CDNA 4 是 AMD 最新的面向计算的 GPU 架构,在 CDNA 3 的基础上进行了适度更新。CDNA 4 主要致力于提升 AMD 在低精度数据类型下的矩阵乘法性能。这些运算对于机器学习工作负载至关重要,因为机器学习工作负载通常可以在极低精度类型下保持可接受的准确度。同时,CDNA 4 致力于保持 AMD 在更广泛应用的矢量运算方面的领先地位。

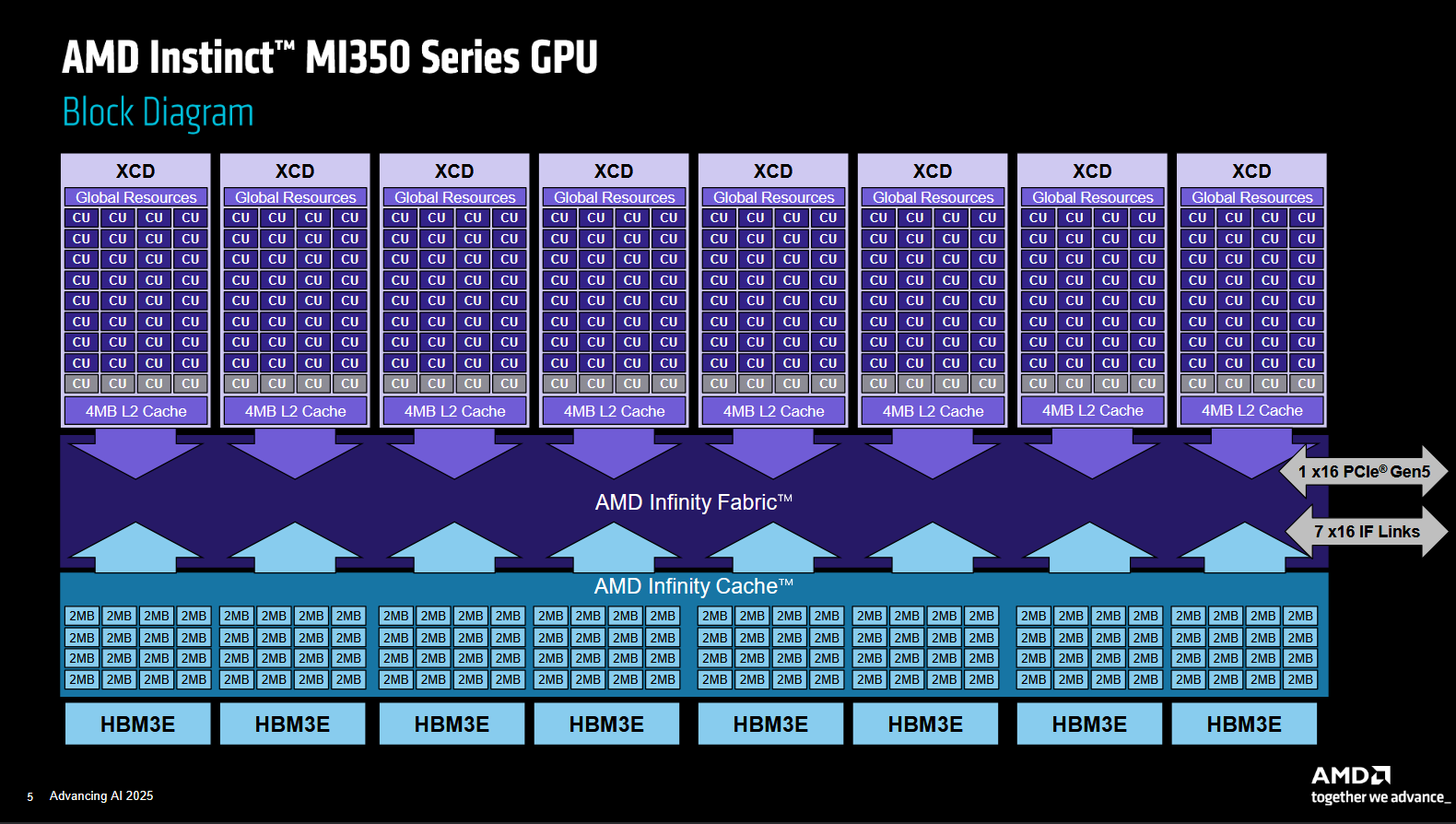
为此,CDNA 4 在很大程度上采用了与 CDNA 3 相同的系统级架构。它采用大规模芯片组设置,与 AMD 在 CPU 产品中成功运用芯片组的做法类似。加速器计算芯片(XCD)包含 CDNA 计算单元,其作用类似于 AMD CPU 产品上的核心复合芯片 (CCD)。八个 XCD 位于四个基础芯片之上,这些基础芯片实现了 256 MB 的内存侧缓存。AMD 的 Infinity Fabric 技术可在整个系统中提供一致的内存访问,并可跨越多个芯片。
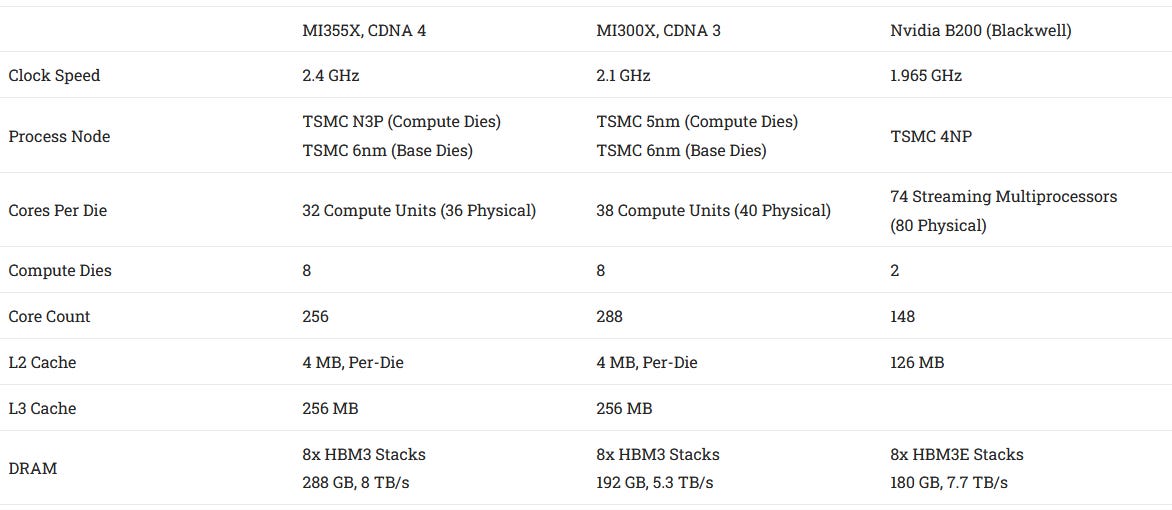
与基于 CDNA 3 的 MI300X 相比,搭载 CDNA 4 的 MI355X 略微减少了每个 XCD 的 CU 数量,并禁用了更多 CU 以维持良率。由此产生的 GPU 宽度略小,但更高的时钟速度弥补了大部分差距。与 Nvidia 的 B200 相比,MI355X 和 MI300 都是更大的 GPU,拥有更多基本构建模块。Nvidia 的 B200 确实采用了多芯片策略,打破了长期以来使用单片设计的传统。然而,AMD 的 chiplet 设置更加激进,并试图在具有大型计算 GPU 的 CPU 设计中复制其扩展成功。
计算单元变化
