2022 年推出的 Apple M2 和 2024 年推出的 Apple M4 均采用基于 ARM 的片上系统 (SoC) 设计,并采用统一内存架构。也就是说,它们使用相同的内存进行图形处理 (GPU) 和主计算 (CPU)。M2 处理器采用 LPDDR5 内存,而 M4 则采用 LPDDR5X,后者应该能提供略高的带宽。
您在 Apple 系统上获得的具体带宽取决于您的配置。但我对单核随机访问性能很感兴趣。为了测量这项性能,我构建了一个包含大量索引的大型数组。这些索引构成一个随机循环:从任意元素开始,如果您读取其值,则将其视为索引,移动到该索引,依此类推,您将访问大型数组中的每个元素。这种基准测试通常被称为“指针追逐”,因为它模拟了当您的软件中充满了指向数据结构的指针时发生的情况,而这些数据结构本身也是由指针构成的,依此类推。
从内存加载任何值时,都会有数个周期的延迟。值得庆幸的是,现代处理器可以同时处理多个这样的加载请求。具体数量取决于处理器,但现代处理器可以同时处理数十个内存请求。这种现象是我们所说的内存级并行性的一部分:内存子系统能够同时处理多个任务。
因此,我们可以将指针追踪基准测试拆分成多个通道。不必只从一个位置开始,而是可以同时从两个位置开始,一个在“起始点”,另一个在中间点。依此类推。我将这种划分的数量称为一个“通道”。因此,它是一个通道、两个通道等等。显然,通道越多,速度就越快。根据速度,您可以假设数组中的每次命中都相当于加载一个缓存行(128 字节),从而估算有效带宽。
我在两款处理器(Apple M2 和 Apple M4)上运行基准测试。我必须限制通道数量,因为超过一定值后噪音就会太大。最多 28 个通道效果很好。
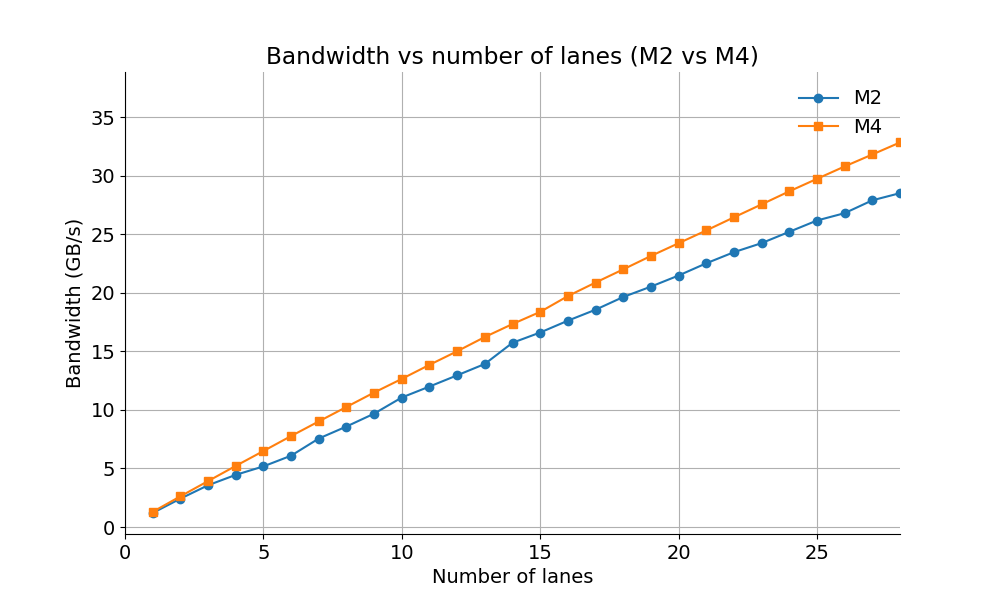
或许并不意外,我发现 M4 和 M2 之间的差异并不大(大约 15%)。两款处理器都能明显支持 28 个通道。
原文: https://lemire.me/blog/2025/07/09/memory-level-parallelism-apple-m2-vs-apple-m4/