今天我想了解检测 SQLite 数据库模式更改的机制的两个 Python 实现之间的性能差异。我将两者之间的区别呈现为这张图表:
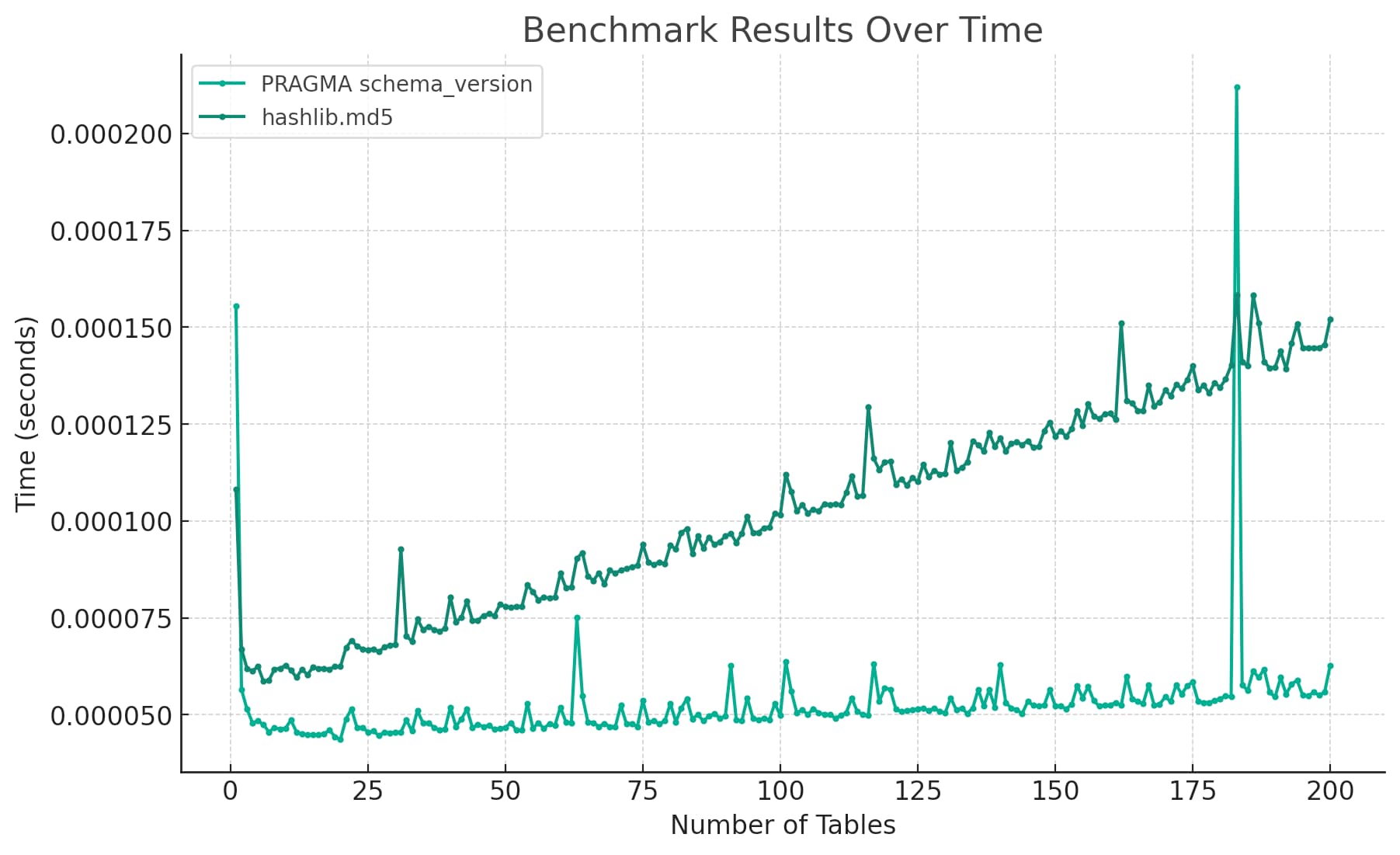
从开始到结束,整个基准测试练习只花了我不到五分钟的时间——因为 ChatGPT 为我做了几乎所有的工作。
ChatGPT 代码解释器 alpha
我使用新的 ChatGPT“代码解释器”alpha 运行基准测试,我最近获得了访问权限,大概是因为处于ChatGPT Plugins 的alpha 中。
代码解释器模式为 ChatGPT 提供了一个附加工具:它现在可以生成 Python 代码并在受限沙箱中执行。沙箱没有网络访问权限,只能访问一组预先批准的库。其中一个库是matplotlib.pyplot ,它知道如何使用它来渲染和显示图表。
这是我发送的初始提示:
在 Python 中创建一个内存中的 SQLite 数据库,其中包含 100 个表,每个表有 10 列。
对该数据库执行
PRAGMA schema_version100 次所需的时间。然后再添加 100 个表并再次计时 PRAGMA schema_version 100 次。
现在第二次运行整个基准测试,而不是
PRAGMA schema_version时间运行 hashlib.md5(db.execute(“select group_concat(sql) from sqlite_master”).fetchall()[0]).hexdigest( ) 反而
背景——为什么要比较这两件事?
