抓取足球数据(或美国的足球数据)是构建综合数据集的好方法,该数据集可用于帮助我们创建统计数据仪表板、运行交叉分析并将洞察力用于体育新闻或梦幻联赛。
\ 无论您的目标是什么,抓取足球数据都可以帮助您收集实现目标所需的所有信息。在本教程中,我们将在 Node.js 中使用 Axios 和 Cheerio 构建一个简单的足球数据抓取工具。
\
开始前需要考虑的几件事
尽管您可以在没有任何先验知识的情况下学习本教程,但您需要一点网络抓取经验才能充分利用它并在其他环境中使用这些信息。
\ 如果您不熟悉网络抓取,我们建议您阅读Node.js 指南中的网络抓取基础知识和我们关于如何构建 eBay抓取工具的教程,以了解有关 async/await 的更多信息。
此外,建议您了解 HTML 和 Javascript 的基础知识。
\
使用 Web Scraping 构建足球数据集
1. 选择数据源
尽管有适用于每个网络抓取项目的基本原则,但每个网站都是一个需要解决的独特难题。选择从哪里获取数据以及如何使用数据也是如此。
以下是您可以用来获取足球数据的一些来源:
\ https://www.premierleague.com/ https://footystats.org/ https://fbref.com/
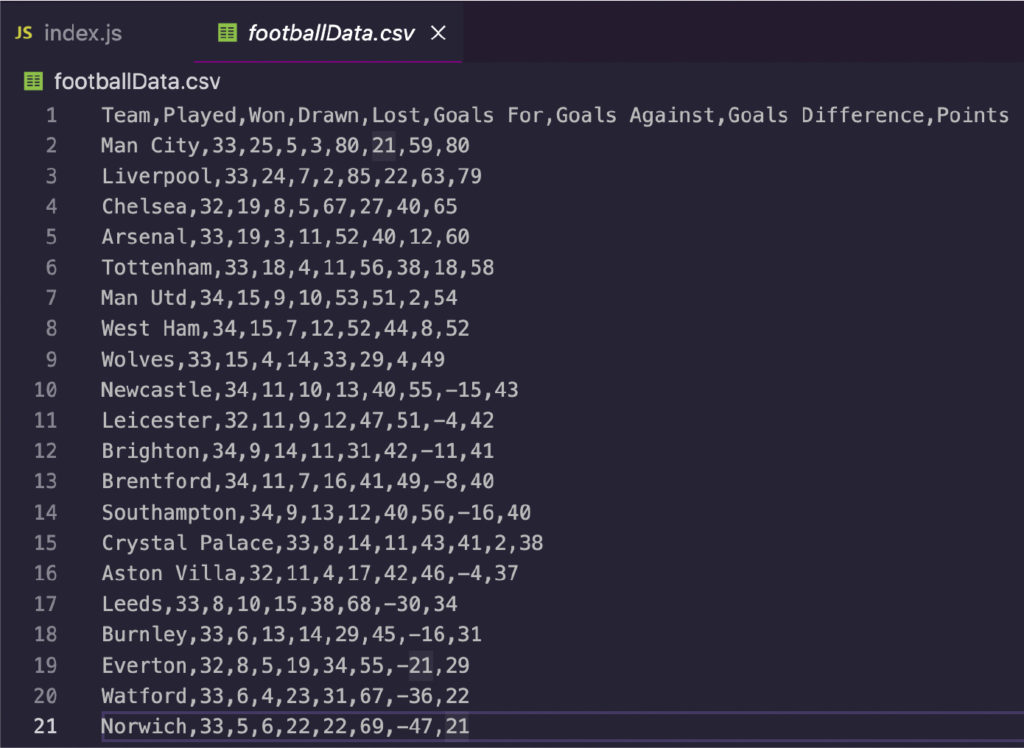
\ 为简单起见,我们将抓取BBC 的英超联赛表格页面,因为它包含我们将直接在 HTML 文档中抓取的所有信息,而且在这些网站上找到的许多数据都是表格形式,因此学习如何有效地抓取它们至关重要。
\注意:其他网站如ESPN使用 JavaScript 将表格的内容注入页面,使我们更难访问数据。也就是说,我们将在稍后的条目中处理这些类型的表。
