今年才过去六个月,人工智能的发展速度就已经超越了二十年来普通科技的周期。今年一月,DeepSeek 震惊了世界。谷歌、OpenAI 和 Anthropic 也紧随其后,推出了能够操控互联网软件工具的下一代模型。
随后,第一波智能体应运而生:ManusAI——直到最近还是一家默默无闻的初创公司——推出了一款能够自主处理复杂任务的智能体;而Anthropic则推出了Claude Code,一个被许多开发者称为梦想的多智能体系统。实验室竞赛正在升温,但在ChatGPT亮相两年后,宏观生产力数据依然停滞不前。
这就是能力吸收差距:前沿实验室的飞速发展超过了传统经济的跟进速度。当前一代人工智能已经强大到足以重塑我们的工作方式,但企业吸收这些能力的速度却远慢于实验室提升的速度。我并不责怪他们。价格每六个月减半;模型仍然是随机的,这增加了可靠性的复杂性;而且管理知识匮乏。
在今天的文章中,我们将探讨这一差距以及企业可以采取哪些措施。
能力已经超越我们多少
记分牌上的结果非常明确:自去年以来,几乎每一个公共基准都有所上升,而之前的卓越标准则显得非常普通。
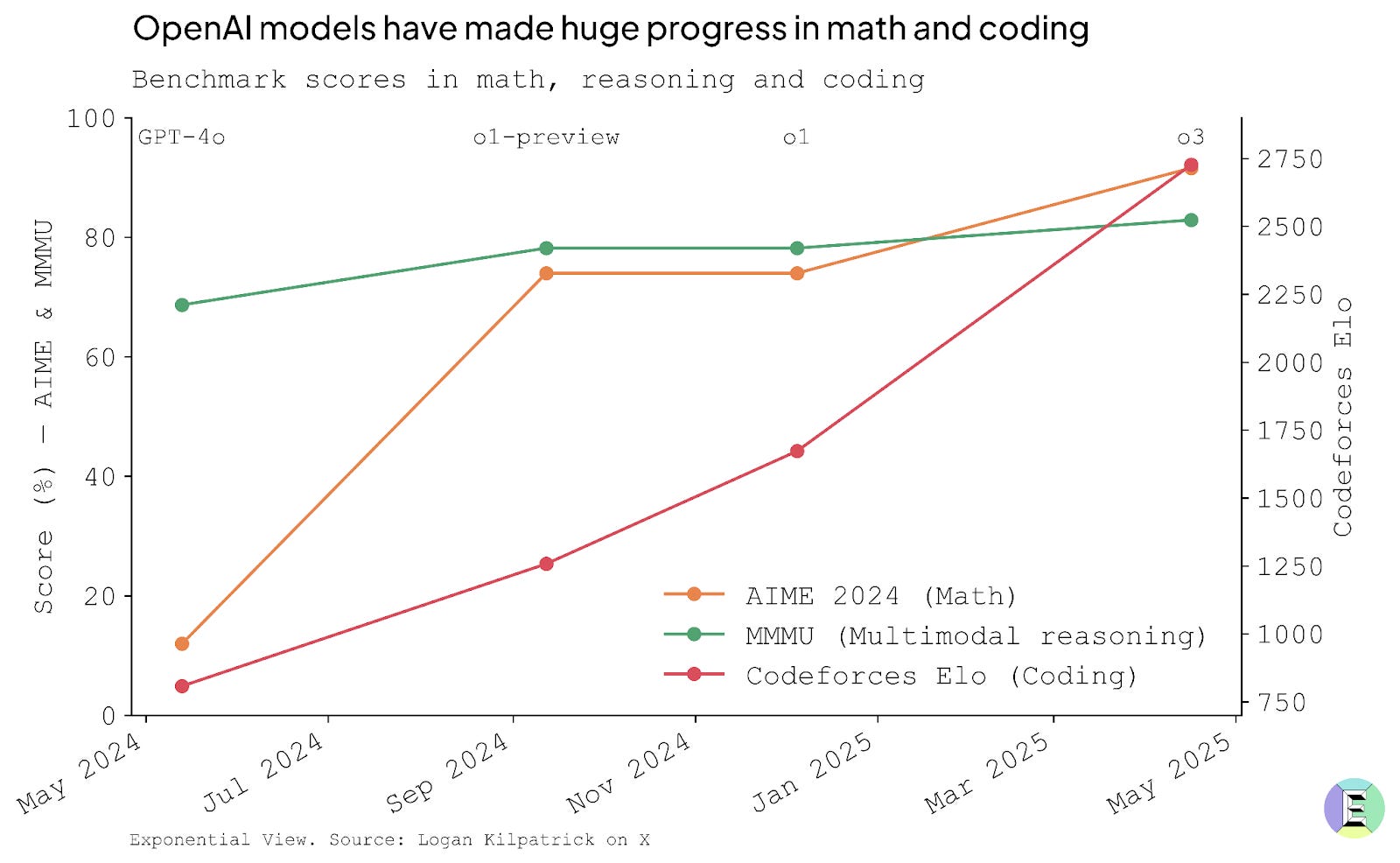
个人经历生动地印证了这一点。我偶尔会在笔记本电脑上本地运行模型,尤其是在 Wi-Fi 信号较差的航班上。这些本地模型的功能与大约一年前的 GPT-4 相差无几,但缺乏我们后来见证的推理和工具使用功能。与目前最先进的技术相比,现在离线使用这些模型感觉非常有限。
实际效益显而易见,尤其是在实际工作流程中。在软件工程领域,人工智能驱动的编码工具已迅速从基本的代码提示发展到管理整个流程——规划、编写、测试,并提交完成的工作以供人工审核。Claude Code 和 OpenAI 的 Codex 等系统现在可以端到端地自动化这些任务,将人类的工作简化为监督角色。虽然并非完美无缺,但它们的快速改进通过将繁琐的编码转化为易于管理的审核,简化了工作流程。
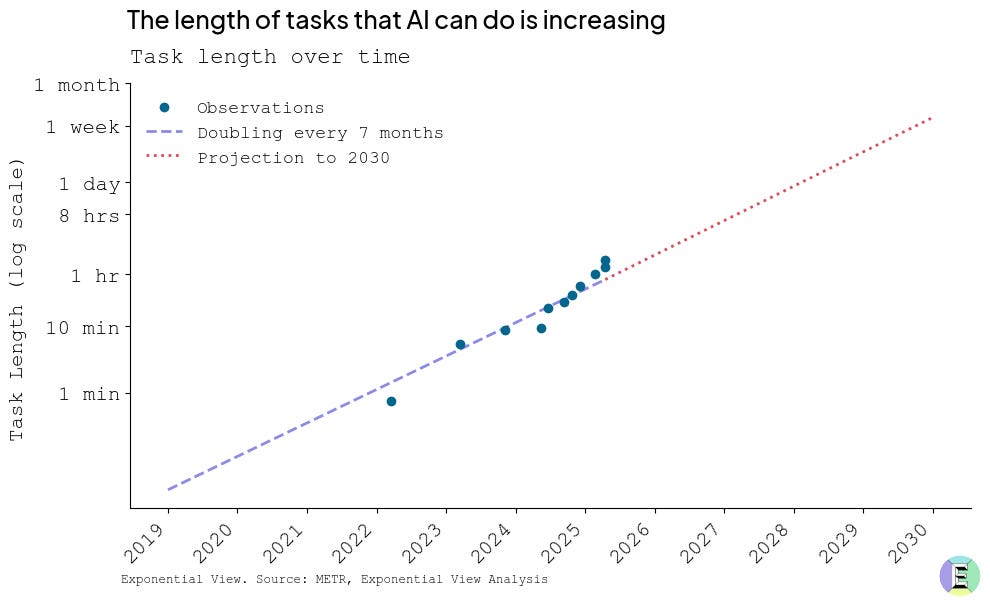
这些进步之所以成为可能,是因为模型现在可以处理日益复杂的任务。不妨看看 METR 最新的代理耐久性基准测试,它衡量的是 AI 模型能够维持复杂的多步骤工作流程的时间。在这项测试中,表现最佳的模型的续航时间比仅仅六个月前延长了三到五倍。这一显著的提升表明,规划能力更加深入,工具使用也更加可靠。
