2020 年,最强大的众所周知的人工智能模型需要一个小型数据中心来训练。到 2029 年,由于指数趋势的连锁层,同样的工作将可以在笔记本电脑上完成,赋予我们更多的处理能力和更高效的软件。
当我们把数字放入指数堆中时,未来就不再是投机的了;在某种程度上,它已成为预定的。
阿泽姆在周末的文章中描述了这种感觉。您的手机运行 GPT-5 级型号,无论您是否在线都可以访问。代理商将以不到一美元的价格处理需要您花费数周时间进行深度工作的任务。
但是什么让我们有信心说出这些话呢?文字很容易放在页面上。为了获得更大的确定性,我们研究了人工智能系统底层功能的驱动因素:计算的可用性和模型的改进以及它们如何匹配。
我们在这些不同领域经历过的特定趋势持续下去的可能性有多大?如果他们这样做了会发生什么?
以下是详细的细分,可帮助您了解从这里到那里的路径。
计算爆炸
资本正在超越摩尔定律。人工智能基础设施,特别是装有加速器芯片的数据中心,现在代表了超大规模企业资本支出预算的最大部分。微软目前处于领先地位,已经积聚了 485,000 块 Nvidia 价值 25,000 美元的 Hopper 芯片。紧随其后的是 Meta 的约 350,000 台 H100,安装量已接近 600,000 台 H100。
这一建设先于更大规模的扩张,例如 Stargate 项目,这是一项 5000 亿美元的人工智能基础设施投资,目标是到 2029 年拥有超过 100 万个 GPU,消耗 5 GW 的电力,与高峰时期洛杉矶的电力大致相同。不仅仅是美国,沙特阿拉伯宣布成立 AI 公司Humain,AWS 和 AMD 投资 150 亿美元。这补充了18,000 个 Nvidia 最先进的 GB300 的部署。阿联酋已经表达了自己的雄心。
专门用于训练前沿人工智能模型的计算的加速增长超越了摩尔定律历史上观察到的轨迹。就上下文而言,估计仅 Grok-3 的训练次数约为 4-5 × 10²⁶ FLOPS,大约是 GPT-3 使用的计算量的 1,300-1,600 倍。最近进步的速度和规模是非凡的。
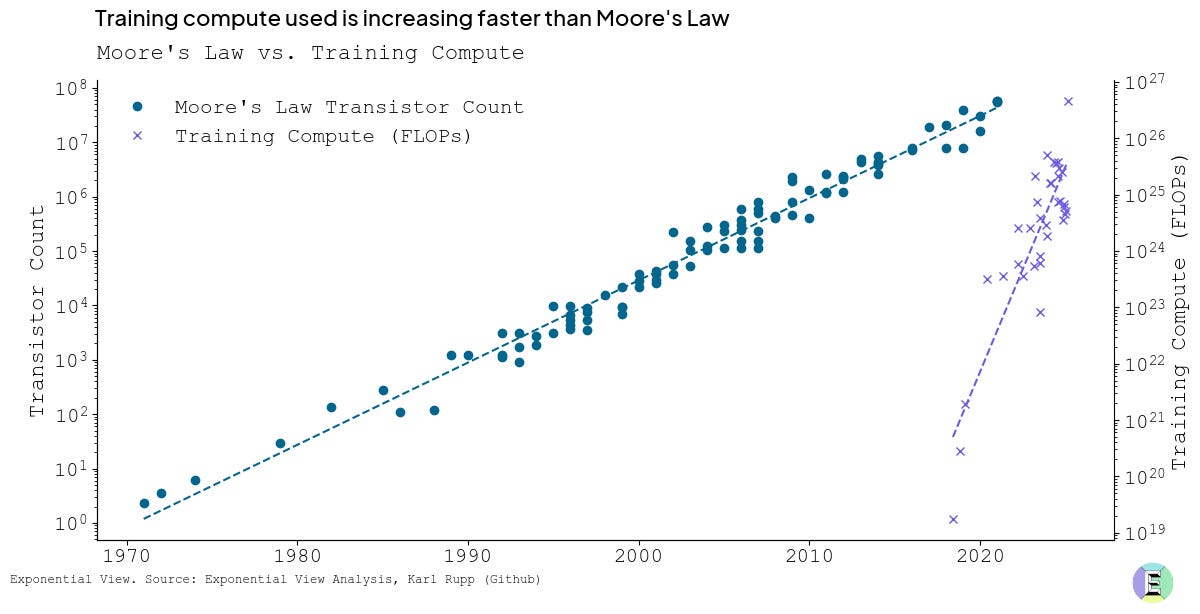