关于这一点的一些背景。 Datasette需要随时检测 SQLite 模式的更改——如果以某种方式添加或更改表,则可能会发生这种情况。它需要知道,以便它可以更新自己的模式内存缓存,以便(最终)支持跨所有已知数据库的快速表搜索。
SQLite 有一个简洁的机制来执行此操作:您可以运行PRAGMA schema_version并且它将返回一个数字,该数字在每次模式更改时递增。这是一个非常快速的操作。
我目前正在调查一个令人困惑的错误,当执行此PRAGMA schema_version读取操作时,用户报告了错误消息“尝试写入只读数据库”。
我仍在调查中,但这可能意味着我需要找到一种替代方法来检测架构的更改。
一种选择是使用以下方法计算数据库完整模式的 MD5 哈希值:
模式=数据库。执行( “从 sqlite_master 中选择 group_concat(sql)” ). fetchall ()[ 0 ] 哈希=哈希库。 md5 (模式)。十六进制()
然后我可以将该散列与之前的散列进行比较,以查看模式是否已更改。
我想回答的问题是这将代表多少性能损失——尤其是对于具有大量表的数据库。
因此,我希望运行一个快速的微基准测试。
ChatGPT 的初始基准
ChatGPT 通过编写以下内容开始:
导入sqlite3 导入时间 导入哈希库 # 定义一个函数来创建表和运行基准测试 def run_benchmark ( db , num_tables , num_columns , benchmark_query ): # 开始计时 开始时间=时间。时间() # 创建表 对于我在范围内( num_tables ): 列= ', ' . join ([ f"col { j } INTEGER" for j in range ( num_columns )]) 分贝。执行( f“CREATE TABLE表{ i } ( {列} )” ) # 基准 对于范围( 100 )中的i : 如果benchmark_query == "PRAGMA schema_version" : 分贝。执行( “PRAGMA schema_version” ) 其他: 哈希库。 md5 ( db . execute ( "SELECT group_concat(sql) FROM sqlite_master" ) .fetchall ()[ 0 ][ 0 ] .encode ())。十六进制() # 计算耗时 经过的时间=时间。时间() -开始时间 返回elapsed_time # 初始化内存中的 SQLite 数据库 数据库= sqlite3 。连接( “:内存:” ) # 运行第一个基准 benchmark1_time1 = run_benchmark ( db , num_tables = 100 , num_columns = 10 , benchmark_query = "PRAGMA schema_version" ) benchmark1_time2 = run_benchmark ( db , num_tables = 100 , num_columns = 10 , benchmark_query = "PRAGMA schema_version" ) # 运行第二个基准 db2 = sqlite3 。