当你查询 AI 时,它会收集相关信息来回答你。
但是,模型需要多少信息?
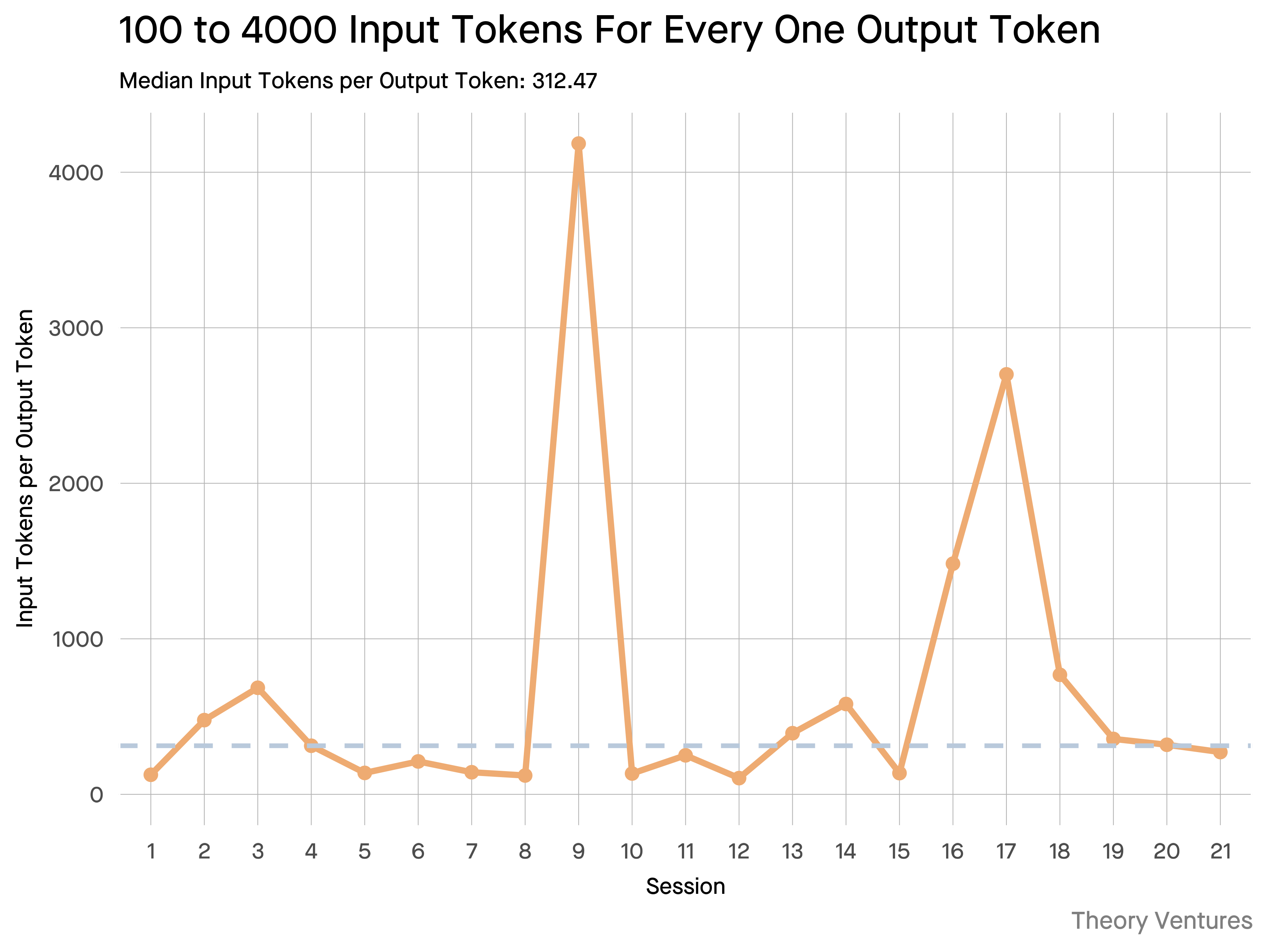
与从业者的对话揭示了他们的直觉:输入比输出大约大约 20 倍。
但是我使用Gemini 工具命令行界面进行实验,输出详细的令牌统计信息,结果显示其值要高得多。
平均 300 倍,最高可达 4000 倍。
这就是为什么这种高投入产出比对于任何使用人工智能进行构建的人来说都很重要:

成本管理的关键在于输入。由于 API 调用按令牌计费,300:1 的比例意味着成本取决于具体情况,而非答案。这种定价机制适用于所有主流模型。
在OpenAI 的定价页面上,GPT-4.1 的输出代币价格是输入代币的 4 倍。但当输入量增加 300 倍时,输入成本仍然占总费用的 98%。
