如果您曾经使用过 GPT-3 或 ChatGPT,您可能已经想过如果您可以将它们指向特定的当前文本或文档集合并将其用作其输入的一部分,那将是多么有用用于回答问题。
事实证明,有一个巧妙的技巧可以做到这一点。我一直在尝试使用我的Datasette Web 应用程序作为快速原型制作平台来尝试使用自定义 SQL 函数的新 AI 技术。
以下是如何做到这一点:
- 针对您的文档运行文本搜索(或语义搜索,稍后描述)以查找看起来可能与用户问题相关的内容
- 抓取该内容的摘录并将它们粘合在一起成为一个文本块
- 构造一个由该文本组成的提示,后跟“给定上述内容,回答以下问题:”和用户的问题
- 通过GPT-3 API发送整个内容并查看返回的内容
我称之为语义搜索答案模式。
这是一种提示工程形式(因此容易受到提示注入攻击,所以请记住这一点)。您需要将您的整体提示符合 GPT-3 的代币限制,目前是 4,000 个代币。令牌或多或少与单词相同。
在本文中,我将展示如何使用 SQLite、Datasette 和一些用 Python 编写的自定义 SQL 函数和工具来实现上述模式。
首先,一些演示
我已经在我的博客上实现了这种模式——20 多年前的 3,000 篇文章。我使用一些调用 OpenAI API 的自定义 SQLite SQL 函数来构建它。
首先,我对我的博客进行了一些问答示例:
刮丸器有什么作用?
Shot-scraper 是一种命令行工具,可帮助自动执行截取网页屏幕截图并使用 JavaScript 从中抓取数据的过程。通过在 YAML 文件中定义它们,它可用于获取一次性屏幕截图或以可重复的方式获取多个屏幕截图。它还可用于在页面上执行 JavaScript 并返回结果值。
shot-scraper是我在 2022 年发布的工具——在 2021 年 GPT-3 培训截止日期之后。这是一个非常好的总结——我认为比我自己写的关于shot-scraper任何东西都好。
西蒙去过哪些博物馆?
西蒙去过皮特河博物馆、大英博物馆、科学博物馆、自然历史博物馆、V&A、维多利亚和阿尔伯特博物馆以及帕索罗布尔斯的先锋博物馆。他还参观了自然历史博物馆的巨型乌贼和精神建筑中查尔斯·达尔文的收藏品。
这是完全正确的,尽管我在我的博客上谈论的博物馆要多得多。
您可以使用 GitHub Actions 做哪些非常规的事情?
- 使用 cookiecutter 和 GitHub Actions 为 GitHub 存储库模板创建动态内容
- 使用 GitHub Actions 自动执行重复性任务,例如代码检查、测试和部署
- 在 GitHub Actions 中运行预定的爬虫
- 在存储库分叉时使用 GitHub Actions 触发 webhook 调用
- 使用 GitHub Issues 和 GitHub Actions 创建自动问题跟踪系统
- 使用 Whisper 和 GitHub Actions 从在线视频中自动提取字幕和文字记录。
我的一些相关帖子:
- 使用 cookiecutter 和 GitHub Actions 的 GitHub 存储库模板的动态内容
- Git 抓取:通过抓取到 Git 存储库来跟踪随时间的变化
- 使用 Whisper 和 GitHub 问题/操作对在线视频运行字幕提取的工具
不过,我从未写过任何关于触发 webhook 调用或问题跟踪系统的内容,因此该列表中的 4 和 5 有点可疑。
电线杆顶端的灰色大盒子是什么?它有什么作用?
电线杆顶部的灰色大盒子很可能是变压器。变压器用于将沿着电线杆运行的高压线路的电压降到用于为家庭和企业供电的低压线路。
包括这个是因为我从来没有在我的博客上写过任何与变压器和电线杆相关的东西。这表明,在缺乏有用上下文的情况下,GPT-3 将完全自行回答问题——这可能是也可能不是你想要从这个系统中得到的。
自己试试看
如果您想自己尝试一下,您需要从 OpenAI 获取您自己的 API 密钥。我不想为使用我的博客作为 GPT-3 提示答案的免费来源的人买单!