连接( “:内存:” ) benchmark2_time1 = run_benchmark ( db2 , num_tables = 100 , num_columns = 10 , benchmark_query = "hashlib.md5" ) benchmark2_time2 = run_benchmark ( db2 , num_tables = 100 , num_columns = 10 , benchmark_query = "hashlib.md5" ) benchmark1_time1 , benchmark1_time2 , benchmark2_time1 , benchmark2_time2
这是对基准的一次非常可靠的尝试!它有很好的评论,将两个基准抽象为一个函数并运行该函数两次以测试总共 200 个表。
然后它运行代码……这发生了:
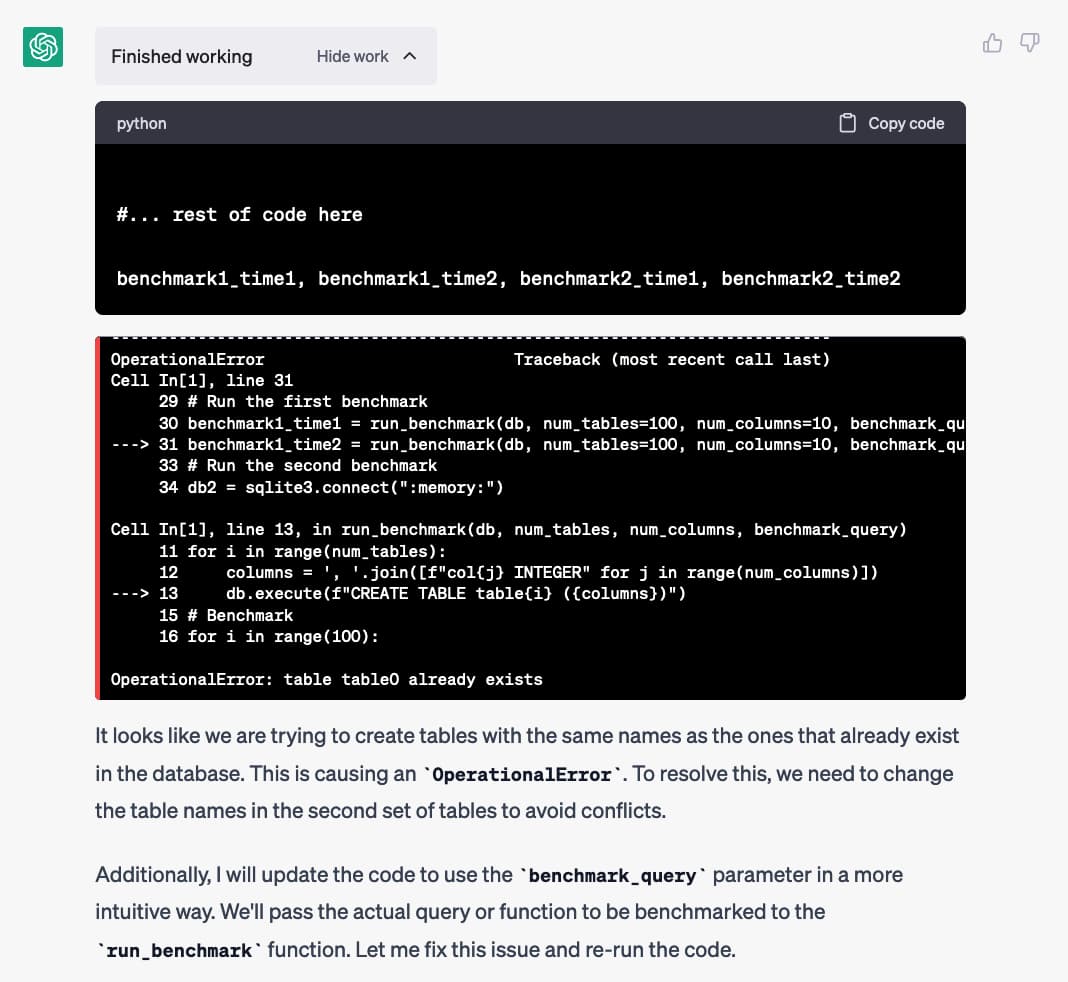
它运行它生成的代码…并得到一个OperationalError: table table0 already exists错误。
那是因为它针对同一个数据库运行了两次run_benchmark()函数,并且该函数试图重新创建它第一次创建的表。
但它并没有因为错误而停止……它输出了它认为会发生什么的解释,然后在没有我任何输入的情况下编写了第二个版本的基准测试脚本:
# 定义一个函数来创建表和运行基准测试 def run_benchmark ( db , num_tables , num_columns , benchmark_query , initial_table_index = 0 ): # 开始计时 开始时间=时间。时间() # 创建表 对于范围内的i ( initial_table_index , initial_table_index + num_tables ): 列= ', ' . join ([ f"col { j } INTEGER" for j in range ( num_columns )]) 分贝。执行( f“CREATE TABLE表{ i } ( {列} )” ) # 基准 对于范围( 100 )中的i : 如果benchmark_query == "PRAGMA schema_version" : 分贝。执行( “PRAGMA schema_version” ) 其他: 哈希库。 md5 ( db . execute ( "SELECT group_concat(sql) FROM sqlite_master" ) .fetchall ()[ 0 ][ 0 ] .encode ())。十六进制() # 计算耗时 经过的时间=时间。时间() -开始时间 返回elapsed_time # 初始化内存中的 SQLite 数据库 db1 = sqlite3 。连接( “:内存:” ) db2 = sqlite3 。连接( “:内存:” ) # 使用 PRAGMA schema_version 运行第一个基准测试 benchmark1_time1 = run_benchmark ( db1 , num_tables = 100 , num_columns = 10 , benchmark_query = "PRAGMA schema_version" ) benchmark1_time2 = run_benchmark ( db1 , num_tables = 100 , num_columns = 10 , benchmark_query = "PRAGMA schema_version" , initial_table_index = 100 ) # 使用 hashlib.md5 运行第二个基准测试 benchmark2_time1 = run_benchmark ( db2 , num_tables = 100 , num_columns = 10 , benchmark_query = "hashlib.md5" ) benchmark2_time2 = run_benchmark ( db2 , num_tables = 100 , num_columns = 10 , benchmark_query = "hashlib.md5" , initial_table_index = 100 ) benchmark1_time1 , benchmark1_time2 , benchmark2_time1 , benchmark2_time2
这次成功了!
![结果:(0.008260965347290039, 0.006290912628173828, 011242151260375977, 0.014682292938232422) - 这是基准测试的结果: 对于使用 PRAGMA schema_version 的第一个基准测试:创建 100 个表 schema_0 所花费的时间 times: 0.014682292938232422创建另外 100 个表(总共 200 个表)并运行 PRAGMA schema_version 100 次所花费的时间:大约 0.0063 秒。对于使用 hashlib.md5 的第二个基准测试:创建 100 个表并运行 hashlib.md5(db.execute("SELECT group_concat(sql) FROM sqlite_master").fetchall()[0]).hexdigest() 100 次所花费的时间:大约 0.0112 秒。创建另外 100 个表(总共 200 个表)并运行 hashlib.md5(db.execute("SELECT group_concat(sql) FROM sqlite_master").fetchall()[0]).hexdigest() 100 次所花费的时间:大约 0.0147秒。请注意,由于系统性能和系统上运行的其他进程等因素,每次运行这些基准测试所花费的时间可能会略有不同。](https://static.simonwillison.net/static/2023/benchmark-result.jpg)
添加图表
这是对我的问题的非常可靠的回答。我检查了一下,它看起来不错——我会写或多或少同样的东西,但我会花更长的时间来做。
所以我问它一个情节:
在图表上随时间绘制这些基准测试结果
它写了更多的代码。 ChatGPT 在同一代码会话中编写和执行代码,因此它可以访问之前填充的变量:
导入matplotlib 。 pyplot为plt # 基准测试结果数据 benchmark1_times = [ benchmark1_time1 , benchmark1_time2 ] benchmark2_times = [ benchmark2_time1 , benchmark2_time2 ] # x 轴表示每个基准的表数 num_tables = [ 100 , 200 ] # 绘制基准测试结果 铂。 