研究小组发现,计算训练每 5.4 个月就会翻一番,大大超过了传统摩尔定律 18 个月的翻倍间隔。这是在考虑这些模型的后期训练所需的额外计算以微调其能力和“个性”之前的。
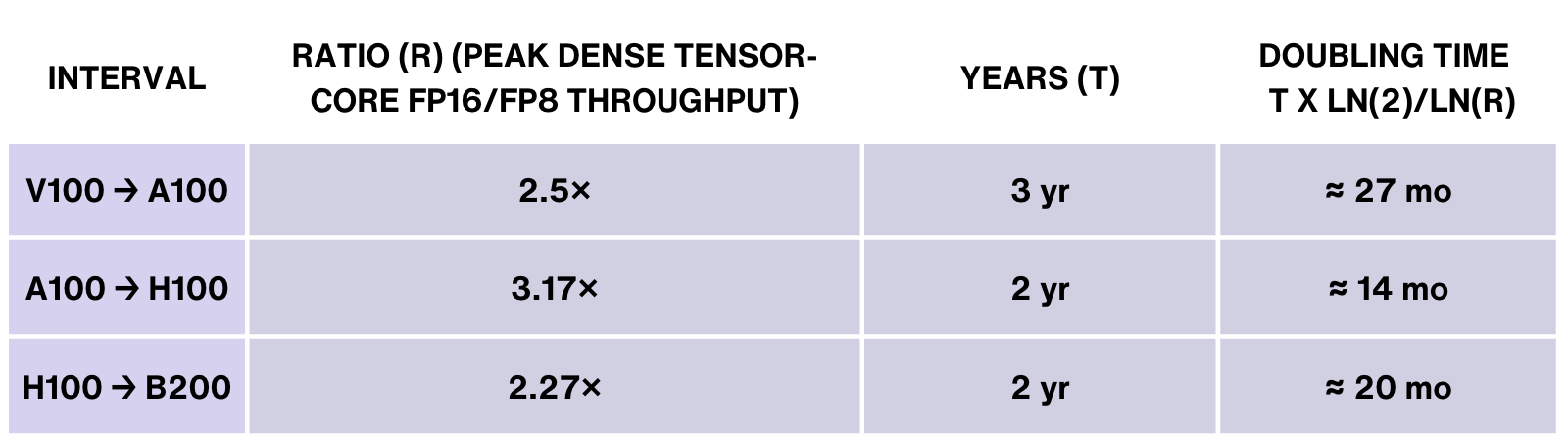
硅经济也保持指数增长。每 18 个月,每一代 GPU 的性能几乎翻倍。 Nvidia 最新的 Blackwell B200 芯片的吞吐量是上一代 Hopper H100 的 2.5 倍。
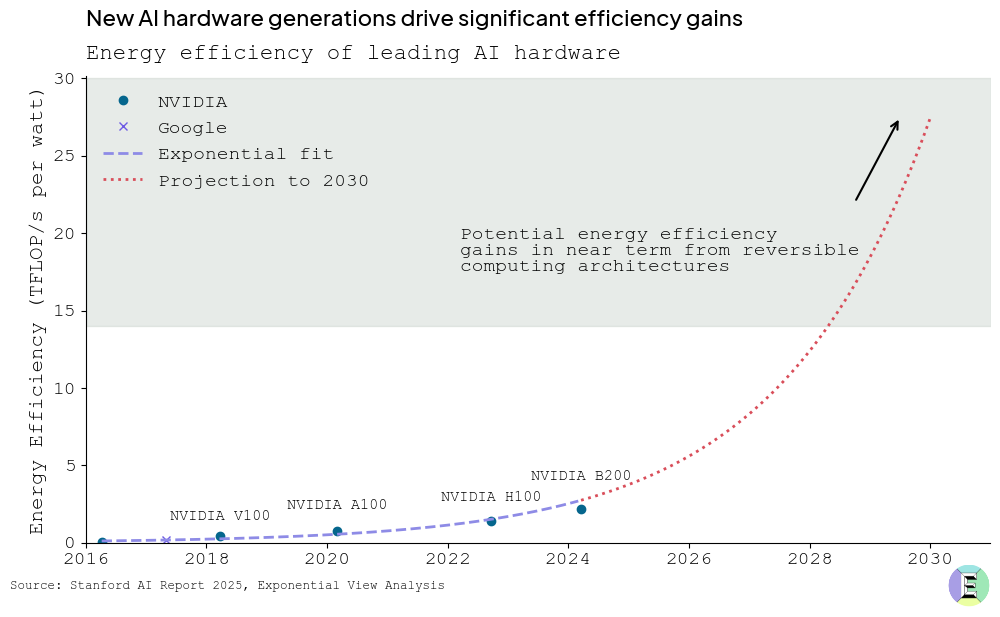
由于计算硬件和效率的不断改进,人工智能系统将变得更加节能。到 2020 年代末,每瓦浮点运算数量 (FLOP/Watt)(衡量系统执行计算效率的指标)与 2020 年的水平相比可能会提高 35 倍。该预测将 Nvidia A100 芯片(2020 年基准)的效率与 2030 年的预期进步进行了比较,考虑到 2020 年代末可逆计算架构的历史趋势和潜在解锁。