您可以在这里注册一个。我相信他们仍在运行免费试用期。
现在转到此页面:
https://datasette.simonwillison.net/simonwillisonblog/answer_question?_hide_sql=1
您需要粘贴您的 OpenAI 密钥。我没有在任何地方记录这些,并且表单将它们存储在 cookie 中,以避免通过 GET 查询字符串传输它可能会意外记录在某个地方。
然后输入您的问题,看看会返回什么!
让我们详细谈谈这一切是如何运作的。
使用嵌入的语义搜索
您可以使用您喜欢的任何搜索引擎来实现此序列的第一步 – 但有一个问题:我们鼓励用户在这里提问,这增加了他们可能在提示中包含与文档中的文档不完全匹配的文本的可能性我们的索引。
“Datasette 的主要特点是什么?”例如,可能会错过不包含“功能”一词的博客条目,即使它们详细描述了软件的功能。
我们在这里想要的是语义搜索——我们想要找到与用户搜索词的含义相匹配的文档,即使匹配的关键字不存在。
OpenAI 有一个不太知名的 API 可以在这方面提供帮助,它在 12 月份进行了一次大升级(并大幅降价):他们的嵌入模型。
嵌入是浮点数列表。
例如,考虑一个纬度/经度位置:它是两个浮点数的列表。您可以使用这些数字通过计算它们之间的距离来查找附近的其他点。
添加第三个数字,现在您可以在三维空间中绘制位置 – 并仍然计算它们之间的距离以找到最近的点。
即使我们超越了三个维度,这个想法仍然有效:您可以计算任意长度的向量之间的距离,无论它们有多少维度。
因此,如果我们可以在多维向量空间中表示一些文本,我们就可以计算这些向量之间的距离以找到最接近的匹配项。
OpenAI 嵌入模型允许您获取任何文本字符串(最多约 8,000 个字的长度限制)并将其转换为 1,536 个浮点数的列表。我们将此列表称为文本的“嵌入”。
这些数字来自复杂的语言模型。他们获取了大量的人类语言知识,并将其简化为浮点数列表——每个浮点数 4 个字节,即每个嵌入 4*1,536 = 6,144 个字节 – 6KiB。
两个嵌入之间的距离表示文本在语义上的相似程度。
这两个最明显的应用是搜索和相似性分数。
以用户的搜索词为例。计算它的嵌入。现在找到该嵌入与语料库中每个预先计算的嵌入之间的距离,并返回 10 个最接近的结果。
或者对于文档相似性:计算集合中每个文档的嵌入,然后依次查看每个文档并找到最接近的其他嵌入:那些是与它最相似的文档。
对于我的语义搜索答案实施,我使用基于嵌入的语义搜索作为找到问题的最佳匹配的第一步。然后,我将这些前 5 名匹配项组装到提示中以传递给 GPT-3。
计算嵌入
可以使用OpenAI 嵌入 API从文本计算嵌入。它真的很容易使用:
卷曲 https://api.openai.com/v1/embeddings \ -H “内容类型:应用程序/json ” \ -H "授权:不记名$OPENAI_API_KEY " \ -d ' {"input": "你的文本字符串在这里", “模型”:“文本嵌入-ada-002”} '
该文档没有提到这一点,但您可以传递一个字符串列表(根据官方 Python 库源代码, 最多 2048个)作为"input"以批量运行嵌入:
卷曲 https://api.openai.com/v1/embeddings \ -H “内容类型:应用程序/json ” \ -H "授权:不记名$OPENAI_API_KEY " \ -d ' {"输入": ["第一个字符串", "第二个字符串", "第三个字符串"], “模型”:“文本嵌入-ada-002”} '
此 API 返回的数据如下所示(有用的子集):
{
“数据” :[
{
“嵌入” :[
-0.006929283495992422 ,
-0.005336422007530928 ,
...