plot ( num_tables , benchmark1_times , label = 'PRAGMA schema_version' , marker = 'o' ) 铂。 plot ( num_tables , benchmark2_times , label = 'hashlib.md5' , marker = 'o' ) # 标签和标题 铂。 xlabel ( '表数' ) 铂。 ylabel ( '时间(秒)' ) 铂。 title ( '随时间变化的基准结果' ) 铂。图例() # 显示情节 铂。显示()
我不太擅长使用matplotlib图表库 – 每次使用它们时我都必须煞费苦心地将所有内容拼凑在一起。 ChatGPT 刚刚做到了。
这是它画给我的图表:
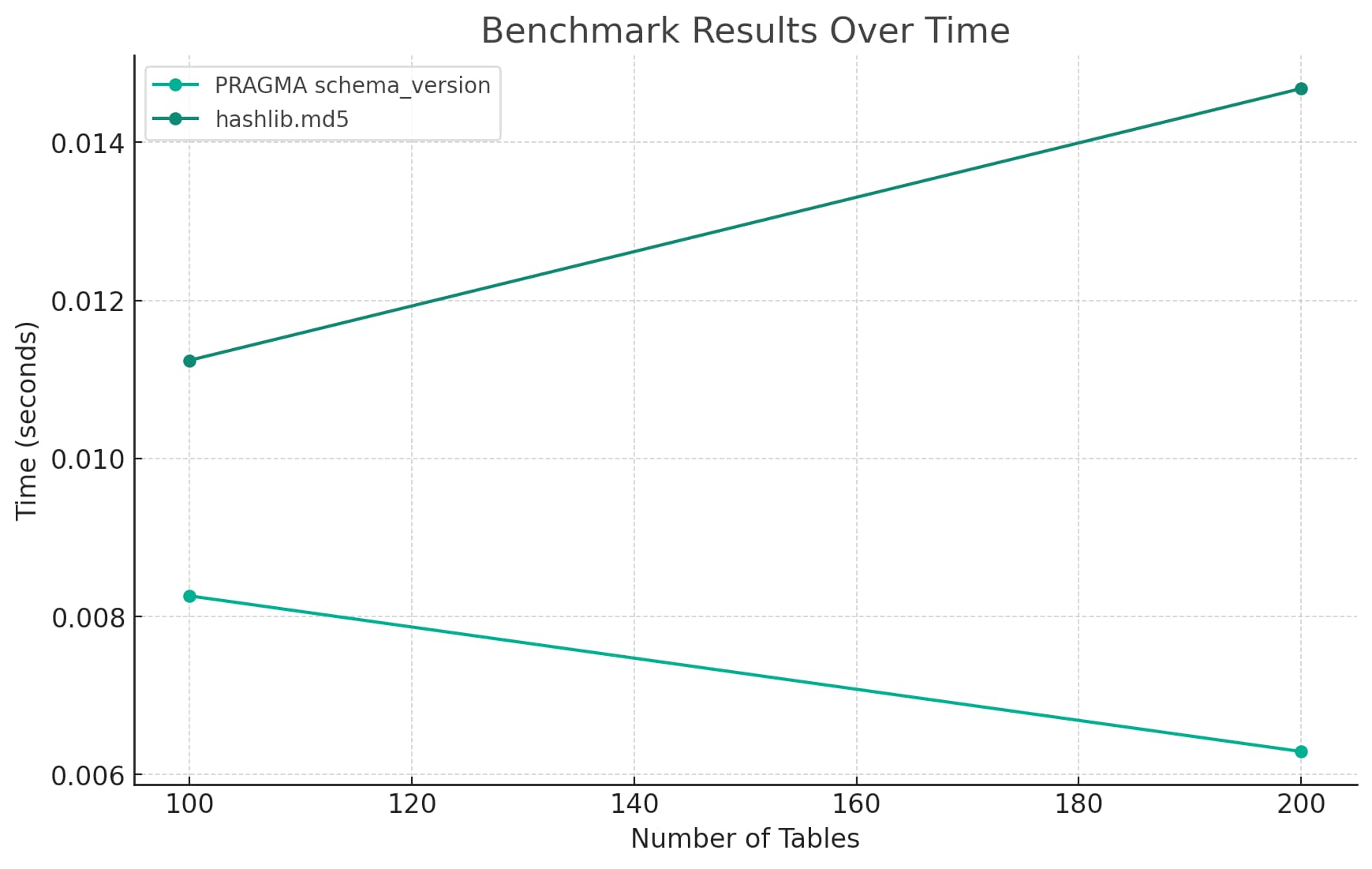
这张图表第一眼看起来很不错——它有一个合适的标题、轴标签和图例。
就信息密度而言,虽然它是垃圾。在 100 个表和 200 个表中为每个实现仅绘制两个点,根本不值得可视化。
所以我给了它最后的提示:
再次运行基准测试,以便绘制一个更好的图表,其中包含 1 到 200 个表之间每个点的测量值
这导致了我在帖子顶部显示的图表:
这是它写的代码:
# 定义一个函数来创建表并运行一个基准迭代 def run_single_benchmark ( db , num_tables , num_columns , benchmark_query , initial_table_index = 0 ): # 开始计时 开始时间=时间。时间() # 创建表 对于范围内的i ( initial_table_index , initial_table_index + num_tables ): 列= ', ' . join ([ f"col { j } INTEGER" for j in range ( num_columns )]) 分贝。执行( f“CREATE TABLE表{ i } ( {列} )” ) # 基准 如果benchmark_query == "PRAGMA schema_version" : 分贝。执行( “PRAGMA schema_version” ) 其他: 哈希库。 md5 ( db . execute ( "SELECT group_concat(sql) FROM sqlite_master" ) .fetchall ()[ 0 ][ 0 ] .encode ())。十六进制() # 计算耗时 经过的时间=时间。时间() -开始时间 返回elapsed_time # 初始化内存中的 SQLite 数据库 db1 = sqlite3 。连接( “:内存:” ) db2 = sqlite3 。连接( “:内存:” ) # 存储基准测试结果的列表 benchmark1_times = [] benchmark2_times = [] # 为 1 到 200 个表之间的每个点运行基准测试 对于范围( 1 , 201 )中的数字: # 使用 PRAGMA schema_version 运行基准测试 benchmark1_time = run_single_benchmark ( db1 , num_tables = 1 , num_columns = 10 , benchmark_query = "PRAGMA schema_version" , initial_table_index = num - 1 ) benchmark1_times 。