我使用静态网站管理我的书签。我收藏了超过 2000 个页面,并为每个页面保留本地快照。这些快照与书签数据一起存储,因此即使原始网站离线或内容发生变化,我也始终可以访问。


我曾在专业环境中处理过网络档案,但这次完全是个人事务。这给了我更多自由来做出不同的决策和权衡。我可以专注于我关心的页面,花更多时间进行质量控制,并删除页面中不需要的部分——而不必担心机构标准或长期的公共访问。
在这篇文章中,我将向您展示如何构建这个网络个人档案:如何保存页面,为什么选择手动保存,以及我如何确保每个页面都得到妥善保存。
本文是四部分书签迷你系列文章的第二部分:
- 为我的所有书签创建一个静态站点– 我为什么要添加书签、为什么使用静态站点以及它是如何工作的。
- 创建我所有书签的本地存档(本文)
- 通过阅读两千个网页学习如何制作网站(5 月 19 日推出)——我从阅读我保存的网页源代码中学到的一切。
- 我的书签收藏中有一些很酷的网站(5 月 26 日上线)——一些利用网络做一些特别有趣或聪明的事情的网站。
我想要从网络档案中得到什么?
我正在创建一个个人网络档案库——它只属于我自己。我可以对它的内容和运作方式非常挑剔,因为只有我才能阅读或保存它的内容。它不是公共资源,其他人永远不会看到它。
这意味着这与我在专业或机构环境中所做的工作截然不同。在那里,优先级有所不同:自动化优于手动,不变性优于可编辑性,并且强烈偏好可共享或公开的内容。
我想要每个网页的完整副本
我希望我的存档里有我收藏的每个页面的副本,并且每个副本都能很好地替代原始页面。它应该包含渲染页面所需的所有内容——文本、图片、视频、样式等等。
如果原始站点发生变化或离线,我仍然应该能够看到我保存的页面。
我希望档案保存在我的电脑上
我不想依赖可能中断、更改或关闭的在线服务。
我在使用 Pinboard 时就深刻体会到了这一点。我之前付费购买了一个存档账户,它承诺会保存我所有书签的副本。但近年来,它变得不太可靠——有时存档页面失败,有时我甚至无法检索到原本应该保存的页面。
保存新页面应该很容易
我每周都会保存几个新书签。我希望这个存档保持最新,而且不想让添加页面变成一件麻烦事。
它应该支持私人或付费页面
我读了很多不在公共网络上的页面,比如付费墙或登录界面的内容。我想把这些内容收录到我的网络档案里。
许多网络档案馆只保存公开内容——要么是因为他们无法访问私人内容进行保存,要么是即使访问了也无法共享。因此,我保留自己的私人页面副本就显得尤为重要,因为我可能找不到其他副本。
应该可以编辑快照
这既是加法,也是减法。
网页可以嵌入外部资源,有时我希望将这些资源添加到我的存档中。例如,假设有人发布了一篇关于会议演讲的博客文章,并嵌入了他们演讲的 YouTube 视频。我希望下载视频,而不仅仅是 YouTube 嵌入代码。
网页上还有很多我不想保存的垃圾内容——广告、跟踪器、弹出窗口等等。我想把这些东西都删掉,只保留有用的部分。这就像从杂志上剪下内容:我想要的是文章本身,而不是包裹在文章周围的广告。
我的网络档案是什么样的?
我将存档的书签视为书签网站本身:作为静态文件,保存在本地文件系统的文件夹中。
每个页面的静态文件夹
每个页面我都有一个文件夹,里面存放着 HTML、样式表、图片和其他链接文件。每个文件夹都是一个独立的“迷你网站”。如果我想查看保存的页面,只需在浏览器中打开 HTML 文件即可。
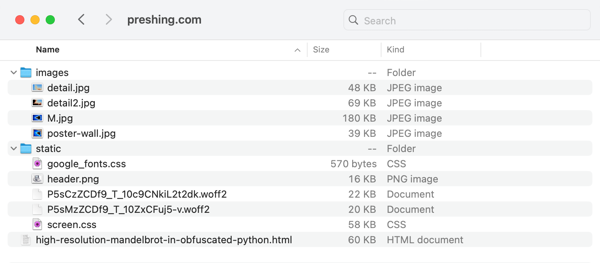 单个网页的文件保存在我的存档文件夹中。我将每个网站的结构扁平化,放入顶级文件夹中,例如
单个网页的文件保存在我的存档文件夹中。我将每个网站的结构扁平化,放入顶级文件夹中,例如images和static ,这样可以保持简洁易读。我不关心原始网站的确切 URL 路径。
每当 HTML 代码引用外部文件时,我都会将其改为从本地文件夹而不是原始网站获取。例如,原始 HTML 代码中可能有一个<img>标签,用于从https://preshing.com/~img/poster-wall.jpg加载图片,但在我的本地副本中,我会将<img>标签改为从images/poster-wall.jpg加载。
我喜欢这种方法,因为它使用了开放的、基于标准的网络技术,而且这种结构简单、耐用且易于维护。这些基于文件夹的快照很可能在我的余生中都可读。
为什么不是 WARC 或 WACZ?