-4.547132266452536e-05 ,
-0.024047505110502243
],
“指数” : 0 ,
“对象” : “嵌入”
}
]
正如预期的那样,它是一个包含 1,536 个浮点数的列表。
我一直将嵌入存储为二进制字符串,使用它们的 4 字节表示将所有浮点数附加在一起。
以下是我一直在使用的微型 Python 函数:
导入结构 def解码( blob ): 返回结构。解压缩( “f” * 1536 , blob ) def编码(值): 返回结构。包( “f” * 1536 , *值)
然后我将它们存储在我的数据库中的 SQLite blob列中。
我为此编写了一个自定义工具,称为openai-to-sqlite 。我可以这样运行它:
openai-to-sqlite 嵌入 simonwillisonblog.db \
--sql '从 blog_entry 中选择 id、标题、正文' \
--表 blog_entry_embeddings
这将该表中的title和body列连接在一起,通过 OpenAI 嵌入 API 运行它们,并将结果存储在一个名为blog_entry_embeddings的新表中,其模式如下:
创建表 [blog_entry_embeddings] ( [id]整数主键, [嵌入] BLOB )
稍后我可以通过 ID 将其加入到blog_entry表中。
寻找最接近的匹配项
计算两个嵌入数组之间相似度的最简单方法是使用余弦相似度。一个简单的 Python 函数如下所示:
def cosine_similarity ( a , b ): dot_product = sum ( x * y for x , y in zip ( a , b )) magnitude_a = sum ( x * x for x in a ) ** 0.5 magnitude_b = sum ( x * x for x in b ) ** 0.5 返回点积/ ( magnitude_a * magnitude_b )
您可以通过对每一行执行比较并返回得分最高的行来蛮力查找表的最佳匹配项。
我将其作为名为openai_embedding_similarity()的自定义 SQL 函数添加到我的datasette-openai Datasette 插件中。这是一个使用它的查询:
输入为( 选择 嵌入 从 blog_entry_embeddings 在哪里 id = :entry_id ), top_n作为( 选择 ID, openai_embedding_similarity( blog_entry_embeddings 。嵌入, 输入。嵌入 )作为分数 从 blog_entry_embeddings, 输入 订购方式 分数描述 限制 20 ) 选择 分数, 博客条目。编号, 博客条目。标题 从 博客条目 在 blog_entry上加入top_n 。 id = top_n 。 ID
这将我的一个博客条目的 ID 作为输入,并返回其他条目的列表,按相似度得分排序。
不幸的是,这很慢!运行我博客中的所有 3,000 个嵌入需要超过 1.3 秒。
我做了一些研究,发现 Facebook AI 研究的FAISS是一个备受推崇的快速向量相似性计算解决方案。它具有整洁的 Python 绑定,可以使用pip install faiss-cpu ( -gpu版本需要 GPU)。
FAISS 针对内存中的索引工作。我博客的 Datasette 实例使用烘焙数据模式,这意味着只要数据发生变化,整个事物就会重新部署——因此,我可以在启动时启动一个内存中索引,而无需担心将索引作为行不断更新在数据库更改中。
所以我构建了另一个插件来做到这一点: datasette-faiss——可以配置为在启动时构建一个内存中的 FAISS 索引 againts 一个嵌入表,然后可以使用另一个自定义 SQL 函数进行查询。
这是重写为使用 FAISS 索引的上述相关条目查询:
输入为( 选择 嵌入 从 blog_entry_embeddings 在哪里 id = :entry_id ), top_n作为( 从json_each ( faiss_search( '西蒙威利森博客' , ' blog_entry_embeddings ' , 输入。嵌入, 20 ) ), 输入 ) 选择 博客条目。编号, 博客条目。标题 从 博客条目 在 blog_entry上加入top_n 。 id = top_n 。 ID
这个运行时间为 4.8 毫秒!
