随着网络适配器卸载功能日益复杂,英特尔的 IPU(基础设施处理单元)也随之演进。IPU 更进一步,旨在在云环境中承担各种基础设施服务,并支持传统的软件定义网络功能。基础设施服务由云运营商运行,并负责协调诸如配置虚拟机或收集指标等任务。它们不会给现代服务器 CPU 带来压力,但每个为这些任务预留的 CPU 核心都不能出租给客户。卸载基础设施工作负载还能在云提供商的代码和客户工作负载之间提供额外的隔离层。如果云提供商出租裸机服务器,那么在服务器内运行基础设施服务可能根本不可能。

英特尔即将推出的“Mount Morgan” IPU 集成了各种高度可配置的加速器以及通用 CPU 内核,旨在尽可能多地处理基础设施任务。它与其前身“Mount Evans”共享这些特性。灵活性是这些 IPU 的核心所在,它们可以作为一块功能强大的网卡连接到最多四台主机服务器,也可以独立运行,充当一台小型服务器。与 Mount Evans 相比,Mount Morgan 拥有更强大的通用计算能力、更强大的加速器以及更大的片外带宽,足以支持整个系统。
计算复杂
英特尔在其 IPU 中包含一组 Arm 核心,因为 CPU 代表着可编程性的终极体现。它们运行 Linux,让 IPU 处理各种基础设施服务,并确保 IPU 随着基础设施需求的变化而保持相关性。Mount Morgan 的计算综合体升级到 24 个 Arm Neoverse N2 核心,而 Mount Evans 则拥有 16 个 Neoverse N1 核心。