许多机构将其网络档案存储为WARC或WACZ ,这是专门用于存储已保存网页的文件格式。
这些文件包含已保存的页面,以及关于档案创建方式的额外信息——这些信息对未来的研究人员来说非常有用。这些信息可能包括 HTTP 标头、IP 地址或创建档案的软件名称。
您只能使用专业的“播放”软件打开 WARC 或 WACZ 文件,或者直接解压存档中的文件。这两种文件格式都是开放标准,因此理论上您可以编写自己的软件来读取它们——以这种方式保存的存档不会被限制在专有格式中——但实际上,您只能从少数工具中进行选择。
在我的个人档案中,我不需要那些额外的上下文,也不想依赖有限的工具。编辑 WARC 文件也很困难,而这恰恰是我的一个需求。我无法轻松地打开它们并删除所有广告,或者添加额外的文件。
我更喜欢文件和文件夹的灵活性——我可以在任何网络浏览器中打开 HTML 文件,轻松进行更改,并使用我喜欢的任何工具。
如何保存每个网页的本地副本?
我手动保存每个页面,然后检查它是否看起来不错——我保存了所有外部资源,如图像和样式表。
这种手动检查让我安心,因为我确信每个网页都保存了,而且是高质量的副本。我不会在两年后打开快照,却发现缺少关键图片或插图。
让我们更详细地了解一下这个过程。
手动保存单个网页
我首先使用 Web 浏览器中的“另存为”按钮保存 HTML 文件。
我在网页浏览器和文本编辑器中打开该文件。使用浏览器的开发者工具,查找需要保存到本地的外部文件——样式表、字体、图片等等。我下载缺失的文件,在文本编辑器中编辑 HTML 以指向本地副本,然后在浏览器中重新加载页面查看结果。我一直重复这个过程,直到下载完所有内容,并得到一个完整的离线页面副本。
我在开发者工具中的大部分时间都花在两个选项卡上。
我查看“网络”选项卡,看看页面正在加载哪些文件。它们是从本地磁盘加载的,还是从互联网获取的?我希望所有文件都来自磁盘。
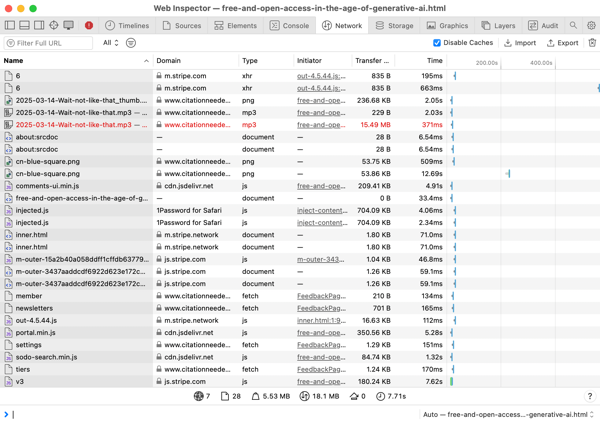 这个 HTML 文件正在发出大量外部网络请求——我还有更多的工作要做!
这个 HTML 文件正在发出大量外部网络请求——我还有更多的工作要做!
