新的人工智能架构正在挑战现状。 LLaDA是一种生成文本的扩散模型。通常扩散模型会生成图像或视频(例如稳定扩散)。通过使用文本扩散,LLaDA 解决了法学硕士遇到的许多问题,例如幻觉和厄运循环。
(注:我将其发音为“yada”,“LL”是西班牙语中“y”的发音,它似乎适合语言模型,yada yada yada…)
法学硕士按顺序一个字一个字地写。另一方面,在 LLaDA 中,单词是随机出现的。在生成终止之前,还可以编辑或删除现有的单词。
示例: “解释一下人工智能是什么”
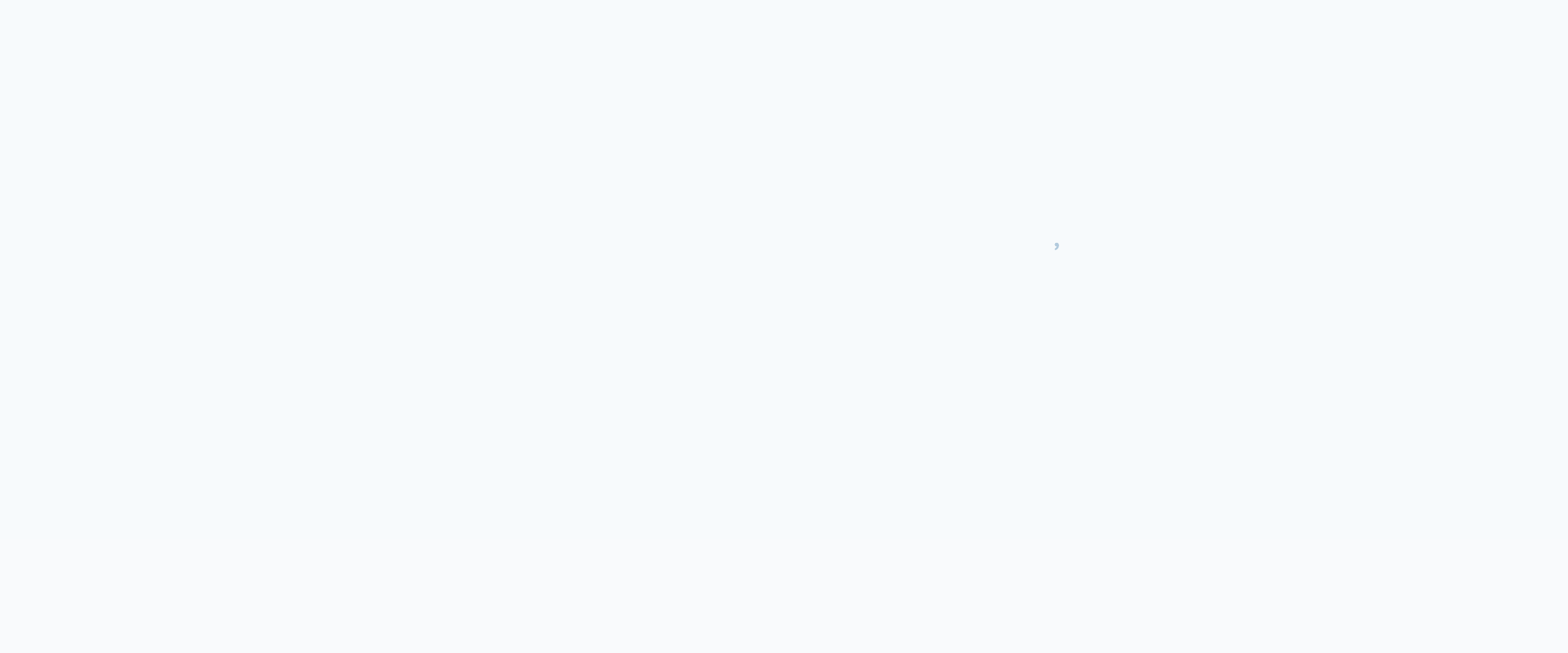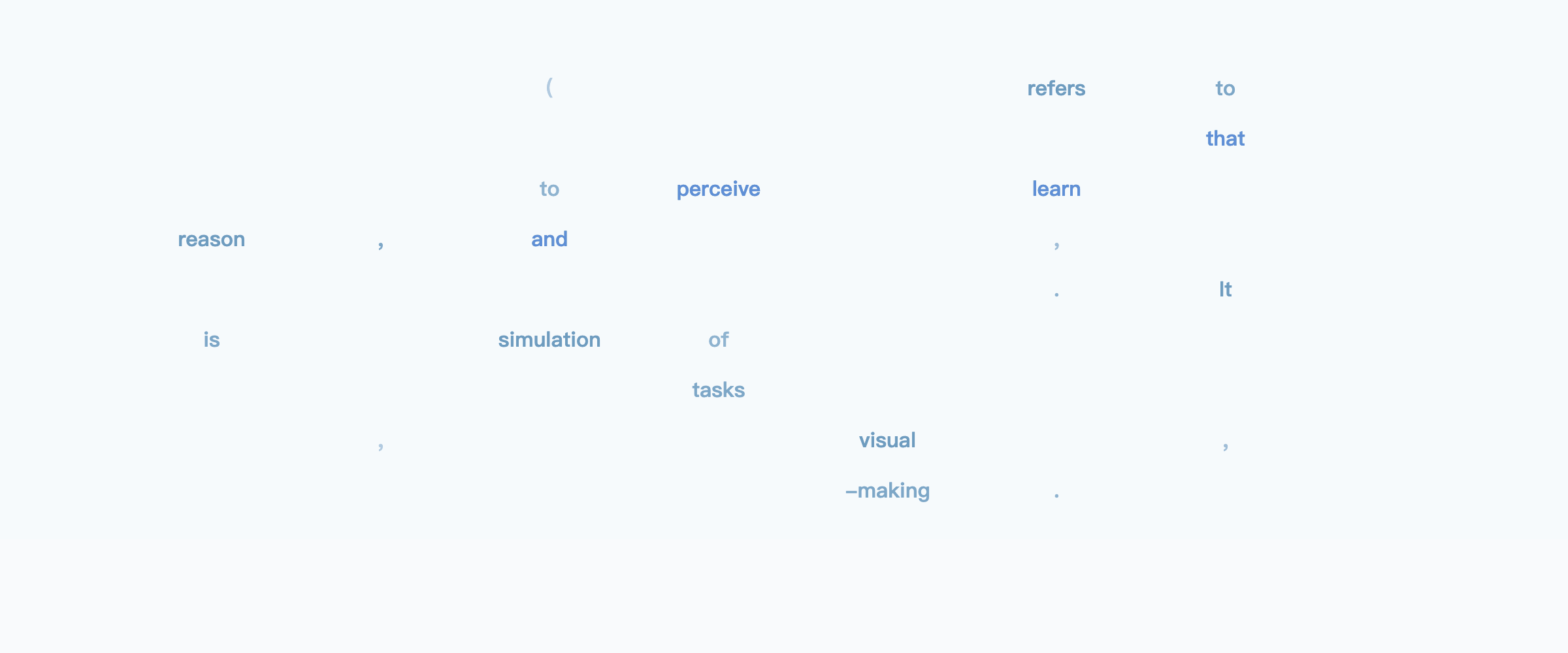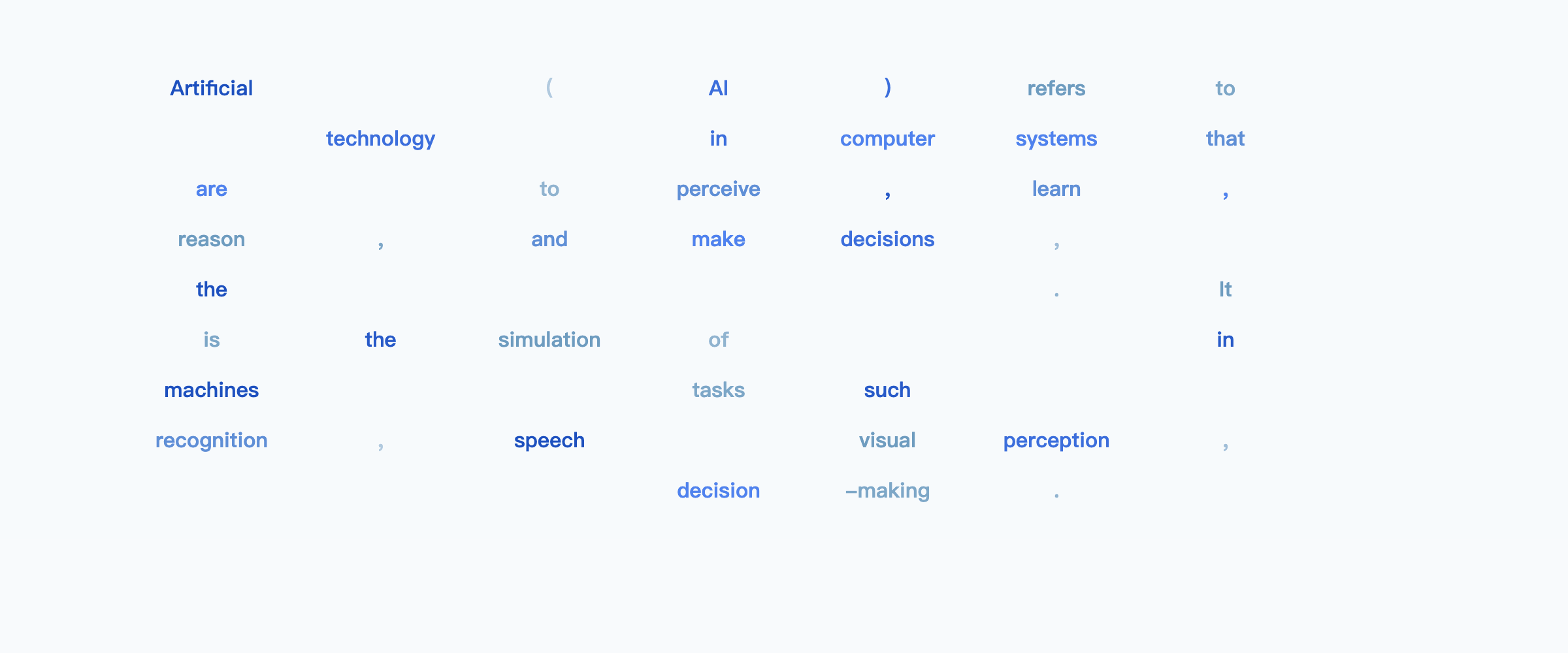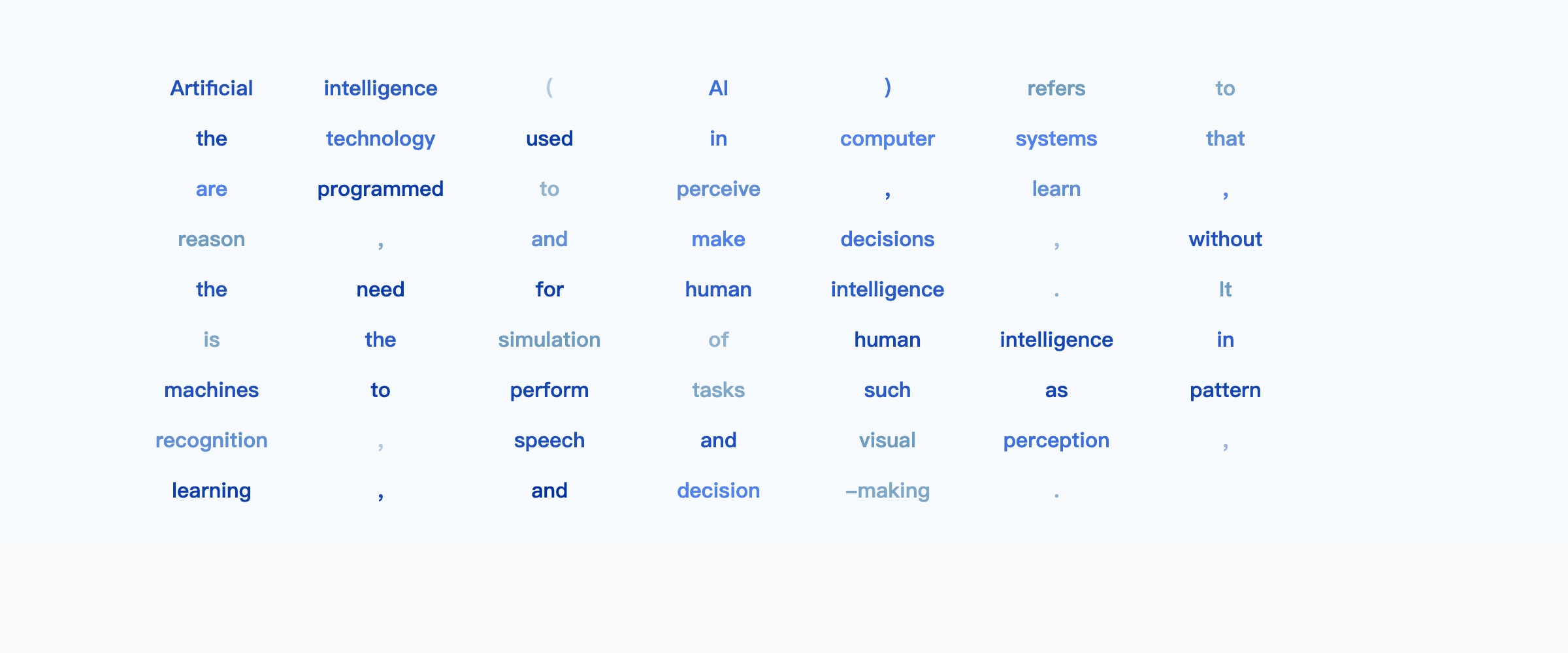
宽松地说,您可以将其视为从大纲开始,逐步在整个输出中填充细节,直到填充所有细节。
扩散与自回归语言模型
传统的法学硕士是自回归的:
- auto — self,在这种情况下输出是“self”,输出也是下一个标记的输入
- 回归——做出预测,例如“线性回归”
LLM 是自回归的,这意味着所有先前的输出都是下一个单词的输入。因此,它一次生成一个单词。
就是这么想的,一次一个字。它不能返回并“取消”一个字,它是从上到下一次性完成所有事情。扩散方法的独特之处在于它可以退出并编辑/删除推理行,有点像写草稿。
同时思考
由于它同时写入所有内容,因此本质上是并发的。在整个输出中,全球范围内同时发展了多种想法。这意味着模型更容易保持一致并保持连贯的思路。
有些问题比其他问题更有益。像雇佣协议这样的文本大多是一个层次结构的部分。如果你重新排列各个部分,合同可能会保留相同的确切含义。但它仍然需要在全球范围内保持一致和一致,这一点至关重要。
这部分引起了我的共鸣。各种方法之间显然存在权衡。当写这样的博客时,我大多是从上到下一次性写的。因为这对我来说是有意义的,这就是它的阅读方式。但当我回顾时,我会退后一步,眯着眼睛思考它以及它如何在全球范围内流动,就像操纵形状一样。
末日循环
在代理中,甚至是长时间的 LLM 聊天中,我会注意到 LLM 开始兜圈子,提出一些已经不起作用的建议,等等。LLaDA 提供了更好的全球一致性。因为它通过渐进增强而不是从左到右写入,所以它能够全局查看生成并确保输出有意义且连贯。
误差累积
由于法学硕士是自回归的,早期的错误可能会导致与现实的差距越来越大。
你有过LLM煤气灯吗?它会产生一些事实的幻觉,但随后这种幻觉就会成为它输入的一部分,因此它会假设这是事实,并会尝试让你相信幻觉的事实。
这部分归因于法学硕士的培训方式。在训练中,所有输入都是真实的,因此它学会信任它的输入。但在推理中,输入是之前的输出,它不是基本事实,但模型会按原样对待它。您可以在培训后采取一些缓解措施,但这是法学硕士必须面对的一个基本缺陷。
LLaDA 没有这个问题,因为它经过训练可以重新创建基本事实,而不是无条件地信任它。
问题:它仍然是自回归
在实践中,我不确定这种全球一致性有多大好处。例如,如果您有一个回合制聊天应用程序(例如 ChatGPT),AI 答案仍然取决于之前的输出。即使在代理中,工具调用也要求 AI 发出工具调用,然后继续(重新输入)工具输出作为输入来处理它。
因此,通过我们当前的人工智能应用程序,我们将立即有效地将这些扩散模型转变为自回归模型。
我们还开始生产推理模型( o3 、 R1 、 S1 )。在推理过程中,LLM 在给出最终答案之前,在<think/>块中使用被动的、不相信的声音,从而允许自己犯错误。
这有效地使法学硕士能够进行全球思考,以实现更好的一致性。
不是问题:固定宽度
最初我认为这只能进行固定宽度输出。但很容易看出事实并非如此。发出一个简单的<|eot|>标记来指示文本/输出的结束足以解决这个问题。
新方法
LLaDA 最大的贡献在于它简洁地展示了法学硕士的哪一部分承担着繁重的工作——语言建模。
自回归建模 (ARM) 是最大似然估计(MLE) 的一种实现。 LLaDA 表明,这在功能上与 LLaDA 使用的 [KL 散度][kl] 相同。任何对令牌之间的概率关系进行建模的方法都同样有效。
将会有更多的方法,以及新的和不同的权衡。
结论
留意这个空间。保持开放的心态。我们可能很快就会看到架构发生一些巨大的变化。也许是扩散模型,也许是其他具有一组新权衡的等效架构。