延迟是上下文大小的函数。决定用户等待答案时间的一个重要因素是模型处理输入所需的时间。
它重新定义了工程挑战。这一观察证明了,利用法学硕士进行构建的核心挑战不仅仅是提示,而是情境工程。
关键任务是构建高效的数据检索和上下文 – 制作可以找到最佳信息并将其提炼为尽可能最小的令牌占用空间的管道。
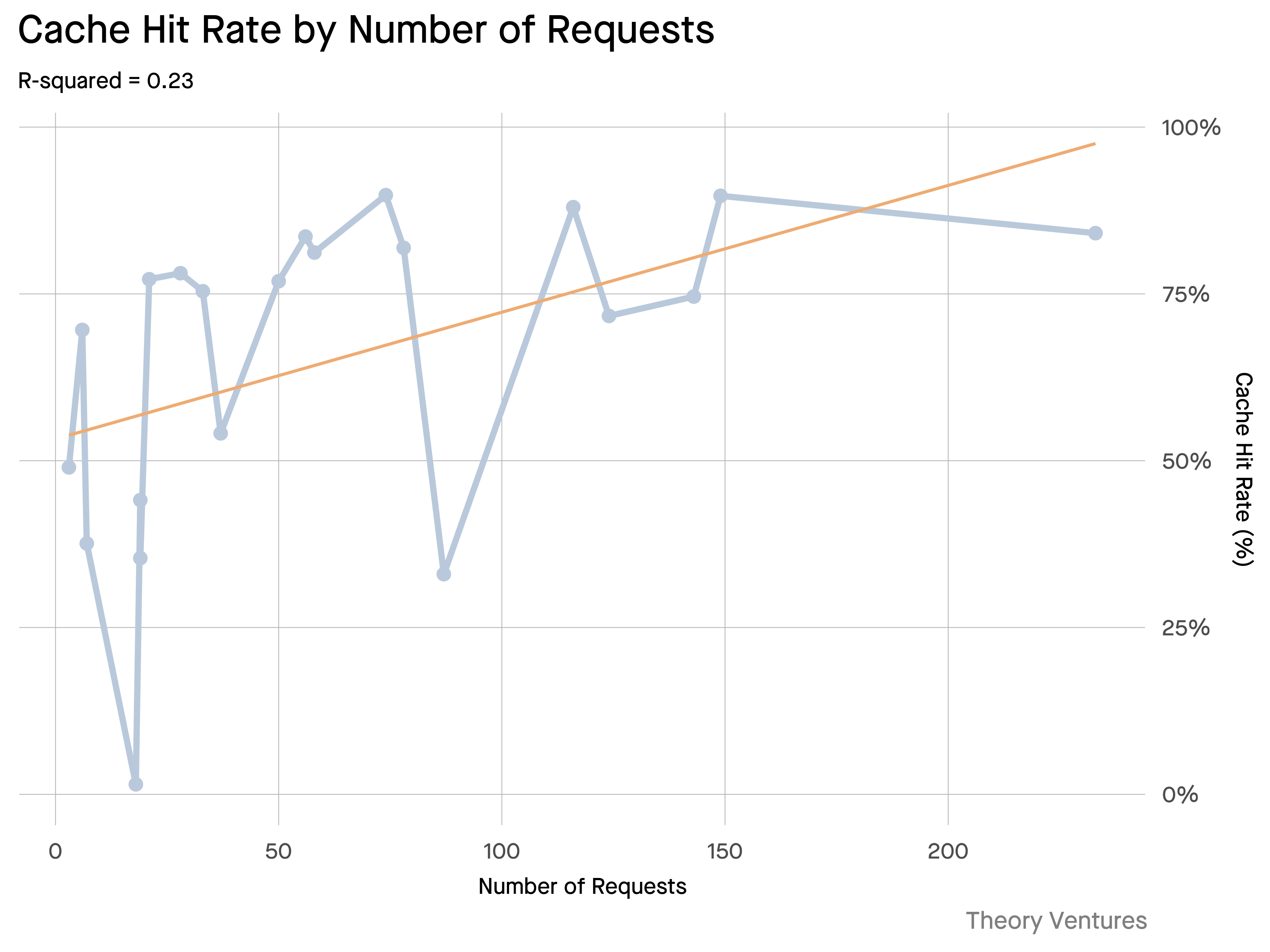
缓存成为关键任务。如果 99% 的 token 都包含在输入中,那么为频繁检索的文档或常见查询上下文构建一个健壮的缓存层,就从“锦上添花”变成了构建经济高效且可扩展产品的核心架构要求。

对于开发人员来说,这意味着专注于输入优化是控制成本、减少延迟以及最终构建成功的人工智能产品的关键杠杆。