英特尔并未透露确切的核心配置,但 Mount Evans 为其 Neoverse N1 核心配备了 512 KB L2 缓存,并以 2.5 GHz 的频率运行。这并非目前最快的 Neoverse N1 配置,但仍然不容小觑。Mount Morgan 当然更进一步。Neoverse N1 是一个 5 宽乱序核心,具有 160 个 ROB 条目、充足的执行资源和一个非常强大的分支预测器。每个核心都比 Neoverse N1 有了显著的升级。 24 个 Neoverse N2 核心足以处理一些生产服务器工作负载,更不用说基础设施服务的集合了。

Mount Morgan 的内存子系统升级至四通道 LPDDR5-6400,以满足更强大的计算综合体的需求。Mount Evans 则采用三通道 LPDDR4X-4267 配置,并连接 48 GB 板载内存。如果英特尔保持每个通道相同的内存容量,Mount Morgan 将拥有 64 GB 板载内存。假设英特尔的演示指的是 16 位 LPDDR4/5(X) 通道,那么 Mount Morgan 将拥有 51.2 GB/s 的 DRAM 带宽,而 Mount Evans 则为 25.6 GB/s。如果英特尔指的是 LPDDR 芯片的 32 位数据总线,而不是通道,那么这些数字将会翻倍。32 MB 系统级缓存有助于减轻内存控制器的压力。