CDNA 3 的矢量吞吐量优势远超 Nvidia 的 H100,但在机器学习工作负载方面则更为复杂。得益于成熟的软件生态系统以及对矩阵乘法吞吐量(张量核心)的高度关注,Nvidia 通常能够接近( https://chipsandcheese.com/p/testing-amds-giant-mi300x )名义上规模更大的 MI300X。当然,如果 H100 的显存耗尽,AMD 仍然保持着巨大的优势,但 AMD 肯定还有改进的空间。
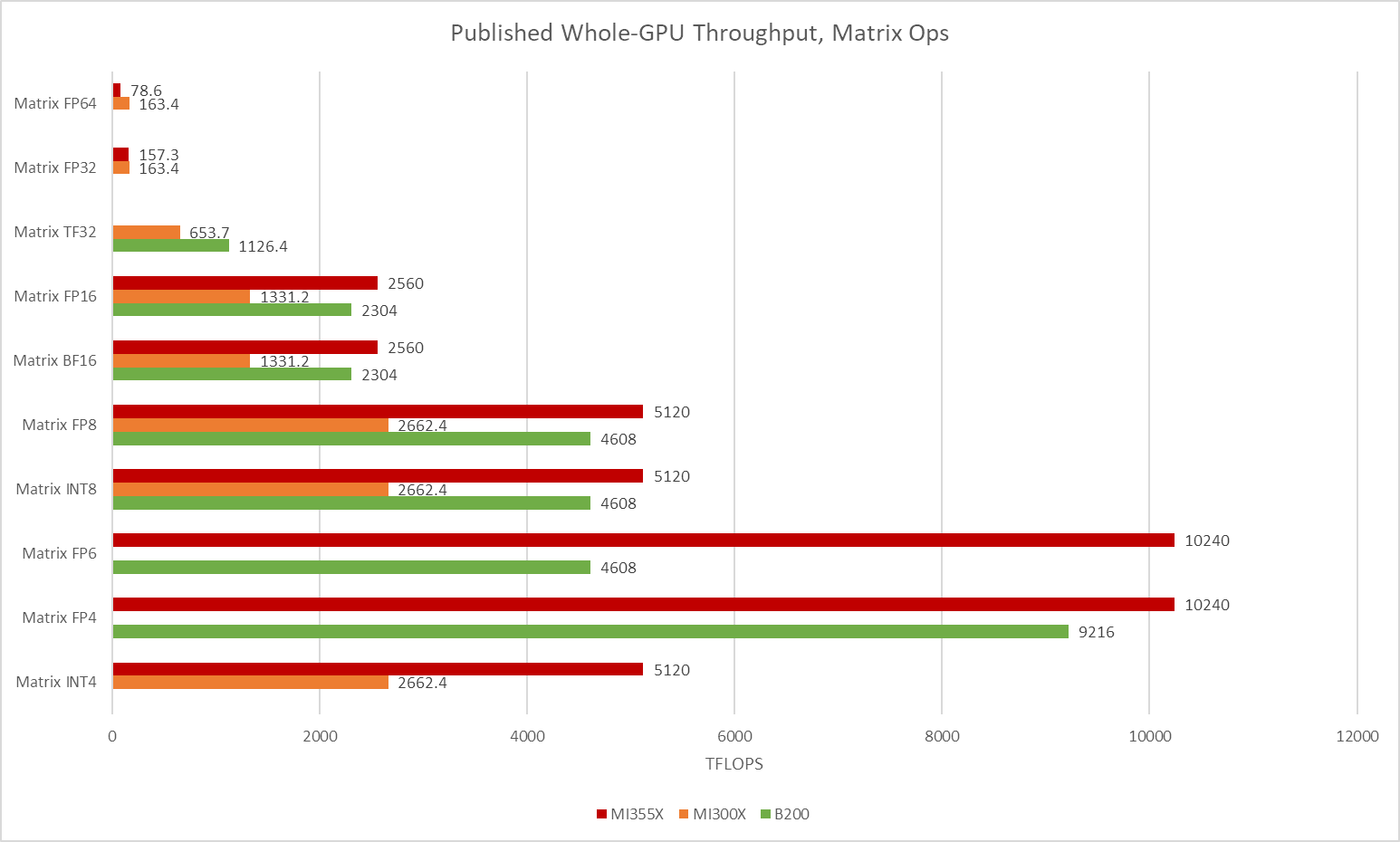
CDNA 4 重新平衡了其执行单元,使其更专注于低精度数据类型的矩阵乘法,而这正是机器学习工作负载所需的。在许多情况下,每 CU 的矩阵吞吐量翻倍,CDNA 4 CU 在 FP6 中与 Nvidia 的 B200 SM 匹敌。不过,在其他方面,Nvidia 仍然更加注重低精度矩阵吞吐量。在 16 位和 8 位数据类型范围内,B200 SM 的每时钟吞吐量是 CDNA 4 CU 的两倍。AMD 继续依靠拥有更大、更高时钟频率的 GPU 来保持整体吞吐量领先地位。
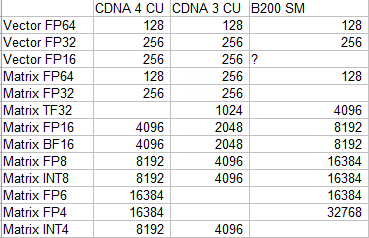
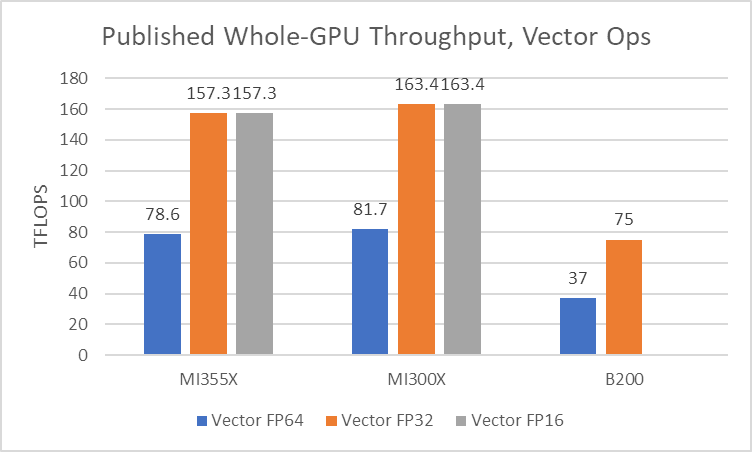
凭借矢量运算和更高精度的数据类型,AMD 延续了 MI300X 的巨大优势。每个 CDNA 4 CU 继续拥有 128 条 FP32 通道,计算 FMA 运算时每周期可提供 256 FLOPS 的计算能力。MI355X 较低的 CU 数量确实导致矢量性能与 MI300X 相比略有下降。但与 Nvidia 的 Blackwell 相比,AMD 更高的核心数量和更高的时钟速度使其在矢量吞吐量方面保持了巨大的领先优势。因此,AMD 的 CDNA 产品线在高性能计算工作负载方面仍然表现不俗。
Nvidia 专注于机器学习和矩阵运算,尽管运行频率较低的 SM 数量较少,但 Nvidia 在该领域仍保持着极强的竞争力。AMD 的巨型 GPU MI355X 在许多数据类型上都处于领先地位,但 AMD 与 Nvidia 最强 GPU 之间的差距远不及矢量计算那么大。
