这是由来自 IBM、Invariant Labs、苏黎世联邦理工学院、谷歌和微软等组织的 11 位作者撰写的新论文,是对即时注入和 LLM 安全文献的极好补充。
在本文中,我们描述了一些LLM代理的设计模式,这些模式可以显著降低即时注入的风险。这些设计模式限制了代理的行为,明确阻止它们解决任意任务。我们相信这些设计模式在代理实用性和安全性之间提供了有价值的权衡。
以下是完整引文: 《保护 LLM 代理免受即时注入的设计模式》 (2025 年),作者:Luca Beurer-Kellner、Beat Buesser、Ana-Maria Creţu、Edoardo Debenedetti、Daniel Dobos、Daniel Fabian、Marc Fischer、David Froelicher、Kathrin Grosse、Daniel Naeff、Ezinwanne Ozoani、Andrew Paverd、Florian Tramèr 和 Václav Volhejn。
看到这样的论文开始出现,我非常兴奋。早在四月份,我就写过一篇关于谷歌 DeepMind 的论文《通过设计击败即时注入》 (又名 CaMeL 论文)的文章,这是我见过的第一篇针对即时注入攻击使用工具的 LLM 系统(通常称为“代理”)所带来的挑战,提出可靠解决方案的论文。
这篇新论文对即时注入进行了有力的解释,然后提出了六种设计模式来帮助防止即时注入,其中包括 CaMeL 论文中提出的模式。
问题的范围
本文的作者非常清楚地了解问题的范围:
只要代理及其防御都依赖于当前的语言模型类,我们认为通用代理不太可能提供有意义且可靠的安全保障。
这就引出了一个更有成效的问题:我们现在可以构建哪些类型的代理,既能完成有用的工作,又能抵御即时注入攻击?在本节中,我们将介绍一组 LLM 代理的设计模式,旨在减轻(即使不能完全消除)即时注入攻击的风险。这些模式对代理施加了有意的限制,明确限制了它们执行任意任务的能力。
这是一种非常现实的方法。我们没有灵丹妙药来阻止快速注入,所以我们需要做出权衡。他们在这里做出的权衡是“限制代理执行任意任务的能力”。这种权衡并不受欢迎,但在我看来,它为这篇论文增添了很大的可信度。
这一段证明他们完全理解这一点(重点是我加的):
我们提出的设计模式遵循一个共同的指导原则:一旦 LLM 代理获取了不受信任的输入,就必须对其进行约束,使其无法触发任何后续操作——即对系统或其环境产生负面影响的操作。至少,这意味着受限的代理不得调用可能破坏系统完整性或机密性的工具。此外,它们的输出不应构成下游风险——例如泄露敏感信息(例如,通过嵌入链接)或操纵未来的代理行为(例如,对用户查询做出有害的响应)。
我的想法是,任何暴露于潜在恶意令牌的行为都会完全污染该提示的输出。任何能够潜入其令牌的攻击者都应该被视为对接下来发生的事情拥有完全的控制权——这意味着他们不仅控制了 LLM 的文本输出,还控制了 LLM 可能调用的任何工具调用。