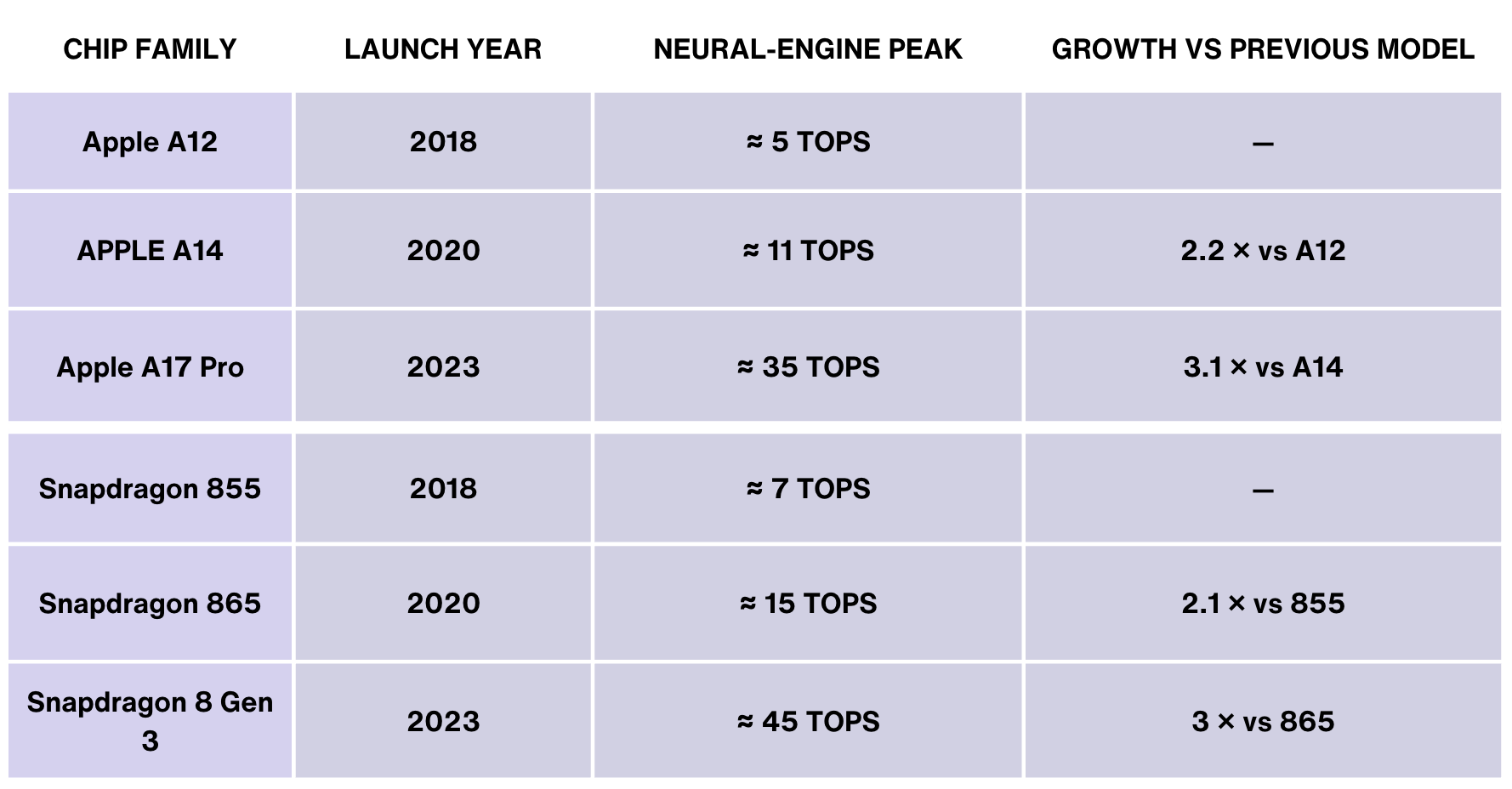
我们可以通过关键的拐点来追踪这一轨迹,例如 Nvidia 在 2024 年推出的 H100 以及即将推出的 Vera Rubin 和 Feynman 架构。预计到 2030 年,这些连续的 GPU 世代将累计推动计算可用性增加 2,000 倍。
这种快速进步不仅限于数据中心。笔记本电脑和智能手机的设备计算能力也在不断加速,大约每两年翻一番。
如果目前的趋势持续下去,到 2027 年,消费类笔记本电脑中的计算能力可能会与 2020 年 A100 GPU 的推理性能相媲美,并将曾经精英的人工智能功能带入日常个人设备中。
算法效率革命
除了硬件的进步之外,人工智能模型本身也变得更加高效。研究表明,2012 年至 2023 年间,达到固定性能水平所需的计算量大约每八个月减少一半。
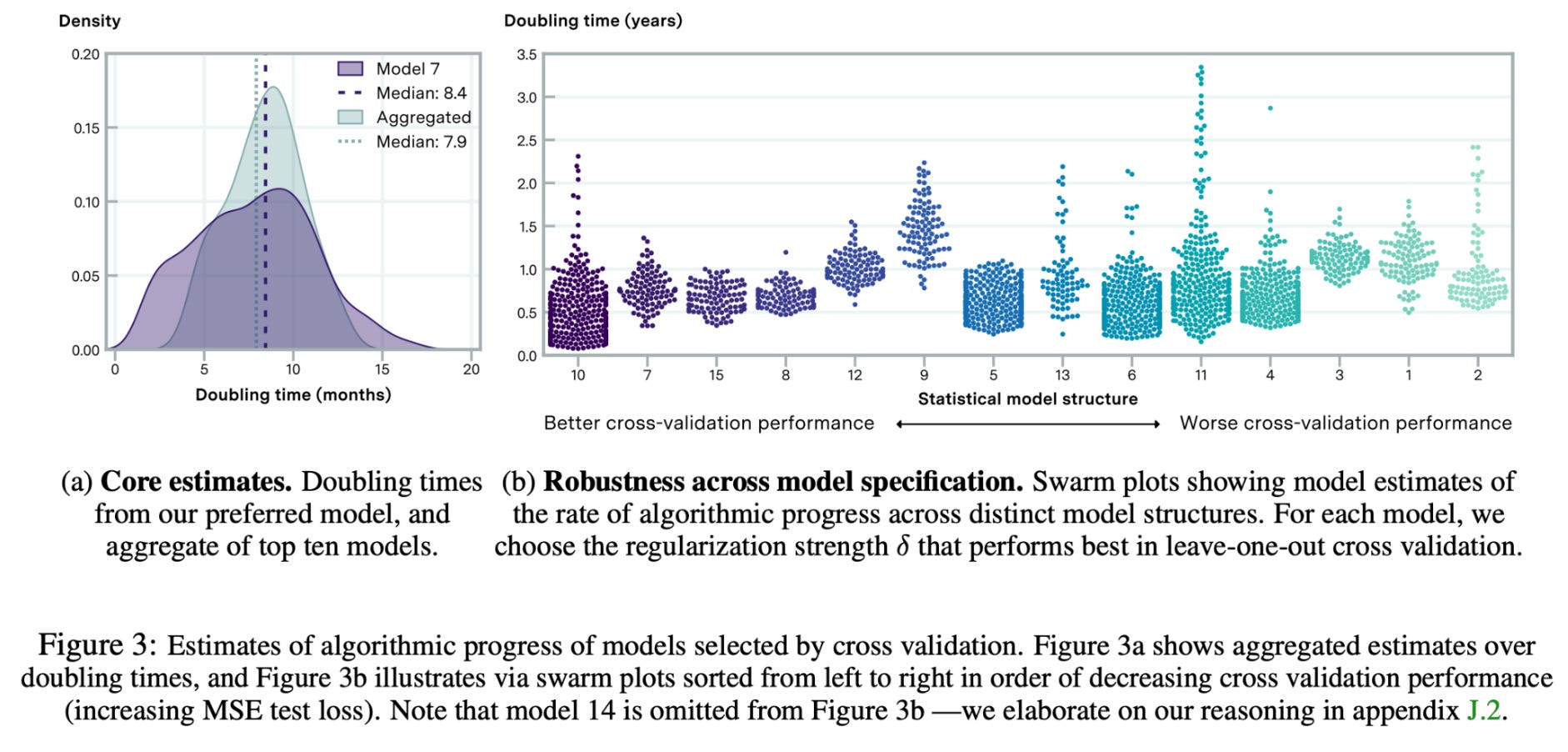
最近的估计来自表明这种趋势正在持续,效率现在每年提高三倍。