写一份关于 AI 现状的报告一定感觉很像在流沙上建造:当你点击发布时,整个行业已经在你脚下发生了变化。但是,斯坦福大学长达 386 页的总结这个复杂且快速发展的领域的报告中仍然包含重要的趋势和要点。
来自以人为中心的人工智能研究所的 AI Index 与学术界和私营企业的专家合作,收集有关此事的信息和预测。作为一年一度的努力(从规模上看,你可以打赌他们已经在努力布局下一个),这可能不是 AI 的最新成果,但这些定期的广泛调查对于保持警惕很重要在行业的脉搏上。
今年的报告包括“对基础模型的新分析,包括它们的地缘政治和培训成本、人工智能系统的环境影响、K-12 人工智能教育和人工智能的舆论趋势”,以及对 100 个新国家的政策的审视。
对于最高级别的外卖,让我们在这里列出它们:
- 人工智能的发展在过去十年中已经从学术界主导转变为工业界主导,而且这一点没有任何改变的迹象。
- 在传统基准上测试模型变得越来越困难,这里可能需要一种新的范例。
- 人工智能训练和使用的能源足迹越来越可观,但我们还没有看到它如何在其他地方提高效率。
- 自 2012 年以来,“AI 事件和争议”的数量增长了 26 倍,这实际上似乎有点低。
- 与 AI 相关的技能和职位发布正在增加,但没有你想象的那么快。
- 然而,政策制定者正竭尽全力试图编写一份明确的 AI 法案,即使有的话,这也是徒劳的。
- 投资暂时停滞,但这是在过去十年的天文数字增长之后。