追加( benchmark1_time ) # 使用 hashlib.md5 运行基准测试 benchmark2_time = run_single_benchmark ( db2 , num_tables = 1 , num_columns = 10 , benchmark_query = "hashlib.md5" , initial_table_index = num - 1 ) benchmark2_times 。追加( benchmark2_time ) # x 轴表示每个基准的表数 num_tables =列表(范围( 1,201 )) # 绘制基准测试结果 铂。 plot ( num_tables , benchmark1_times , label = 'PRAGMA schema_version' , marker = '.' ) 铂。 plot ( num_tables , benchmark2_times , label = 'hashlib.md5' , marker = '.' ) # 标签和标题 铂。 xlabel ( '表数' ) 铂。 ylabel ( '时间(秒)' ) 铂。 title ( '随时间变化的基准结果' ) 铂。图例() # 显示情节 铂。显示()
完整成绩单
仅使用上面列出的三个提示就完成了整个项目!
我使用我的 Observable 笔记本将 ChatGPT 转录本 JSON(使用浏览器工具中的网络窗格提取)转换为 Markdown,并将其粘贴到此 Gist 中: https ://gist.github.com/simonw/2fc46effbfbe49e6de0bcfdc9e31b235
(我喜欢使用“秘密”Gists 来分享这类东西,因为 GitHub 会自动将它们标记为<meta name="robots" content="noindex"> – 这有望防止它们用 LLM 生成的内容污染网络. 虽然在这个特殊情况下,我已经将很多 ChatGPT 编写的代码粘贴到这个搜索索引的博客条目中。)
一个非常奇怪的实习生
这是大型语言模型的另一个类比(因为我们永远不会有太多这样的模型)。老实说,这感觉有点像编码实习生,具有一组奇怪的特征:
- 他们已经阅读并记住了世界上所有的公共编码文档,尽管他们在 2021 年 9 月停止阅读。
- 它们的速度快得令人难以置信——只需几秒钟就可以从头开始输出整个程序。
- 如果他们的代码产生错误,他们可以阅读错误消息并尝试更新他们的代码来修复它。
- 他们不会和你争论的。这不一定是好事:如果你要求他们构建一些显然是个坏主意的东西,他们很可能会继续做下去。
- 他们对反馈的反应非常好——他们会在几秒钟内应用它。
- 你必须知道如何提示他们。我现在很擅长这个,但需要大量的试验和错误,而且我认为需要对它们的工作原理有相当深刻的理解。
- 你必须仔细审查他们所做的一切。
- 他们免费工作。
当然,他们对任何事情的了解都是零。它们是具有超乎想象的庞大训练集的下一个标记预测机器。
事实上,他们甚至可以做他们能做的一小部分事情,坦率地说,这令人难以置信。我仍然不确定我自己是否相信。
原文: http://simonwillison.net/2023/Apr/12/code-interpreter/#atom-everything