我们来谈谈他们的设计模式。
动作选择器模式
一种相对简单的模式使代理免受提示注入的影响(同时仍允许它们采取外部行动),即防止这些行动向代理提供任何反馈。
代理可以触发工具,但无法接触或处理这些工具的响应。您无法阅读电子邮件或检索网页,但可以触发诸如“将用户发送到此网页”或“向用户显示此消息”之类的操作。
他们将这种模式概括为“LLM 调制的 switch 语句”,我觉得这很准确。
计划-执行模式
更宽松的方法是允许工具输出反馈给代理,但防止工具输出影响代理采取的行动选择。
其理念是提前规划工具调用,避免任何可能暴露于不受信任内容的风险。这样可以执行更复杂的操作序列,同时避免某个操作引入恶意指令,进而触发意外的有害操作的风险。
他们的示例将“将今天的日程安排发送给我的老板 John Doe”转换为calendar.read()工具调用,然后是email.write(..., '[email protected]') 。 calendar.read()输出可能会损坏已发送电子邮件的正文,但无法更改该电子邮件的收件人。
LLM Map-Reduce 模式
之前的模式仍然允许恶意指令影响发送到下一步的内容。Map-Reduce 模式涉及由协调器指挥的子代理,这些子代理会接触不受信任的内容,并在稍后安全地汇总其结果。
在他们的示例中,一位代理被要求查找包含本月发票的文件并将其发送给会计部门。每个文件都由一个子代理处理,子代理会返回一个布尔值来指示该文件是否相关。被判定为相关的文件将被汇总并发送。
他们将其称为 map-reduce 模式,因为它反映了分布式计算的经典 map-reduce 框架。
双学位法学硕士模式
我在这里得到了引用!早在 2023 年 4 月,我就描述了用于构建能够抵御即时注入的 AI 助手的 Dual LLM 模式,它也影响了CaMeL 论文。
他们描述了我的确切模式,甚至用这张图表进行了说明:
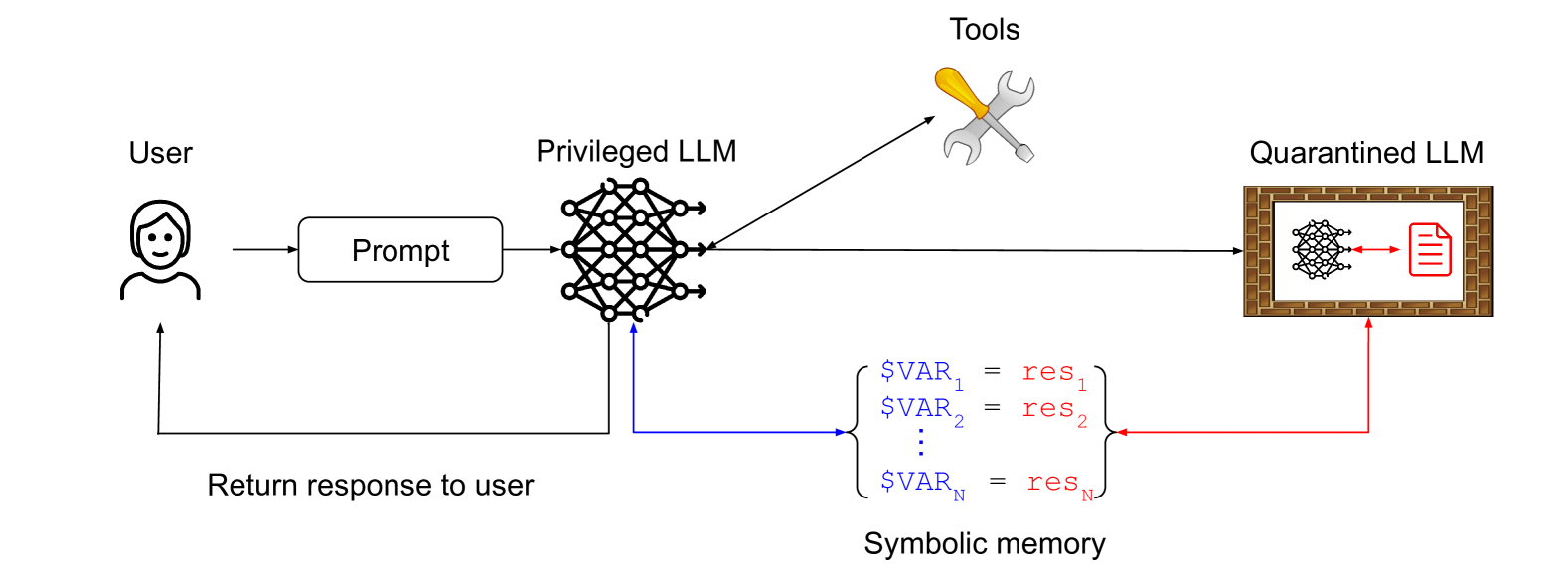
这里的关键思想是,特权LLM与隔离LLM进行协调,避免任何不受信任内容的暴露。隔离LLM返回符号变量(例如,表示摘要网页的$VAR1 ,特权LLM可以请求将这些变量显示给用户,而不会暴露受污染的内容本身。
先编码后执行模式
这是DeepMind 的 CaMeL 论文中描述的模式。它是我的双 LLM 模式的改进版本,其中特权 LLM 在自定义沙盒 DSL 中生成代码,该 DSL 指定应调用哪些工具以及如何将它们的输出相互传递。
DSL 旨在实现完整的数据流分析,以便可以标记任何受污染的数据并在整个过程中进行跟踪。
上下文最小化模式
为了防止某些用户提示注入,代理系统可以在多次交互中从上下文中删除不必要的内容。