更大的 LDS
GPU 提供了一个软件管理的暂存器,用于本地一组线程(通常是在同一核心上运行的线程)。AMD GPU 使用本地数据共享 (LDS) 来实现此目的。Nvidia 将其类似的结构称为共享内存。CDNA 3 拥有一个 64 KB 的 LDS,延续了 AMD GCN GPU 早在 2012 年就采用的类似设计。该 LDS 拥有 32 个 2 KB 的存储体,每个存储体宽度为 32 位,在没有存储体冲突的情况下,每个周期最多可提供 128 个字节。
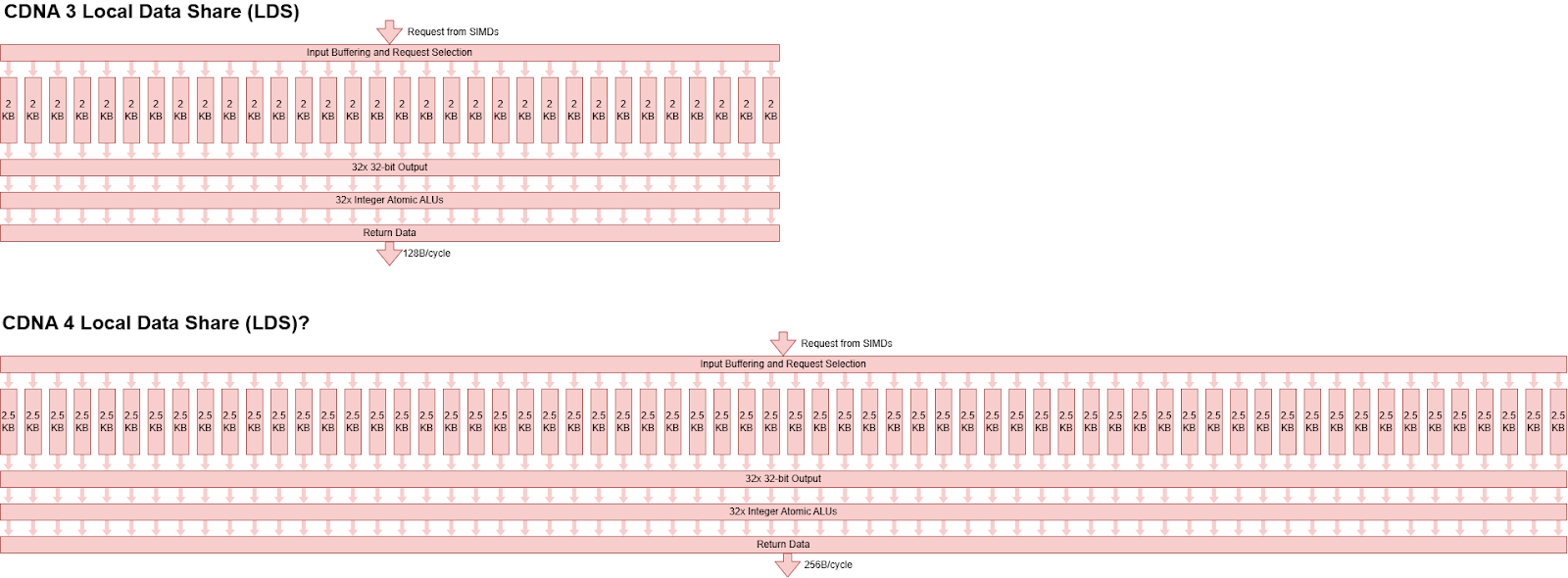
CDNA 4 将 LDS 容量提升至 160 KB,并将读取带宽翻倍至每时钟 256 字节。GPU 原生运行于 32 位元素,因此可以合理地假设 AMD 通过增加存储体数量来翻倍带宽。如果是这样,那么每个存储体现在可能拥有 2.5 KB 的容量。另一种可能性是将存储体数量增加到 80 个,同时将存储体大小保持在 2 KB,但这不太可能,因为这会使存储体选择变得复杂。64 个存储体的 LDS 自然可以支持 64 位宽的波前访问,每个存储体服务于一个通道。此外,2 的幂次方个存储体数量允许通过地址位子集轻松选择存储体。
更大的 LDS 空间允许软件将更多数据保存在靠近执行单元的位置。内核可以分配更多 LDS 容量,而不必担心 LDS 容量限制导致占用率降低。例如,分配 16 KB LDS 的内核可以在 CDNA 3 CU 上运行 4 个工作组。在 CDNA 4 CU 上,这个数字将增加到 10 个工作组。