我检查了“控制台”选项卡,看看页面加载过程中是否有任何错误——比如找不到图片,或者 JavaScript 文件加载失败。我想修复所有这些错误。
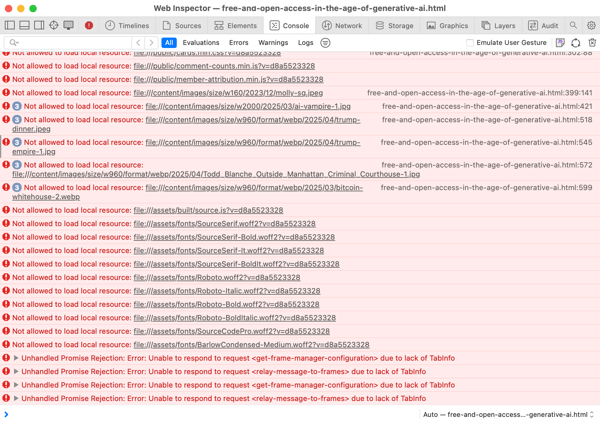 好多红色啊!
好多红色啊!
我花了很多时间手动阅读和编辑 HTML。我比较习惯处理别人的代码,保存一个页面通常只需要几分钟。对于我每周保存的少量新页面来说,这还算可以,但对于更大的存档来说,就显得力不从心了。
一旦我下载了页面所需的所有内容,消除了外部请求,并修复了错误,我就得到了快照。
删除所有垃圾
保存页面时,我会删除所有不需要的内容。这样可以使我的快照更小,页面通常会缩小 10 到 20 倍。我删除的垃圾内容包括:
-
广告。太多广告了。我发现一个特别激进的插件,它在每个段落之间都插入了一个广告
<div>。 -
用于时效性事件的横幅。新闻快讯、公告、限时促销,甚至博物馆银行假日开放时间的横幅。
-
相关内容的内联链接。很多文章每隔几段就会出现一篇其他文章的推广信息。我觉得这很让人分心,尤其是我已经在浏览网站了!我把那些链接都删掉了,所以我保存的文章就只剩下正文了。
-
Cookie 通知、分析、追踪以及其他用于收集“同意”的服务。我不在乎保存网页时使用了什么追踪工具,它们完全浪费我的个人档案空间。
当我在文本编辑器中编辑页面时,我会查找<script>和<iframe>元素。这些元素可以很好地指示我想要移除的内容——例如,大多数广告都是在 iframe 中加载的。我保存的很多内容都是静态内容,不需要 JavaScript 的交互性。我可以将其从页面中移除,同时仍然保留有用的快照。
在我的个人档案中,我认为这些删除操作明显有所改进。快照加载速度更快,读取更方便,而且我也不会保存那些永远不会用到的垃圾文件。但在公共场合这样做我会更加谨慎。
机构网络档案馆力求将网页原封不动地保存下来。他们希望研究人员相信,他们看到的是原始页面的真实呈现,内容和含义均未发生改变。删除页面上的任何内容,无论出于何种善意,都可能破坏这种信任——谁来决定删除哪些内容?对我来说无关紧要的内容,对其他人来说可能是至关重要的线索。
使用模板来管理重复收藏的网站
对于我经常收藏的大型复杂网站,我创建了简单的 HTML 模板。
当我想保存新页面时,我会丢弃原始 HTML,只需将文本和图片复制到模板中即可。这比每次都解压网站的 HTML 快得多,而且我保存的是文章内容,这才是我真正关心的。
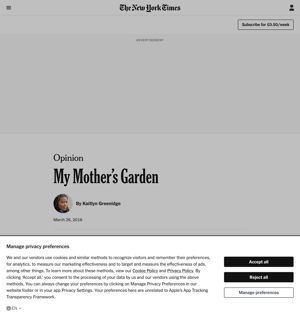
 以下是《纽约时报》的一个例子。你可以分辨出哪个页面是真正的文章,因为你必须点击两个对话框并滚动浏览广告才能看到任何文字。
以下是《纽约时报》的一个例子。你可以分辨出哪个页面是真正的文章,因为你必须点击两个对话框并滚动浏览广告才能看到任何文字。
我受到了AO3(Archive of Our Own)的启发,这是一个很受欢迎的同人小说网站。你可以下载每个故事的多种格式版本,而且他们非常重视这一点,以至于他们网站上发布的所有内容都可以下载。作者没有选择退出的权利。
从 AO3 下载的 HTML 看起来与您在浏览网页时看到的样式版本有所不同:
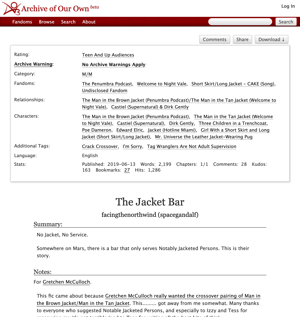

但区别只是表面的——两个文件都包含了故事的全文,这才是我真正在意的。我不在乎保存AO3的视觉快照。
大多数网站不提供纯 HTML 内容的下载,但我对 HTML 和 CSS 的了解足以让我创建自己的模板。我有十几个这样的模板,可以方便地创建我经常访问的网站的快照,比如 Medium、Wired 和《纽约时报》。
补充我现有的书签
当我决定手动构建一个新的网络档案时,我已经从几个来源收集了部分资料——Pinboard、Wayback Machine 和一些个人脚本。
