谷歌今天发布了极其重要的新开放权重模型:
多模式设计: Gemma 3n 原生支持图像、音频、视频和文本输入和文本输出。
专为设备端优化: Gemma 3n 型号以效率为设计重点,提供两种基于有效参数的尺寸:E2B 和 E4B。虽然它们的原始参数数量分别为 5B 和 8B,但架构创新使其运行内存占用与传统的 2B 和 4B 型号相当,仅需 2GB (E2B) 和 3GB (E4B) 内存即可运行。
这非常令人兴奋:针对最终用户设备优化的 2B 和 4B 模型,可接受文本、图像和音频作为输入!
Gemma 3n 也是我见过的任何模型中首发最全面的:谷歌与“AMD、Axolotl、Docker、Hugging Face、llama.cpp、LMStudio、MLX、NVIDIA、Ollama、RedHat、SGLang、Unsloth 和 vLLM”合作,因此现在有几十种方法可以尝试。
到目前为止,我已经在我的 Mac 笔记本电脑上运行了两个版本。Ollama 提供了 4B 型号的7.5GB 版本(完整标签gemma3n:e4b-it-q4_K_M0 ),我的运行方式如下:
ollama pull gemma3n llm install llm-ollama llm -m gemma3n:latest "Generate an SVG of a pelican riding a bicycle"
它给我画了这样一幅画:

Ollama 版本似乎尚不支持图像或音频输入。
…但是mlx-vlm版本可以!
首先,我尝试在这个 WAV 文件上进行如下操作(使用改编自Prince Canuma 的视频的配方):
uv run --with mlx-vlm mlx_vlm.generate \ --model gg-hf-gm/gemma-3n-E4B-it \ --max-tokens 100 \ --temperature 0.7 \ --prompt "Transcribe the following speech segment in English:" \ --audio pelican-joke-request.wav
下载了 15.74 GB 的 bfloat16 版本的模型并输出以下正确的转录:
给我讲一个关于鹈鹕的笑话。
然后我让它给我画了一只鹈鹕:
uv run --with mlx-vlm mlx_vlm.generate \ --model gg-hf-gm/gemma-3n-E4B-it \ --max-tokens 100 \ --temperature 0.7 \ --prompt "Generate an SVG of a pelican riding a bicycle"
我非常喜欢这个:
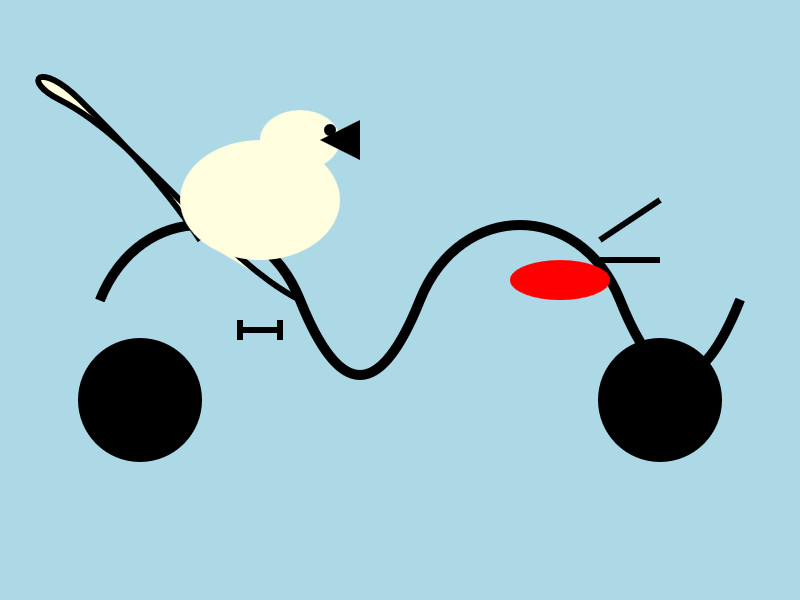
有趣的是,7.5GB 和 15GB 模型量化之间存在如此显著的视觉差异。
标签:谷歌、人工智能、生成人工智能、本地法学硕士、法学硕士、视觉法学硕士、鹈鹕骑自行车、 gemma 、法学硕士发布
原文: https://simonwillison.net/2025/Jun/26/gemma-3n/#atom-everything