软件必须显式地将数据移入 LDS 才能利用它,与使用硬件管理的缓存相比,这可能会增加开销。CDNA 3 具有 GLOBAL_LOAD_LDS 指令,允许内核将数据复制到 LDS 中,而无需经过向量寄存器文件。CDNA 4 增强了 GLOBAL_LOAD_LDS 指令,使其支持每通道最多 128 位的移动,而 CDNA 3 上每通道仅支持 32 位。也就是说,GLOBAL_LOAD_LDS 指令可以接受 1、2、4、12 或 16 个 DWORDS(32 位元素)的大小,而 CDNA 3 上只能接受 1、2 或 4 个 DWORDS 。
CDNA 4 还引入了读取转置 LDS 指令。矩阵乘法涉及将一个矩阵中某一行的元素与另一个矩阵中相应列的元素相乘。这通常会对至少一个矩阵造成低效的内存访问模式,具体取决于数据是按行主序还是列主序排列。转置矩阵可以将笨拙的行列操作转换为更自然的行行操作。对于 AMD 的架构来说,在 LDS 上处理转置也很自然,因为 LDS 已经有一个交叉开关,可以将存储体输出映射到通道(swizzle)。
即使 LDS 容量增加了,AMD 的 GPU 核心中的数据存储空间仍然比 Nvidia 要小。Blackwell 的 SM 有一个 256 KB 的存储块,既可用作 L1 缓存,又可用作共享内存。最多可分配 228 KB 用作共享内存。如果分配 164 KB 共享内存,接近 AMD 的 160 KB LDS,Nvidia 仍有 92 KB 可用于 L1 缓存。CDNA 4 与 CDNA 3 一样,每个 CU 都有 32 KB L1 矢量缓存。因此,Blackwell SM 可以拥有更多的软件管理存储,同时仍具有比 CDNA 4 CU 更大的 L1 缓存。当然,AMD 更高的 CU 数量意味着整个 GPU 有 40 MB 的 LDS 容量,而 Nvidia 在 B200 上只有约 33 MB 的共享内存,最大共享内存分配为 228 KB。
系统架构
为了满足海量计算单元阵列的需求,MI355X 在很大程度上采用了与 MI300X 相同的系统级架构。不过,MI355X 确实有一些增强功能。二级缓存可以“回写脏数据并保留行副本”。“脏”是指已在回写缓存中修改,但尚未传播到内存子系统较低级别的数据。当脏行被清除以腾出空间容纳新数据时,其内容将被写回到下一级缓存;如果是最后一级缓存,则写回到 DRAM。