我逐渐把所有书签整合到我的新档案里,每天整理几个书签:修复损坏的页面、下载丢失的文件、删除广告和其他垃圾内容。我之前有超过2000个书签,迁移它们花了大约一年的时间。现在,我已经手动检查了所有书签,并且知道我拥有一套完整的本地副本。
我编写了一些 Python 脚本来自动执行常见的清理任务,并使用正则表达式来帮助我清理大量的 HTML。这些代码过于零散和具体,不值得分享,但我还是想承认我使用了自动化功能,尽管它的级别比大多数归档工具要低。这其中涉及大量的手动工作,但并非完全手动操作。
现在我完成了,只有一个书签似乎已经彻底丢失了——Dreamwidth 上对《侠盗一号》的评论,我唯一能找到的捕获内容是内容警告插页。
我认为这是一个巨大的成功,但它也提醒我们,我们的互联网档案是多么碎片化。我的许多快照都是“弗兰肯档案”——从多个来源拼凑起来的,将相隔数年保存的文件组合在一起。
备份备份
一旦我将网站保存为文件夹,该文件夹就会像我所有其他文件一样得到备份。
我使用Time Machine和Carbon Copy Cloner将数据备份到一对外部 SSD,并使用Backblaze创建位于我家外的云备份。
为什么不使用自动化工具?
我非常喜欢用于存档网络的自动化工具,我认为它们是网络保存的重要组成部分,而且我过去使用过其中的许多工具。
ArchiveBox 、 Webrecorder和Wayback Machine等工具保存了大量网页数据,否则这些网页可能会丢失。我订阅了 Pinboard存档账户十年,每周至少搜索一次互联网档案馆。我使用过wget等命令行工具,去年我还编写了自己的工具来创建 Safari webarchives 。
当今网络档案的大小和规模只有通过自动化才有可能实现。
但自动化并非万能药,它需要权衡。为了速度和数量,你牺牲了准确性。如果存档时无人审核,页面就更有可能出现错误或缺失重要文件。
当我回顾我之前的 Pinboard 存档时,我发现很多页面没有正确存档——它们缺少图片、样式不规范,或者依赖了原始网站的 JavaScript。这些都是我非常关心的网页,我以为我已经保存了它们,但这只是一种虚假的安全感。每当我使用自动化工具存档网页时,都会发现类似的问题。
这就是为什么我决定手动创建新档案的原因——虽然速度慢得多,但它让我安心地知道我拥有每一页的完整副本。
我从网络存档中学到的东西
很多网络都是建立在现已不存在的服务之上的
我发现许多页面依赖于不再存在的第三方服务,例如:
- 照片分享网站——有些我听说过(Twitpic、Yfrog),有些我以前没听说过(phto.ch)
- 链接重定向服务 – URL 缩短器和赞助重定向
- 社交媒体分享按钮和嵌入
这意味着如果您加载实时网站,主页会加载,但图像和脚本等关键资源会损坏或丢失。
网站上线并不意味着它是正确的
一种特别隐蔽的破坏形式是页面仍然存在,但内容发生了变化。以下是一个例子:LiveJournal 上 iTunes 教程的截图被替换成了“18+ 警告”:


这种故障很难自动检测——服务器返回的是有效响应,但并非你想要的响应。这就是为什么我想用眼睛检查每一个网页,而不是依赖计算机来判断它是否已正确保存。
许多网站的重定向做得很差
我很惊讶竟然有这么多网页还存在,但原来的网址已经失效了,尤其是在大型新闻网站上。我的很多旧书签现在都返回404错误,但如果你搜索标题,就能在一个完全不同的网址上找到相关报道。
我觉得这既令人沮丧又令人失望。每次我重组这个网站,我都会设置重定向,因为我是个老派的网络迷,觉得URL很酷——但重定向不仅仅是为了让我感觉良好。保持链接有效可以让你更容易地找到你之前的内容——如果没有重定向,大多数遇到失效链接的人都会认为页面已被删除,而不会继续深入挖掘。
图像越来越容易提供,但越来越难保存
在 Web 刚诞生的时候,图像很简单。只需在 HTML 中写一个<img src="…">标签,就完成了。