与上一代产品相比,英特尔并未增加缓存容量,因此 32 MB 可能在命中率和芯片面积要求之间取得了良好的平衡。系统级缓存是真正的系统级缓存,这意味着除了 CPU 内核之外,它还为 IPU 的各种硬件加速块提供服务。
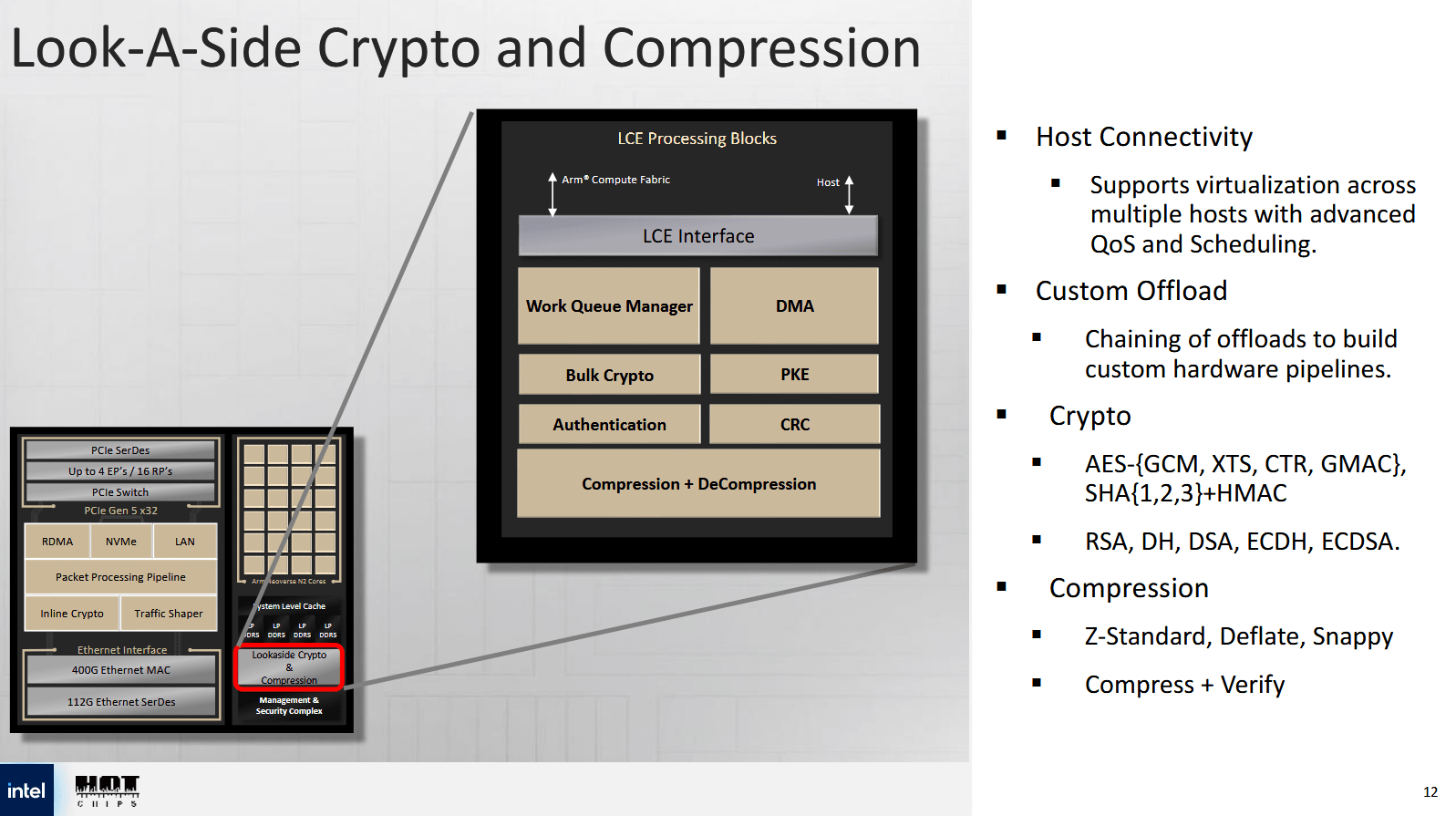
旁路加密和压缩引擎 (LCE) 位于计算复合体内部,与英特尔的 Quickassist (QAT) 加速器系列共享血统。英特尔表示,LCE 在 QAT 的基础上针对 IPU 用例进行了多项升级。但最显著的升级或许是获得非对称加密支持,而 Mount Evans 的 LCE 模块明显缺少这项功能。RSA 和 ECDHE 等非对称加密算法用于 TLS 握手,而许多服务器 CPU 上的特殊指令无法加速这些算法。因此,当服务器每秒处理大量连接时,非对称加密会消耗大量的 CPU 算力。这是 QAT 的一个引人注目的用例,很高兴看到 Mount Morgan 也实现了这一点。LCE 模块还支持对称加密和压缩算法,这些功能继承自 QAT。
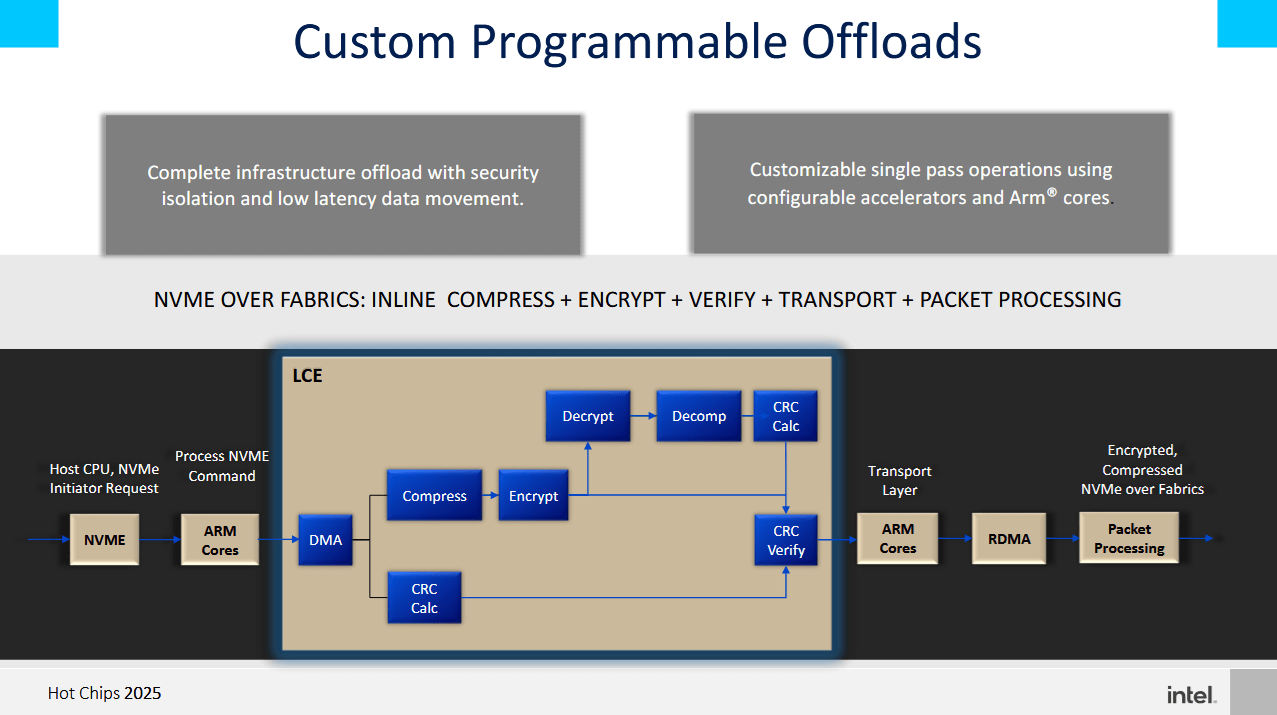
LCE 中的可编程 DMA 引擎允许云提供商将数据作为硬件加速工作流程的一部分进行移动。英特尔提供了一个访问远程存储的示例工作流程,其中 LCE 负责移动、压缩和加密数据。IPU 网络子系统中的其他加速器模块则负责完成该过程。
网络子系统