- 超过 70% 的中国、沙特和印度受访者认为人工智能利大于弊。美国人? 35%。
但是该报告对许多主题和子主题进行了详细介绍,并且具有可读性和非技术性。只有敬业的人才会阅读所有 300 多页的分析,但实际上,几乎任何有动力的人都可以。
让我们更详细地看一下第 3 章,人工智能技术伦理。
偏差和毒性很难降低为指标,但就我们可以为这些事物定义和测试模型而言,很明显,“未经过滤”的模型更容易进入有问题的领域。 Instruction tuning,即增加一层额外的准备(如隐藏提示)或将模型的输出传递给第二个中介模型,可以有效改善这个问题,但远非完美。
子弹中提到的“人工智能事件和争议”的增加最好用这张图来说明:
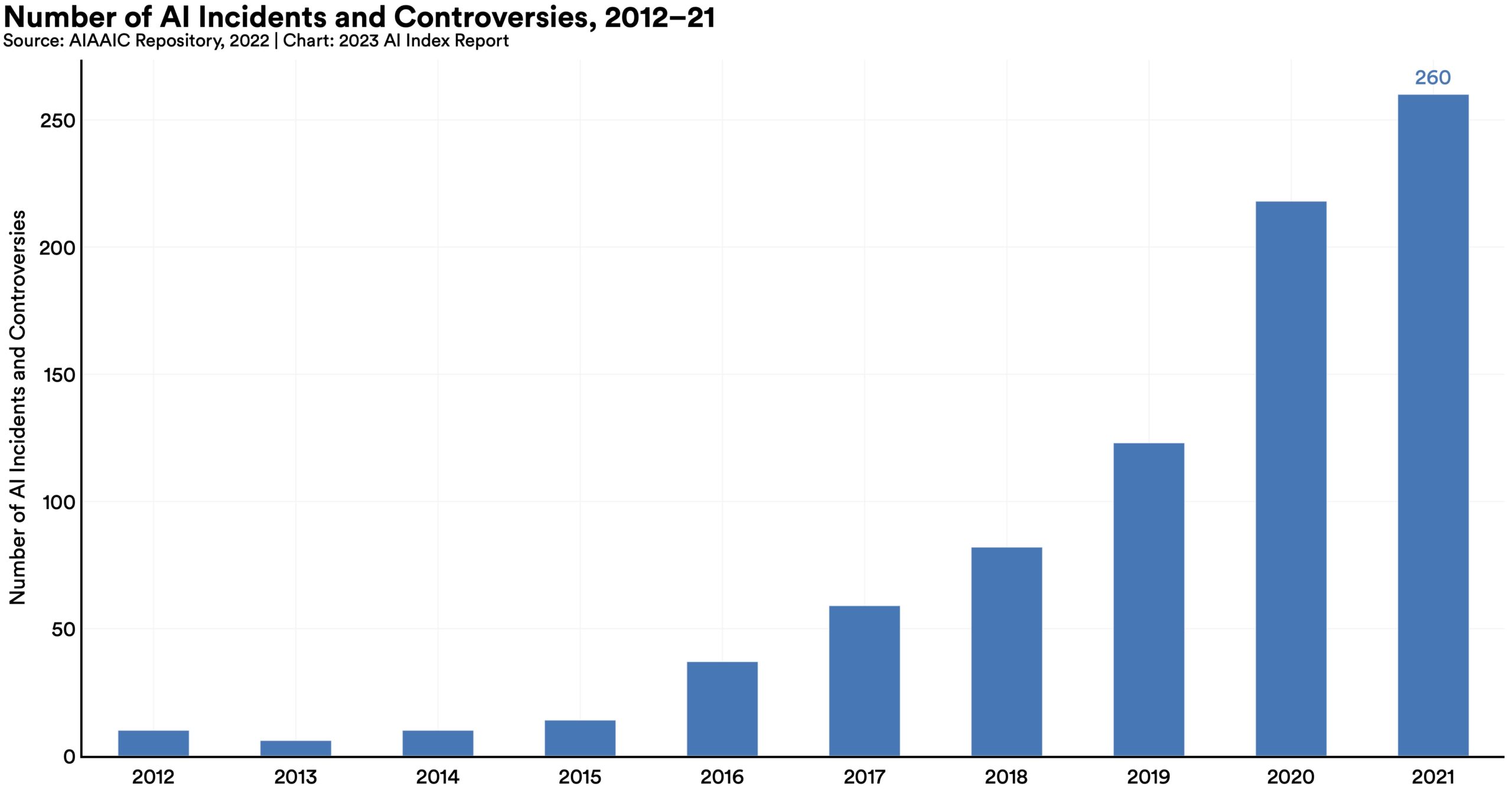
图片来源: Stanford HAI
如您所见,趋势是上升的,这些数字出现在 ChatGPT 和其他大型语言模型被主流采用之前,更不用说图像生成器的巨大改进了。您可以确信,26 倍的增长仅仅是个开始。
以一种方式使模型更公平或更公正可能会对其他指标产生意想不到的后果,如下图所示:
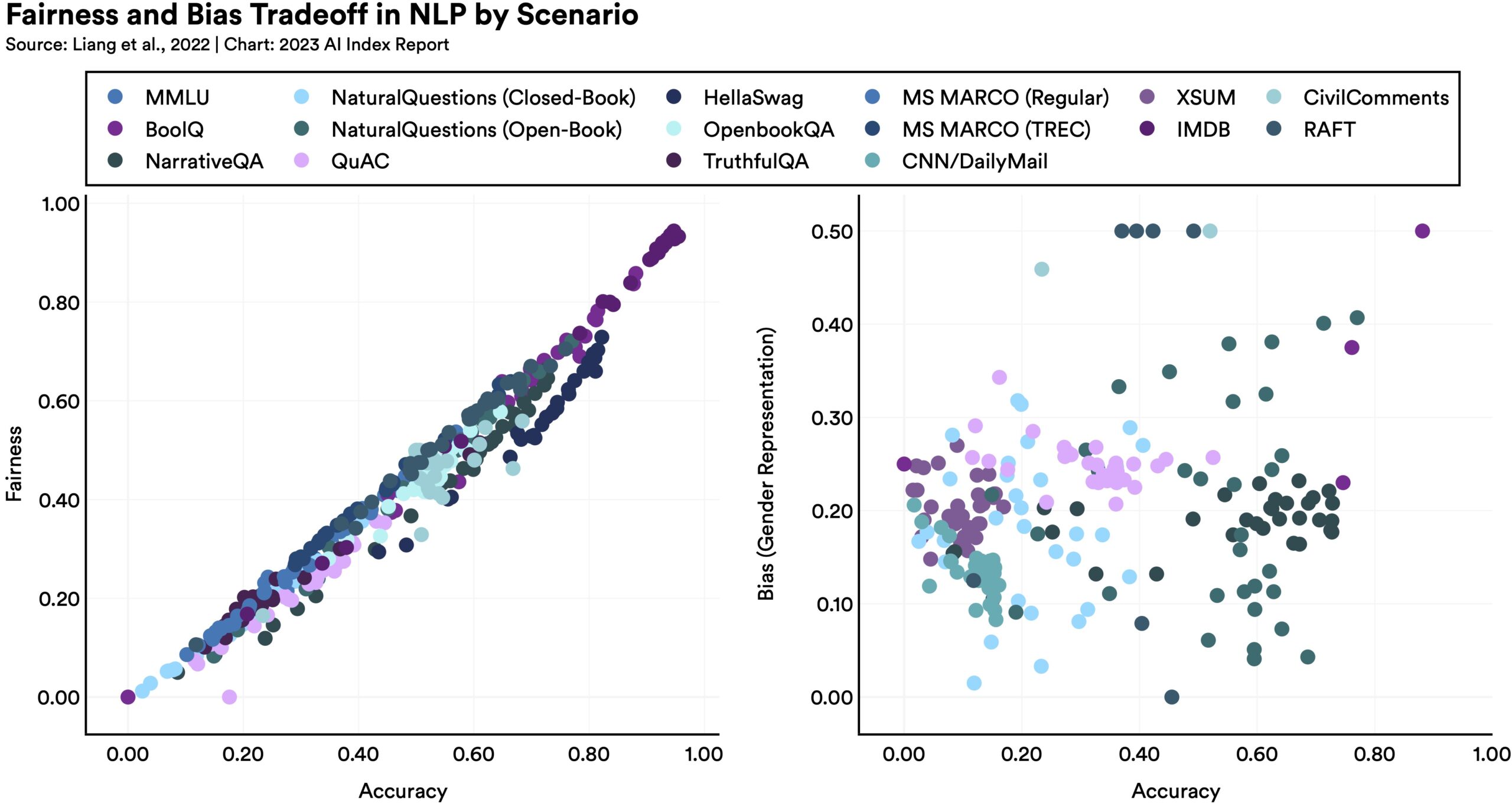
图片来源: Stanford HAI