AMD 可能正在寻求在内存子系统负载较低时适时使用写入带宽,以平滑由缓存填充请求和写回操作引起的带宽需求峰值。或者,如果写入的数据可能被系统中的其他线程读取,但预计短期内不会再次被修改,AMD 可能会采取一些特殊措施,让 L2 缓存将一条数据线转换为干净状态。

MI355X 的 DRAM 子系统已升级为使用 HBM3E,相比其前代产品,带宽和容量均有显著提升。这也使 AMD 保持了对 Nvidia 竞争对手的领先优势。Nvidia 的 B200 也使用了 HBM3E,后者似乎也拥有八个 HBM3E 堆栈。然而,B200 的最大容量为 180 GB,带宽为 7.7 TB/s,而 MI355X 的最大容量为 288 GB,带宽为 8 TB/s。当 H100 的 DRAM 容量耗尽时,MI300X 可能比 Nvidia 的旧款 H100 拥有显著优势,而 AMD 很可能希望保持这一优势。
HBM3E 带来的更高带宽也有助于提升 MI355X 的计算带宽比。MI300X 每 FP32 FLOP 的 DRAM 带宽约为 0.03 字节,而 MI355X 则提升至 0.05 字节。相比之下,Blackwell 每 FP32 FLOP 的 DRAM 带宽约为 0.10 字节。虽然 Nvidia 增加了 Blackwell 的末级缓存容量,但 AMD 仍然更依赖大缓存,而 Nvidia 则更依赖 DRAM 带宽。
最后的话
CDNA 2 和 CDNA 3 与前代产品相比进行了彻底的改变。CDNA 4 的变化则更为平淡。与从 Zen 3 到 Zen 4 类似,MI355X 保留了类似的芯片组排列,但计算和 IO 芯片组被替换为改进版本。AMD 并没有改变其总体战略,而是专注于优化 CDNA 3。更少、更高时钟频率的计算单元更易于利用,而更高的内存带宽也有助于提高利用率。更高的矩阵乘法吞吐量也有助于 AMD 在机器学习工作负载方面与 Nvidia 展开竞争。