网络带宽和卸载是IPU的核心功能,其重要性不容低估。云服务器需要高网络和存储带宽。这两者通常是同一事物的两面,因为云提供商可能会使用通过数据中心网络访问的独立存储服务器。Mount Morgan拥有400 Gbps的以太网吞吐量,是Mount Evans 200 Gbps的两倍。
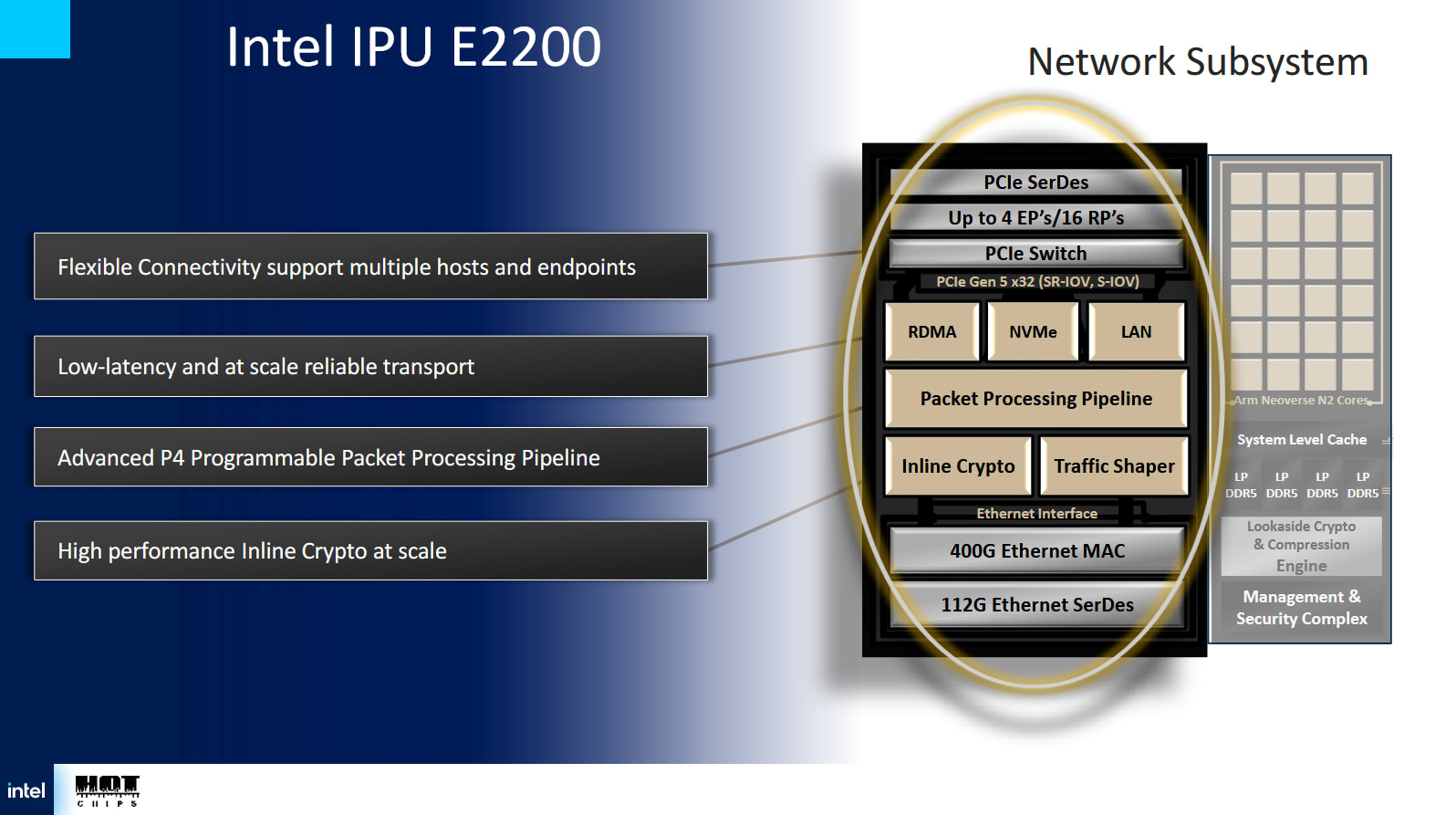
Mount Morgan 秉承其智能网卡 (NIC) 的血统,使用大量内联加速器来处理云网络任务。一个基于 P4 的可编程数据包处理流水线(称为 FXP)位于网络子系统的核心。P4 是一种数据包处理语言,允许开发人员表达他们想要的数据包处理方式。FXP 流水线内的硬件模块与 P4 的需求紧密匹配。解析器解码数据包头,并将数据包转换为下游阶段能够理解的表示形式。下游阶段可以检查精确匹配或通配符匹配。最长前缀匹配也可以在硬件中执行,这对于路由非常有用。
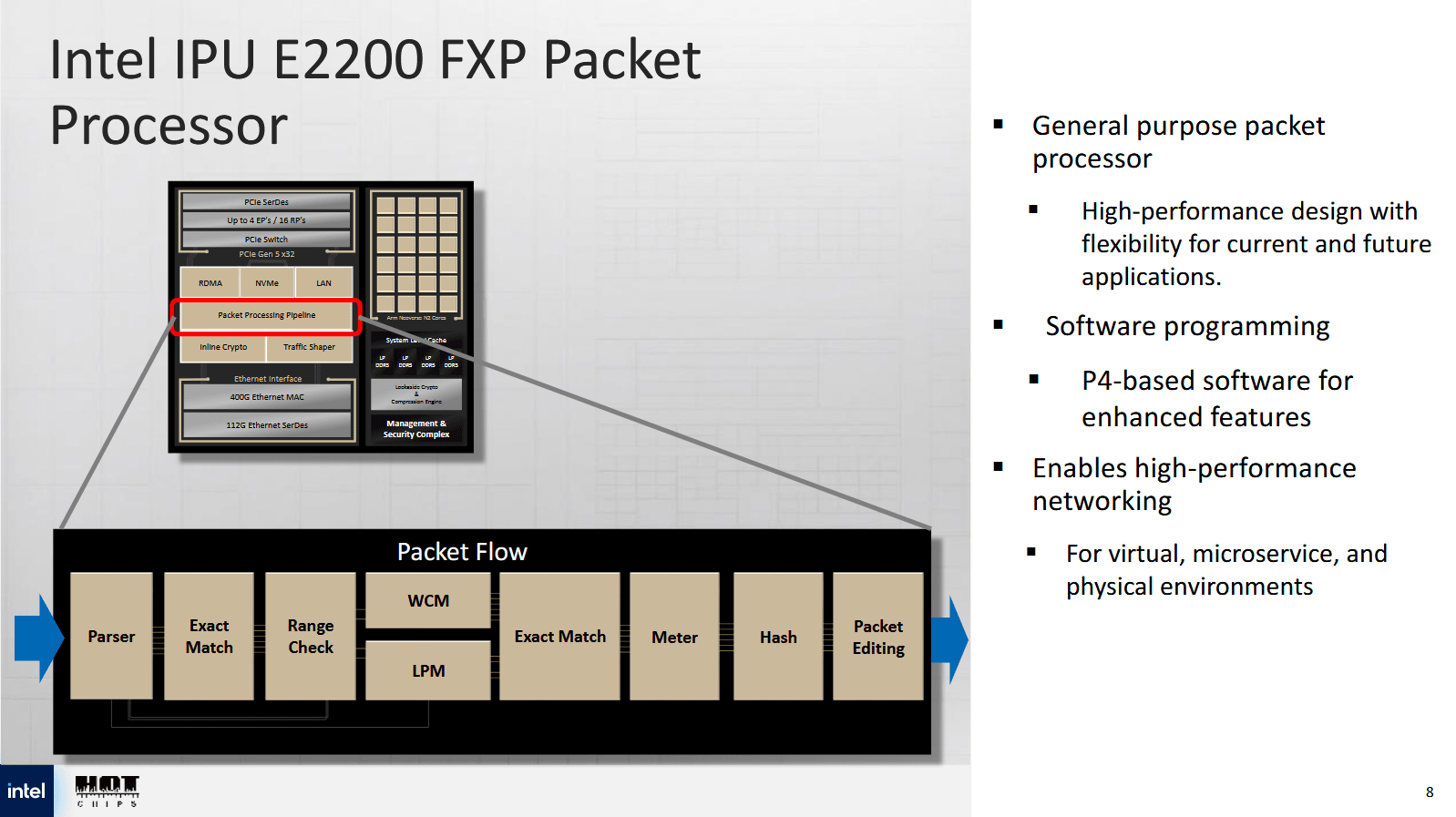
FXP 可以每个周期处理一个数据包,并且可以配置为每个数据包执行多次处理。英特尔给出了一个示例,其中一次处理过程处理数据包的外层,以执行解封装并根据访问控制列表进行检查。第二次处理过程可以查看数据包的内部层,并执行连接跟踪或实施防火墙规则。
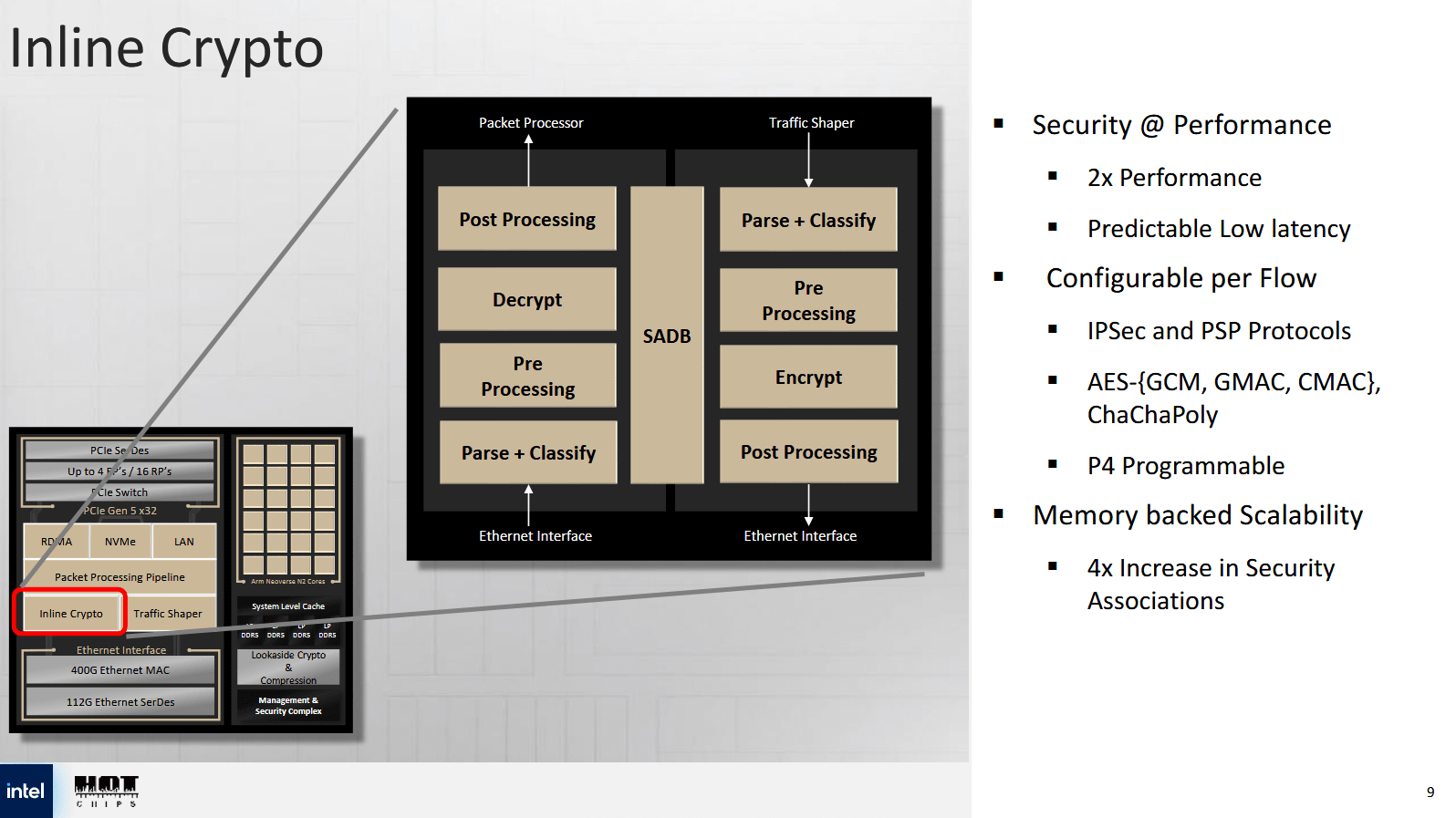