\
2. 理解 HTML 表格
表格是组织内容和显示数据集更高视图的好方法,让我们人类更容易理解它。
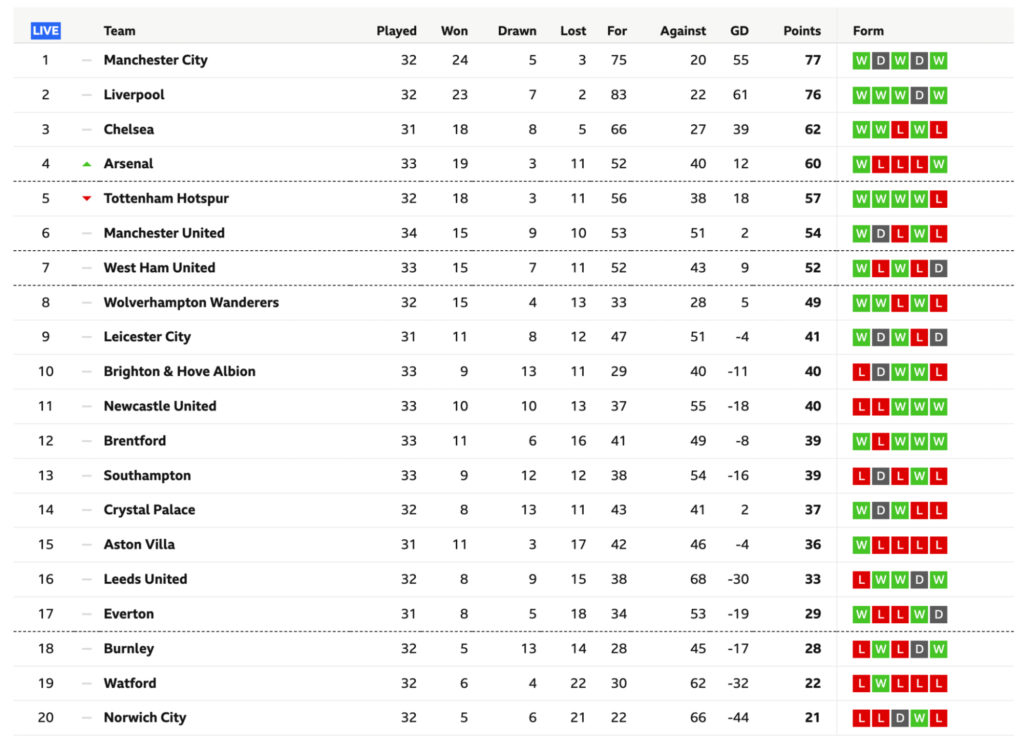
乍一看,每个表都由两个主要元素组成:列和行。但是,表格的 HTML 结构比这要复杂一些。
\ 表格以 a 开头
| 对于 a 中的每个表格单元格 |
| 行内的标记。
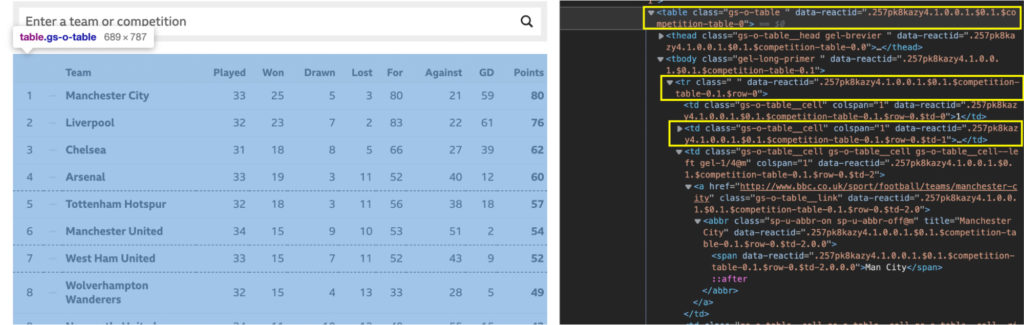
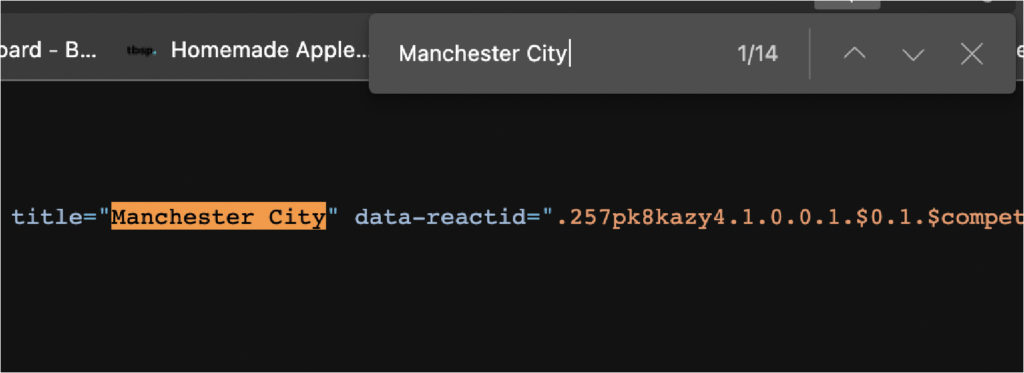
这是 W3school 的一个例子: \ \ 让我们通过检查页面来探索具有这种结构的目标表。 \ 代码有点乱,但这是您在现实世界中可以找到的那种 HTML 文件。尽管乱七八糟,它仍然尊重我们上面讨论的 \ 那么在这个表中抓取足球数据的最佳方法是什么?好吧,如果我们可以创建一个包含所有行的数组,那么我们就可以遍历它们中的每一个并从每个单元格中获取文本。好吧,无论如何,这就是假设。为了确认它,我们需要在浏览器的控制台中测试一些东西。 \ 3. 使用 Chrome 的控制台进行测试我们想要测试几件事。首先要测试的是数据是否驻留在 HTML 文件中,或者是否被注入其中。我们已经告诉您它确实存在于 HTML 文件中,但您需要了解如何自己验证它,以便将来在其他网站上进行足球抓取项目。 \ 查看数据是否从其他地方注入的最简单方法是从表中复制一些文本——在我们的例子中,我们将复制第一个团队——并在页面源中查找它。 \
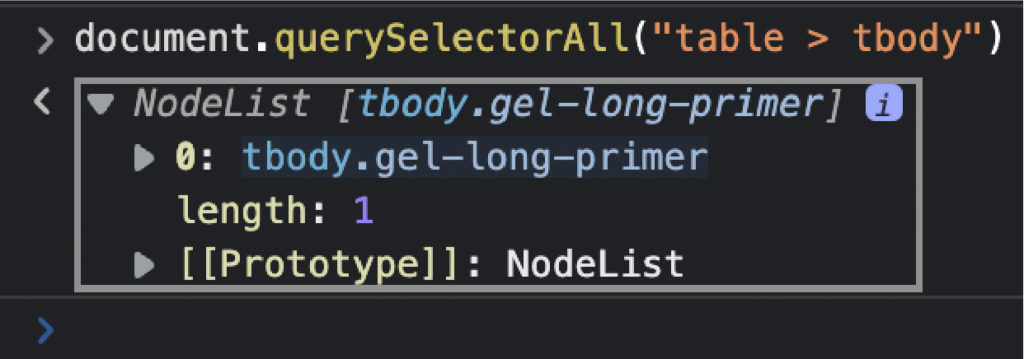
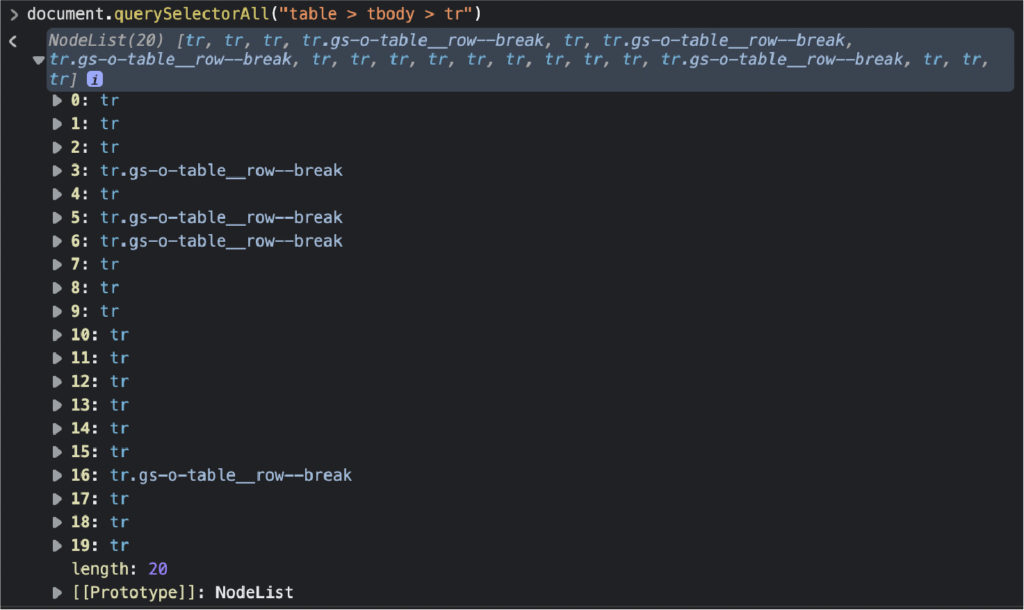