faiss_search(database_name, table_name, embedding, n)根据提供的embedding的距离分数,返回指定嵌入表中前n ID 的 JSON 数组。
这里的json_each()技巧是一种解决方法,因为 Python 的 SQLite 驱动程序尚未提供编写表值函数的简单方法 – SQL 函数返回表的形状。
相反,我使用json_each()将 ID 的字符串 JSON 数组从datasette_faiss()转换为我可以运行进一步连接的表。
使用嵌入实现语义搜索
到目前为止,我们只看到了用于查找相似项目的嵌入。让我们使用用户提供的查询来实现语义搜索。
这将再次需要一个 API 密钥,因为它涉及调用 OpenAI 以针对用户的搜索查询运行嵌入。
这是 SQL 查询:
选择 价值, 博客条目。标题, substr ( blog_entry.body , 0,500 ) 从 json_each( faiss_search( '西蒙威利森博客' , ' blog_entry_embeddings ' , ( 选择 openai_embedding(:查询,:_cookie_openai_api_key) ), 10 ) ) 在value = blog_entry上加入blog_entry。 ID 其中长度(合并(:查询, ' ' )) > 0
在这里试试(还有一些额外的美容技巧。)
我们在这里使用了一个新函数: openai_embedding() – 它接受一些文本和一个 API 密钥并返回该文本的嵌入。
API 密钥来自:_cookie_openai_api_key – 这是一种称为魔术参数的特殊数据集机制,可以从 cookie 中读取变量。
datasette-cookies-for-magic-parameters插件注意到这些并将它们变成一个界面,供用户填充 cookie,如前所述。
最后一个技巧:在查询中添加where length(coalesce(:query, '')) > 0意味着如果用户没有在搜索框中输入任何文本,查询将不会运行。
从语义搜索查询结果构建提示
回到我们的语义搜索答案模式。
我们需要一种方法来使用语义搜索查询的结果为 GPT-3 构建提示。
有一个大问题:GPT-3 有长度限制,并且严格执行。如果您将一个令牌传递给超过该限制,您将收到错误消息。
我们希望尽可能多地使用前五个搜索结果中的材料,为提示的其余部分(用户的问题和我们自己的文本)和提示响应留出足够的空间。
我最终用另一个自定义 SQL 函数解决了这个问题:
选择openai_build_prompt(内容, '上下文: -------------- ' , ' -------------- 鉴于上述背景,回答以下问题: ' || :问题, 500 )来自search_results
此函数用作聚合函数 – 它采用结果表并返回单个字符串。
它将要聚合的列(在本例中为content )作为第一个参数。然后它带有一个前缀和一个后缀,它们与中间的聚合内容连接在一起。
第三个参数是允许响应的令牌数。
然后该函数尝试将每个输入值截断为最大长度,该最大长度仍允许将它们全部连接在一起,同时保持在 4,000 个标记限制内。