网络子系统内也包含一个内联加密块。与计算复合体中的 LCE 不同,该加密块专用于数据包处理,并专注于对称加密。它包含自己的数据包解析器,可以终止 IPSec 和 PSP 连接,并在硬件中执行 IPSec/PSP 功能,例如防重放窗口保护、序列号生成和错误校验。IPSec 用于 VPN 连接,这对于客户连接到云服务至关重要。PSP 是 Google 用于加密 Google 云内部数据传输的协议。与 Mount Evans 相比,该加密块的吞吐量翻了一番,达到 400 Gbps,并支持 6400 万个数据流。
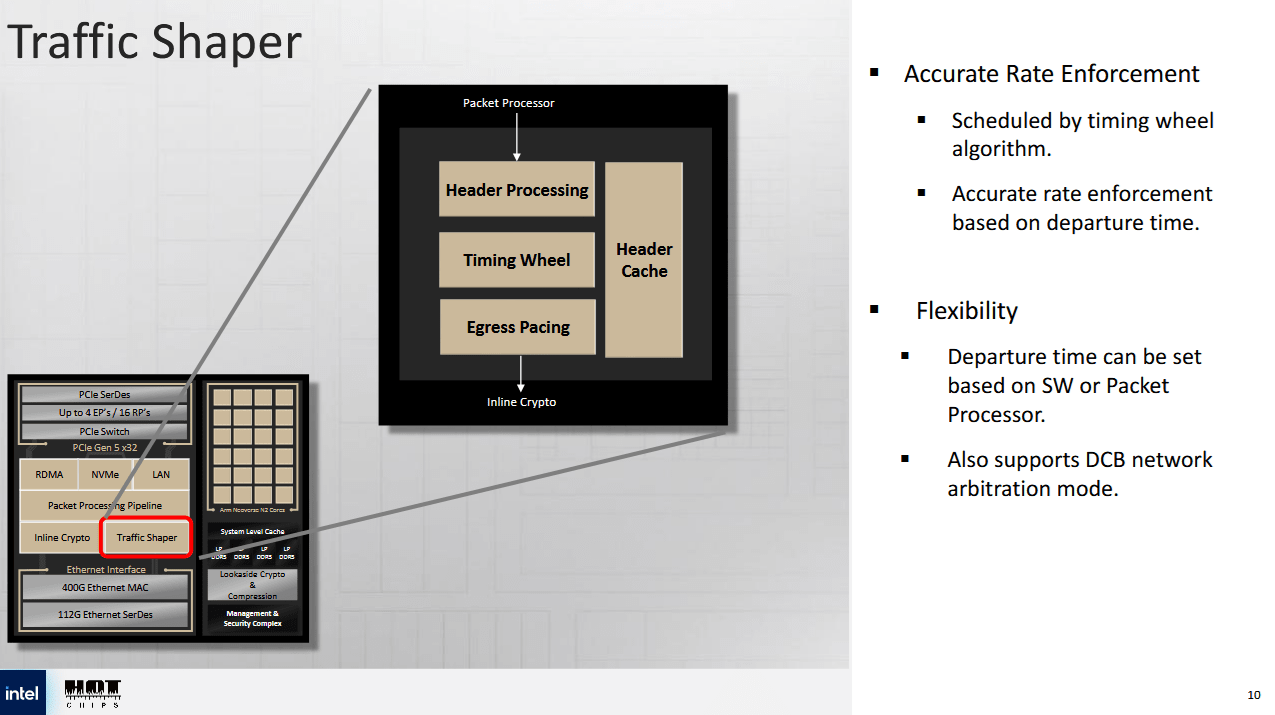
云提供商必须在确保公平性的同时处理客户网络流量。客户只需支付预配的网络带宽费用。此外,客户流量不能独占网络并导致基础设施服务出现问题。IPU 具有流量整形模块,使其能够完全在硬件中执行服务质量测量。一种模式使用多级分层调度程序,根据源端口、目标端口和流量类别对数据包进行仲裁。另一种“定时轮”模式则进行每流数据包调速,这可以通过在 FXP 上设置的分类规则进行控制。英特尔表示,定时轮模式的调速分辨率为每时隙 512 纳秒。

RDMA 流量占数据中心流量的很大一部分。例如,Azure 表示 RDMA 占云内网络流量的 70%,用于磁盘 IO。Mount Morgan 提供 RDMA 传输选项,可为该流量提供硬件卸载。它可以支持跨多台主机的 200 万个队列对,并可在每台主机上公开 1000 个虚拟功能。