正如报告所指出的,“在某些公平基准上表现更好的语言模型往往具有更严重的性别偏见。”为什么?很难说,但这只是表明优化并不像任何人希望的那么简单。改进这些大型模型没有简单的解决方案,部分原因是我们并不真正了解它们的工作原理。
事实核查是那些听起来很适合 AI 的领域之一:在对大部分网络进行索引后,它可以评估陈述并返回对它们得到真实来源支持的信心,等等。事实远非如此。人工智能实际上在评估事实性方面特别糟糕,风险不在于它们将成为不可靠的检查者,而在于它们本身将成为令人信服的错误信息的强大来源。已经创建了许多研究和数据集来测试和改进 AI 事实检查,但到目前为止,我们或多或少仍处于起点。
幸运的是,人们对它的兴趣大大增加,原因很明显,如果人们觉得他们不能信任人工智能,整个行业就会倒退。在 ACM 会议上关于公平性、问责制和透明度的提交数量大幅增加,而在 NeurIPS 上,公平性、隐私和可解释性等问题得到了更多关注和展示时间。
这些亮点中的亮点在桌面上留下了很多细节。然而,HAI 团队在组织内容方面做得很好,在阅读了此处的高级内容后,您可以下载完整的论文并深入研究任何引起您兴趣的主题。
Devin Coldewey最初发表于TechCrunch 的斯坦福大学 386 页人工智能现状报告的要点
原文: https://techcrunch.com/2023/04/04/the-takeaways-from-stanfords-386-page-report-on-the-state-of-ai/