全部加起来
有了以上所有内容,以下查询是我针对我的博客的语义搜索答案的完整实现:
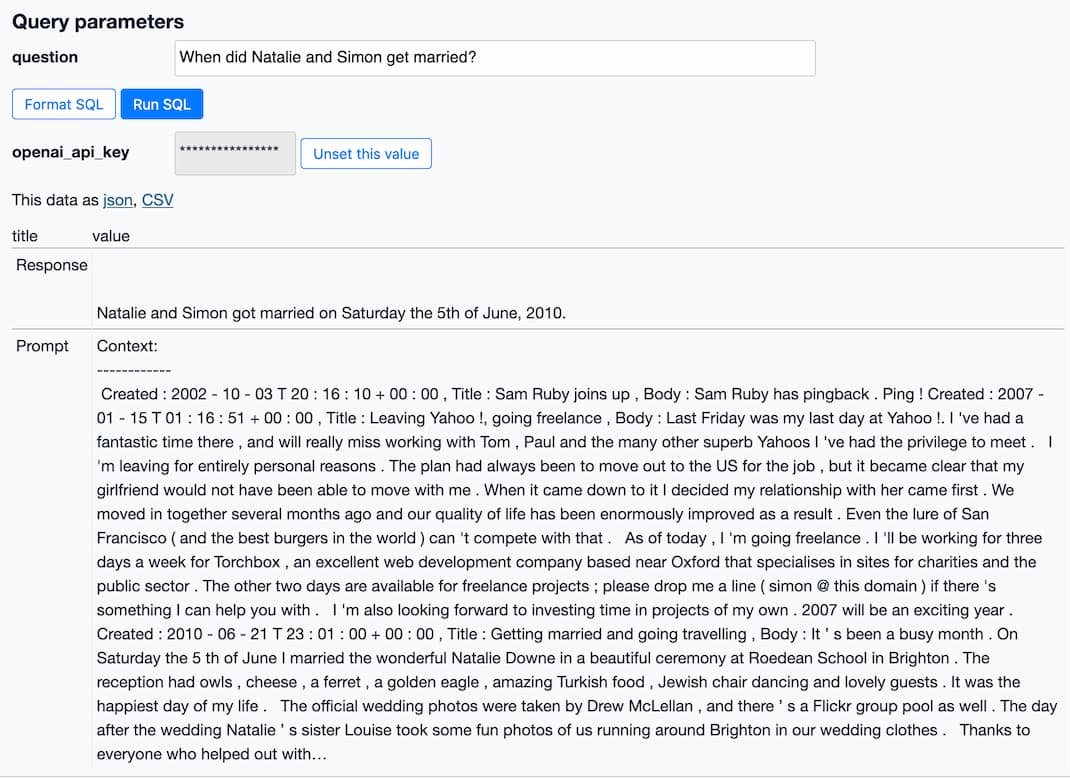
查询为( 选择 openai_embedding(:question, :_cookie_openai_api_key)作为q ), top_n作为( 选择 价值 来自json_each( faiss_search( '西蒙威利森博客' , ' blog_entry_embeddings ' , (从查询中选择q), 5个 ) ) 其中长度(合并(:问题, ' ' )) > 0 ), 文本为( 选择“已创建: ” ||创建|| ' , 标题: ' ||标题|| ' ,正文: ' || openai_strip_tags(body)作为文本 来自blog_entry where id in ( select value from top_n) ), 提示为( 选择openai_build_prompt( text , '上下文: -------------- ' , ' -------------- 鉴于上述背景,回答以下问题: ' || :问题, 500 )作为文本提示 ) 选择 '响应'作为标题, openai_davinci( 迅速的, 500 , 0 。 7 、 :_cookie_openai_api_key )作为价值 从提示 其中长度(合并(:问题, ' ' )) > 0 联合所有 选择 '提示'作为标题, 从提示提示
如您所见,我非常喜欢使用 CTE( with name as (...)模式)来组合这样的复杂查询。
The texts as ... CTE 是我从我的内容中剥离 HTML 标签的地方(使用来自datasete-openai插件的另一个自定义函数,称为openai_strip_tags() )并将其与Created和Title元数据一起组装。添加这些可以让系统更好地回答诸如“Natalie 和 Simon 什么时候结婚?”之类的问题。与正确的年份。
这个查询的最后一部分使用了一个方便的调试技巧:它通过一个union all返回两行——第一行有一个Response标签并显示来自 GPT-3 的响应,而第二个有一个Prompt标签并显示我通过的提示到模型。
下一步
有很多方法可以改进这个系统。
- 更智能的提示设计。我在这里的提示是我开始工作的第一件事——我确信有各种各样的技巧可以用来使它更有效。
- 更好地选择要包含在提示中的内容。我正在使用嵌入搜索,但随后截断到第一部分:更智能的实现会尝试裁剪出每个条目中最相关的部分,可能通过对较小的文本块使用嵌入。
- 支持 GPT-4:我听说该模型的下一个版本将有一个明显更大的代币限制,这应该会从该机制中产生更好的结果。
需要我帮助实施吗?
我计划使用此模式向我的Datasette Cloud SaaS 平台添加语义搜索和语义搜索答案。如果这听起来像是与您的组织相关的功能,请与我们联系。
原文: http://simonwillison.net/2023/Jan/13/semantic-search-answers/#atom-everything