后者应允许云提供商直接向虚拟机公开 RDMA 加速功能。为了确保可靠的传输,RDMA 传输引擎支持 Falcon 和 Swift 传输协议。这两种协议都对 TCP 进行了改进,英特尔完全在硬件中实现了这些协议的拥塞控制。为了降低延迟,RDMA 模块可以绕过数据包处理管道,自行处理 RDMA 连接。
上述所有加速器模块都是系统级缓存的客户端。某些硬件加速用例(例如包含数百万条数据流的连接跟踪)可能会占用大量内存。系统级缓存应允许 IPU 将加速器内存结构中经常访问的部分保留在片上,从而减少 DRAM 带宽需求。
主机结构和 PCIe 交换机
Mount Morgan 的 PCIe 性能远超普通网卡。它拥有 32 条 PCIe Gen 5 通道,比一些近期推出的台式机 CPU 提供更高的 IO 带宽。相比 Mount Evans 的 16 条 PCIe Gen 4 通道,这也是一次巨大的升级。
传统上,网卡位于主机的下游,因此看起来像是连接到服务器的设备。主机结构和 PCIe 子系统非常灵活,可以让 IPU 承担多种任务。它可以作为最多四台服务器主机的下游设备,每台服务器主机都将 IPU 视为独立的设备。Mount Evans 也支持这种“多主机”模式,但 Mount Morgan 需要更高的 PCIe 带宽才能利用其 400 Gb 网络。
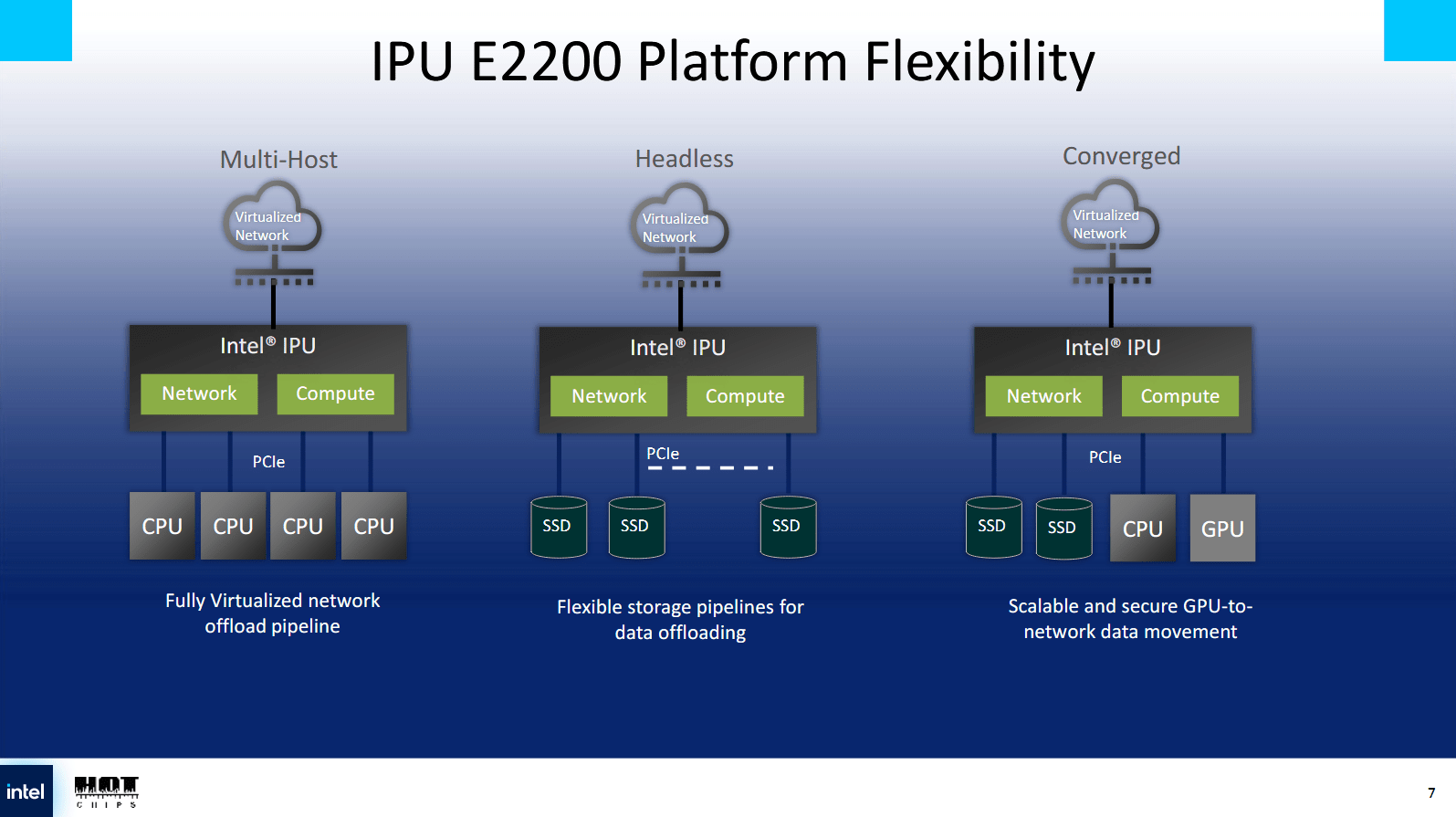