如今,图片处理愈发复杂。您可以提供同一张图片的多个版本,或者控制图片的加载时间。这虽然能提升网页的效率和可访问性,但同时也增加了保存的难度。
有两个特点让我印象深刻:
-
延迟加载是一种网页在需要时才加载图像或资源的技术 – 例如,直到向下滚动才加载文章底部的图像。
使用
<img loading="lazy">可以轻松实现现代的延迟加载,但很多网站都是在该属性被广泛支持之前建立的。它们有自己的延迟加载代码,并且每个网站的行为略有不同。例如,一个页面可能会先加载一张低分辨率图片,然后用 JavaScript 将其替换为高分辨率版本。但自动化工具无法始终运行该 JavaScript,因此它们只能捕获低分辨率图片。 -
<picture>标签允许页面指定一张图片的多个版本。例如:- 页面可以向笔记本电脑发送高分辨率图片,向手机发送低分辨率图片。这样效率更高;您无需向小屏幕发送不必要的大图片。
- 页面可以根据您的配色方案发送不同的图像。如果您使用浅色模式,您可能会在白色背景上看到图表;如果您使用深色模式,您可能会在黑色背景上看到图表。
如果要保存一个页面,应该保存哪些图片?全部?还是只保存一张?如果要保存,保存哪一张?对于我的个人存档,我总是保存每张图片的最高分辨率副本,但我不确定这是否是所有情况下的最佳答案。
在现代网络上,每个人看到的页面可能都不一样——不同的人看到的页面可能有所不同。保存页面时,您需要决定要保存哪个版本。
对于收集哪些内容没有明确的界限
保存初始 HTML 页面后,您还会保存什么?
有些自动化工具会主动追踪页面上的每一个链接,以及这些页面上的每一个链接,以及之后的每一个链接,以此类推。有些自动化工具则会遵循简单的启发式方法,例如“保存从第一页开始的所有内容,但不再保存后续内容”,或“保存所有内容,直至达到固定大小限制”。
我费了好大劲才找到一套适合自己方法的启发式方法,而且我经常根据具体情况做决定。以下是两个例子:
-
我收藏了一些关于会议演讲的博客文章,作者们会嵌入他们演讲的YouTube视频。我觉得这个视频是页面的关键部分,所以我想下载它——但“下载所有嵌入内容和链接”的规则成本太高。
-
我收藏了评论科学论文的博客文章。通常,原始论文的链接不会直接指向 PDF,而是指向像 arXiv 这样的网站的登录页面。
我想保存 PDF,因为它是博客文章的重要内容,但现在我要保存距离原始文章两次点击距离的内容 – 如果将其作为通用规则,则成本会更高。
这是我很高兴手工建立档案的另一个原因——我可以根据内容和背景做出不同的决定。
你应该这么做吗?
我建议你建立一个个人网络档案。就像我保存我最喜欢的书的纸质版一样,我现在也保存我最喜欢的网页的本地副本。我知道即使原始网站消失了,我也总能读到它们。
很难推荐完全照搬我的方法。手工建立我的档案花了将近一年的时间,可能耗费了我数百个小时的空闲时间。我很高兴我做了这件事,我乐在其中,也喜欢它的结果——但这需要投入大量的时间,而且这完全是因为我拥有丰富的网站建设经验。
不要因此而灰心——网络档案不必太花哨或极端。
如果你截取一些屏幕截图、保存一些 PDF 文件,或者下载你最喜欢的小说的 HTML 版本,这些都是很有用的备份。即使原始网页消失了,你仍然有东西可以看。
如果您想扩大存档规模,可以考虑使用自动化工具。对大多数人来说,它们比手动保存和编辑 HTML 更能平衡成本和收益。但您无需手动操作,即使文件夹里只有几个文件也比什么都没有强。
当我建立我的档案库并阅读所有这些网页时,我学到了很多关于网络构建的知识。在本系列的第三部分中,我将分享这个过程教会我如何制作网站。
如果您想知道该文章何时发布,请订阅我的 RSS 提要或时事通讯!
[如果这篇文章的格式在你的阅读器中看起来很奇怪,请访问原始文章]
原文: https://alexwlchan.net/2025/personal-archive-of-the-web/?utm_source=rss