简而言之,能力曲线仍然很陡峭,并且继续在多个维度上快速攀升。
或许更重要的是,人工智能的单位成本正在呈指数级下降。这正是我对指数级技术的定义的核心——它不仅指性能的提升,还指特定能力的成本迅速下降。
以 ChatGPT 的推理价格为例,它大约每六个月就会下降一半——甚至超过了 DRAM 和太阳能的历史成本下降幅度。这种急剧下降源于算法的持续改进和供应商之间的激烈竞争。更低的价格反过来又推动了更广泛的应用:AI 代理越便宜,部署范围就越广。(尽管显然仍有改进空间——我最近一个晚上就用掉了 80 美元的 Replit 积分。)

重要的是,即使人工智能实验室突然在一夜之间停止前沿研究和模型扩展,这些成本改进仍会持续累积。在我的幕后谈话中,专家们对仅靠扩展定律是否能带领我们一路走向通用人工智能(无论最终意味着什么)的看法大致各占一半。如果仅靠扩展定律还不够,大多数人认为我们可能仍然只差一两个重大的概念突破。
然而,关于规模的争论并未从根本上改变核心论点。未来能力的提升虽然有价值,但对于实质性的经济转型而言,只是附加的,而非先决条件。现有模型已经超出了大多数企业能够有效吸收或利用的范围。在Exponential View ,我们仍在探索如何围绕 O3 重新定义我们的工作流程;我预计大多数组织仍在探索如何全面整合 GPT-4O。
麦肯锡报告显示,几乎所有公司都在投资人工智能,但只有1% 的公司声称已将其完全融入工作流程并取得了有意义的业务成果。说实话,即使是这 1% 也可能只是公关宣传。
吸收滞后的原因——三大摩擦
这种缓慢的吸收,而非前沿创新,才是我们在经济统计数据之外随处可见人工智能繁荣的主要原因。即使人工智能初创公司以创纪录的速度积累了数百万至数百亿美元的收入,情况依然如此。但全球经济规模巨大——每年约100万亿美元——这意味着OpenAI的数量非常庞大。即使是增长最快的人工智能初创公司,也需要几年时间,而不是几个季度,才能为全球收入贡献1%。(顺便说一句,我毫不怀疑它们会达到这一水平,而且人工智能原生的新兴企业将在未来20年取代各行各业的许多老牌企业,只是不会在未来两年内实现。)
经济的其余部分由现有企业主导。这些现有企业内部存在着摩擦。他们需要解决这个问题。这种能力吸收差距的根源在于三种不同的制度摩擦,而且每种摩擦都是结构性的,而非技术性的。
原文: https://www.exponentialview.co/p/ai-is-ready-is-your-company