Mount Morgan 可以以“无头”模式运行,在该模式下,它可以作为独立服务器,并作为传统服务器专用于基础设施任务的轻量级替代方案。在此模式下,Mount Morgan 的 32 个 PCIe 通道可以连接到许多 SSD 和其他设备。IPU 的加速器以及 PCIe 通道位于 IPU CPU 核心的下游,而 CPU 核心充当主机 CPU。
“融合”模式可以使用一些 PCIe 通道连接到上游服务器主机,而其他通道连接到下游设备。在此模式下,IPU 对连接的主机显示为 PCIe 交换机,其后可见下游设备。服务器可以通过 IPU 连接到 SSD 和 GPU。IPU 的 CPU 核心可以位于 PCIe 交换机之上并访问下游设备,也可以作为 PCIe 交换机后方的下游设备公开。
IPU 的多种模式展现了 IO 的灵活性。这有点像 AMD 在 AM4 平台上将同一块芯片用作 CPU 中的 IO 芯片和主板芯片组的一部分。当 IO 芯片在 CPU 内部服务时,其 PCIe 通道可以连接到下游设备;当在芯片组中使用时,则可将其分配给上游主机和下游设备。英特尔对 PCIe 的可配置性也并不陌生。他们早期的 QAT PCIe 卡复用了 Lewisburg 芯片组,将其作为下游设备,并在 PCIe 交换机后方显示三个 QAT 设备。
最后的话