例如,假设恶意用户向客服聊天机器人询问新车报价,并试图通过提示注入的方式让客服给予大幅折扣。系统可以确保客服首先将用户的请求转换为数据库查询(例如,查找最新优惠)。然后,在将结果返回给客户之前,将用户的提示从上下文中移除,从而阻止提示注入。
我对这句话有点困惑,但我想我明白它的意思。如果用户的提示符被转换成一个SQL查询,返回数据库中的原始数据,并且返回的数据不可能包含原始提示符中的任何文本,那么任何提示符注入攻击的可能性都应该被消除。
案例研究
本文的其余部分提出了十个案例研究来说明如何在实践中应用这些设计模式,每个案例研究都附有详细的威胁模型和潜在的缓解策略。
其中大多数都非常实用且详细。例如, SQL Agent案例研究涉及一位法学硕士 (LLM),该硕士拥有访问 SQL 数据库的工具,并编写和执行 Python 代码来帮助分析这些数据。这对于即时注入来说是一个极具挑战性的环境,本文用三页纸探讨了以负责任的方式构建即时注入的模式。
以下是完整的案例研究列表。任何与你正在从事的工作相关的案例研究都值得你花时间去研究:
- 操作系统助手
- SQL代理
- 电子邮件和日历助手
- 客户服务聊天机器人
- 预订助理
- 产品推荐器
- 简历筛选助理
- 药物说明书聊天机器人
- 医疗诊断聊天机器人
- 软件工程代理
以下是上一个软件工程代理案例研究中关于如何安全地使用不受信任的外部文档中的 API 信息的一个有趣建议:
我们能想到的最安全的设计是,代码代理仅通过严格格式化的接口与不受信任的文档或代码进行交互(例如,代理无法看到任意代码或文档,而只能看到正式的 API 描述)。这可以通过使用隔离的 LLM 处理不受信任的数据来实现,该 LLM 被指示将数据转换为具有严格格式要求的 API 描述,以最大限度地降低即时注入的风险(例如,方法名称限制为 30 个字符)。
- 实用性:由于代理只能看到 API,而看不到自然语言描述或第三方代码示例,因此实用性降低。
- 安全性:提示注入必须被格式化为 API 描述,如果格式要求足够严格,这种情况不太可能发生。
我想知道允许最多 30 个字符的方法名称是否真的安全……真正有创造力的攻击者可能会想出一个像run_rm_dash_rf_for_compliance()这样的方法名称,即使在这些限制下也会造成严重破坏。
总结
我写关于快速注射的文章已经快三年了,但一直没耐心尝试写一篇正式的论文。看到如此高质量的论文开始涌现,我感到无比欣慰。
即时注入仍然是负责任地部署这种人人都热衷的代理系统的最大挑战。这类问题越能得到研究界的关注,就越好。
标签:提示注入、安全、渗透攻击、生成式人工智能、设计模式、人工智能、法学硕士、人工智能代理
原文: https://simonwillison.net/2025/Jun/13/prompt-injection-design-patterns/#atom-everything