,也可以进行更轻松的微调。在后一种情况下,首先要解决的问题是如何生成足够数量的训练短语来运行 Piper AI 模型的微调。这个问题通过重量级 AI 模型 ChatterBox 得到解决,该模型能够进行所谓的零样本训练。点击此处查看 Chatterbox 演示。
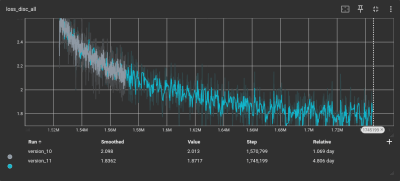 随着损失函数变小,模型的准确率会越来越好
随着损失函数变小,模型的准确率会越来越好
训练从文本格式的测试短语语料库开始,以确保能够充分覆盖日常英语。[Cal] 使用 ChatterBox 克隆了由“神秘 TTS 系统”生成的单个测试短语的音频,并根据这个新语音创建了 1,300 个测试短语。这组音频作为训练数据,用于在 GPU 平台上对 Piper AI 模型进行微调。
为了验证准确性,[Cal] 使用 OpenAI 的 Whisper 软件将音频转录回文本,以便与原始文本语料库进行比较。为了克服标点符号问题以及美式英语和英式英语之间的差异,我们使用 espeak-ng 将文本转换为音素,最终短语匹配准确率达到 98%。
使用 SoX 对训练集进行下采样后,它已准备好用于 Piper TTS 训练系统。尽管做了所有准备,但运行软件的过程却令人失望。数据集中的一些不一致之处导致我们不得不删除一些数据点。由于担心高温,我们将模型停在室外阴凉处进行了五天的训练, TensorBoard显示模型的损失函数正在收敛。这就是 AI 的用语:模型已调优完毕,可以投入使用了!我们觉得这听起来相当不错。
如果所有这些新奇的人工智能语音合成技术对你来说太过复杂,甚至有点令人毛骨悚然,我们能否提供一个更像上世纪 80 年代的解决方案,让物体说话?毕竟,大多数人都把说话的能力视为理所当然,直到他们无法再说话为止。这里有一个团队,他们正在利用尖端人工智能技术,帮助人们重拾这种能力。
原文: https://hackaday.com/2025/07/09/how-to-train-a-new-voice-for-piper-with-only-a-single-phrase/