云计算在当今科技界扮演着重要角色。它最初源于商用硬件,其服务器配置与客户在本地环境中部署的服务器配置类似。但随着云计算的扩展,云提供商开始发现云专用硬件加速器的用例。例如,亚马逊网络服务 (AWS) 中的“Nitro”卡, 以及微软 Azure 中带有 FPGA 的智能网卡 (NIC) 。英特尔无疑已经看到了这一趋势,而 IPU 正是该公司的应对之策。

Mount Morgan 试图通过整合数量惊人的高度可配置加速器来满足各种云加速需求,以满足云提供商多样化且不断变化的需求。随着协议的变化,硬件加速始终面临着过时的风险。英特尔试图通过提供非常通用的加速器(例如 FXP)以及集成几乎可以运行任何计算任务的 CPU 核心来避免这种情况。后者对于基础设施任务来说似乎有些过度,即使某些加速功能过时,IPU 也能保持其重要性。
从更高层面来看,像 Mount Morgan 这样的 IPU 表明英特尔仍然雄心勃勃,想要拓展其核心 CPU 市场以外的领域。Mount Morgan 的开发必定是一项复杂的工程。它展现了英特尔即使在 CPU 领域遭遇困境时依然坚守的工程能力。英特尔的 IPU 能否在云市场站稳脚跟,尤其是在那些已经根据自身需求开发了内部硬件卸载功能的供应商面前,这将会非常有趣。
如果你喜欢这些内容,可以考虑去Patreon或PayPal给 Chips and Cheese 打个广告。也可以考虑加入Discord 。
原文: https://chipsandcheese.com/p/intels-e2200-mount-morgan-ipu-at