在某些方面,AMD 在这一代 GPU 上的做法与 Nvidia 颇为相似。从矢量执行的角度来看,Blackwell SM 与 Hopper 基本相同,改进主要集中在矩阵方面。Nvidia 可能认为他们找到了制胜法宝,因为他们过去几代 GPU 无疑都取得了成功。AMD 的 CDNA 3 或许也找到了制胜法宝。MI300A 是 MI300X 的 iGPU 兄弟,它为 TOP500 六月榜单中排名最高的超级计算机提供动力。4在成功的基础上继续发展可能是一种安全且回报丰厚的策略,而 CDNA 4 或许正是如此。
如果你喜欢这些内容,可以考虑去Patreon或PayPal给 Chips and Cheese 打个广告。也可以考虑加入Discord 。
参考
-
https://github.com/llvm/llvm-project/blob/main/clang/test/CodeGenOpenCL/builtins-amdgcn-gfx950.cl – b96 和 b128(96 位和 128 位)global_load_lds 大小
-
https://docs.nvidia.com/cuda/blackwell-tuning-guide/index.html
-
https://www.reddit.com/r/hardware/comments/1kj38r1/battle_of_the_giants_8x_nvidia_blackwell_b200/ – 报告 B200 通过 OpenCL 实现了 148 个计算单元。Nvidia 通常报告计算单元数量的 SM。
原文: https://chipsandcheese.com/p/amds-cdna-4-architecture-announcement