用更多的元素做同样的事情来确保。页面源是任何渲染发生之前的 HTML 文件,因此您可以看到页面的初始状态。如果该元素不存在,则意味着数据是从其他地方注入的,您需要找到另一种解决方案来抓取它。 在编写爬虫代码之前,我们要测试的第二件事是我们的选择器。为此,我们可以使用浏览器的控制台使用 .querySelectorAll() 方法选择元素,使用我们想要抓取的元素和类。 \ 我们要做的第一件事是选择表本身。 \ document.querySelectorAll(“表”) \ 最后,我们将选择表格中的所有 \ 太棒了,20 个节点!它与我们想要抓取的行数相匹配,所以我们现在知道如何使用我们的抓取器来选择它们。 \注意:请记住,当我们有一个节点列表时,计数从 0 而不是 1 开始。 唯一缺少的是学习单元格中每个元素的位置。剧透警报,从 2 到 10。 \
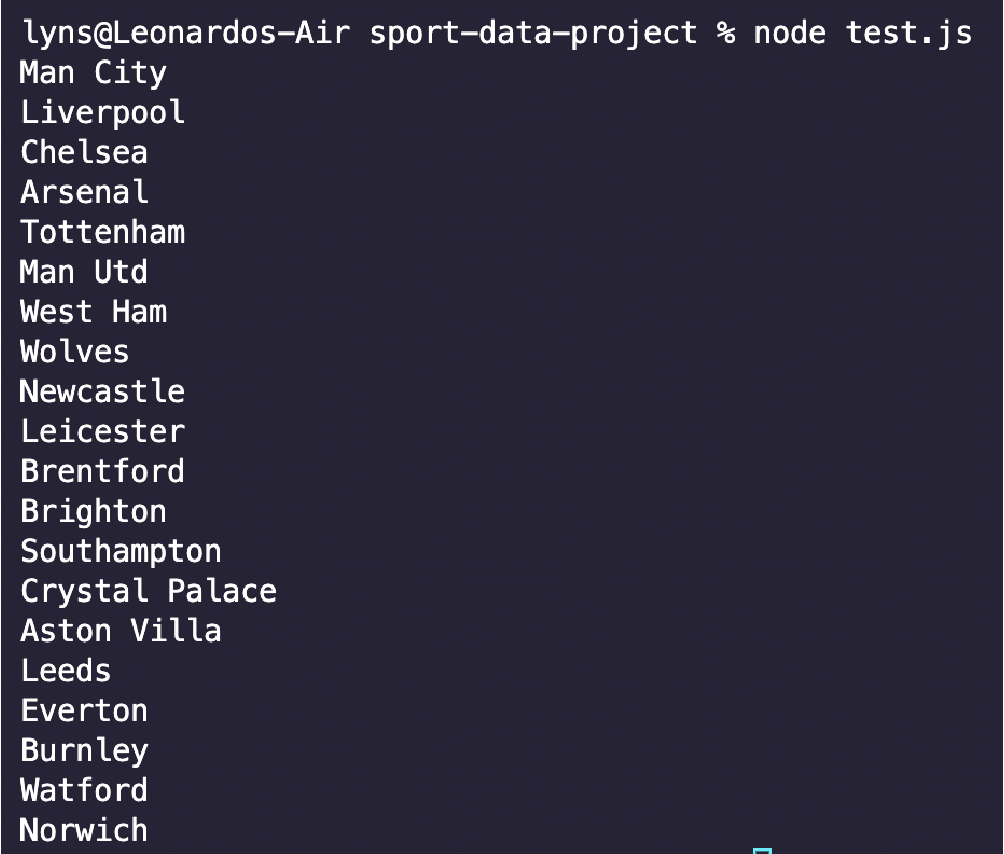
太棒了,现在我们终于准备好使用我们的代码编辑器了。 \ 4. 准备好我们的环境\ 要开始该项目,请创建一个新目录/文件夹并在 VScode 或您喜欢的代码编辑器中打开它。我们将首先安装Node.js 和 NPM ,然后打开您的终端并使用命令 \ 然后,我们将使用 NPM 安装我们的依赖项: \ \ 5. 发送初始请求我们希望将我们的爬虫构建为一个异步函数,这样我们就可以使用 await 关键字来使其更快、更有弹性。让我们打开我们的函数并使用 Axios 发送初始请求,方法是将 URL 传递给它并将结果存储在一个名为 response 的变量中。要测试它是否正常工作,请记录响应的状态。 \ \ \ 6. 将响应传递给 Cheerio 进行解析我们将把响应的数据存储为一个变量(为简单起见,我们将其命名为 HTML)并使用 .load() 方法将其传递给 Cheerio,在美元符号 $ 变量中,就像 JQuery 一样。 \ \ Cheerio 将解析原始 HTML 数据并将其转换为节点树,我们可以使用 CSS 选择器进行导航,例如返回浏览器控制台。 \ 7. 构建解析器在浏览器控制台中测试了选择器后,编写我们的解析器要容易得多。现在我们只需要将它翻译成 Node.js。 JS。首先,我们将获取表中的所有行: \ const allRows = $(“table.gs-o-table > tbody.gel-long-primer > tr”); \ 再一次,试着给你的变量命名一些有意义的东西。它将节省您在更大项目上的时间,并使任何人都可以理解代码的每个部分的作用。 \ 在 Node.JS 中,我们可以使用.each()方法循环遍历所有节点并选择元素。仔细查看代码以弄清楚到底发生了什么: \ \ 请注意,我们首先将所有 \ 让我们测试其中一个元素以确保它正常工作,这样我们就可以看到它返回了什么: \ \ \ 如您所见,它返回一个有序列表而不是一个长字符串——这正是我们下一步所需要的。 \ 8. 将足球数据保存到 CSV 文件中我们将把这个过程分成三个步骤。 \ 1- 在主函数之外创建一个空数组。 \ PremierLeagueTable = []; \ 2- 接下来,使用 .push() 方法将抓取的每个元素推送到数组中,并使用描述性名称来标记它们。您希望它们与您正在抓取的表中的标题相匹配。 \ \ 3-第三,使用 ObjectToCsv 创建一个新的 CSV 文件,并使用 .toDisk() 方法将其保存到您的机器上,包括文件路径和文件名。 \ \ 这就是我们导出数据所需的全部内容。我们也可以自己创建工作表,但没有必要。 ObjectToCsv 使该过程超级快速和简单。 \ 9. 测试运行和完整代码我们添加了一些用于测试目的的 \ \ 使用 node index.js 运行它,不到一秒钟,您将拥有一个可供使用的 CSV 文件。 \ 您可以使用相同的过程来抓取您想要的几乎任何 HTML 表格,并为分析、结果预测等创建庞大的足球数据集。 \
让我们通过 ScraperAPI 发送请求来为我们的爬虫添加一层保护。这将帮助我们抓取多个页面,而不会冒着我们的 IP 地址被阻止或被永久禁止访问这些页面的风险。 \ 首先,让我们创建一个免费的 ScraperAPI 帐户,以获得 5000 次免费 API 调用和我们的密钥。在那里,我们还将看到我们需要在初始请求中使用的 cURL 示例。 \ 如您所见,我们需要做的就是将示例中的 URL 替换为我们的目标 URL,其余的由 ScraperAPI 完成。 \ const response = await axios(‘https://ift.tt/AqYseCj? api_key=51e43be283e4db2a5afb62660xxxxxxx&url=https://ift.tt/l45rXy1); \ 我们的请求可能需要更长的时间,但作为回报,它会为每个请求自动轮换我们的 IP 地址,使用多年的统计分析和机器学习来确定最佳标头组合,并处理可能出现的任何验证码。 最初在这里发布。 |
|---|




原文: https://hackernoon.com/a-step-by-step-guide-to-building-a-football-data-scraper?source=rss