本周两件大事撼动了人工智能领域的格局:英伟达的财报和这条关于 Gemini 的推文。
2025年,人工智能行业一直坚信预训练扩展规律已经达到极限。仅仅在训练过程中增加计算量并不能提升模型的性能。
随后,Gemini 3 发布。该模型与 Gemini 2.5 拥有相同的参数数量(一万亿个参数),但性能却实现了大幅提升。它是首个在 LMArena 上 Elo 得分突破 1500 分的模型,并在 20 项基准测试中的 19 项上超越了 GPT-5.1。
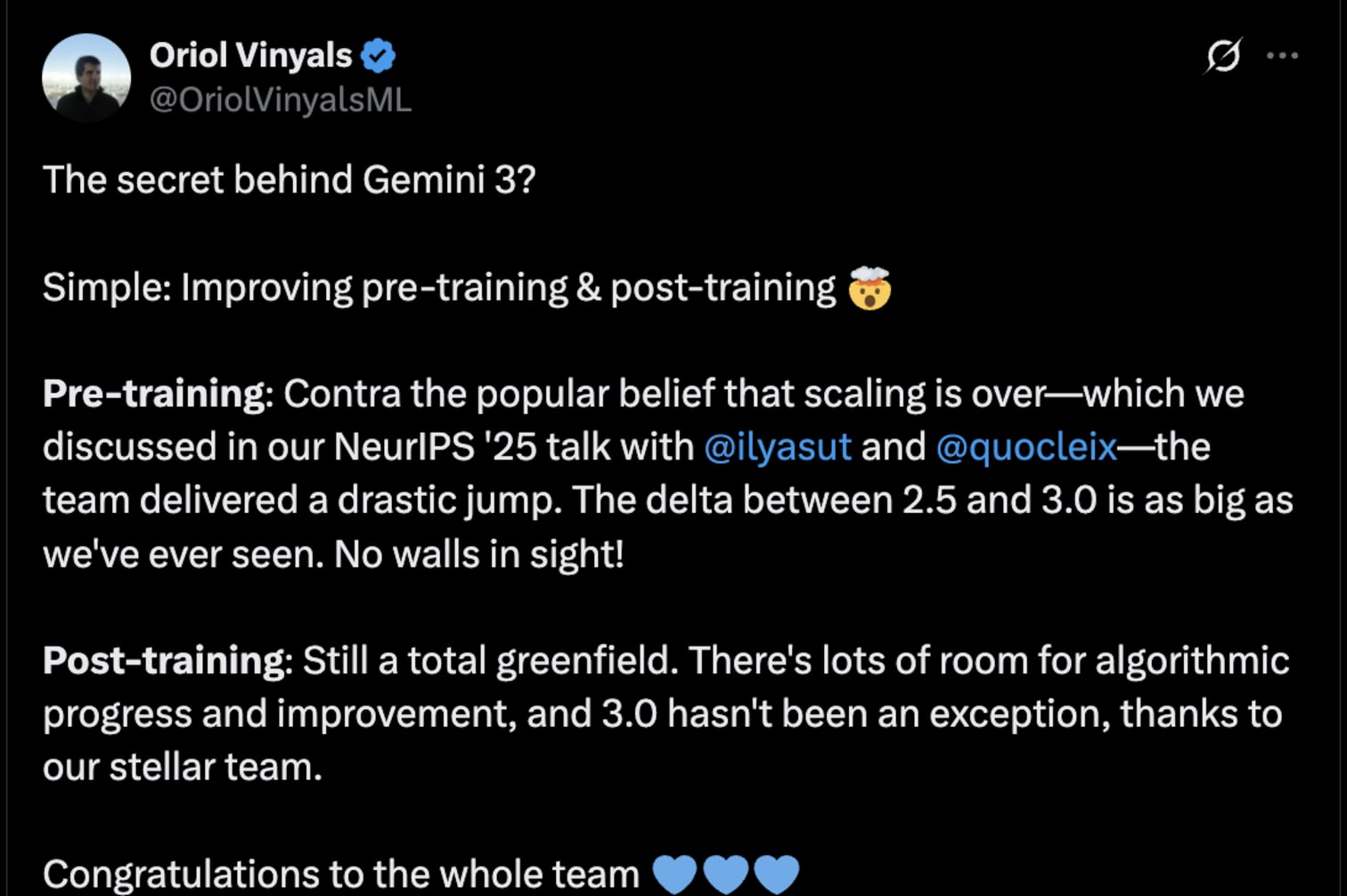
谷歌DeepMind研究副总裁奥里奥尔·维尼亚尔斯(Oriol Vinyals)将性能提升归功于训练前后的改进。他表示,2.5版本到3.0版本之间的性能提升幅度是谷歌迄今为止见过的最大提升,而且目前看来提升空间非常广阔。
这是自 o1 以来最有力的证据,证明当算法改进与更好的计算能力相遇时,预训练扩展仍然有效。
其次,英伟达的财报电话会议进一步强化了这一需求。
我们目前预计,从今年年初到 2026 年底,Blackwell 和 Rubin 的收入将达到 0.5 万亿美元。通过执行我们的年度产品节奏,并通过全栈设计巩固我们的性能领先地位,我们相信,到本十年末,NVIDIA 将成为每年 3 万亿至 4 万亿美元人工智能基础设施建设的最佳选择(我们对此的预测)。
云服务已全部售罄,我们已安装的GPU(包括Blackwell、Hopper和Ampere等新旧版本)也已全部利用。第三季度数据中心收入创下510亿美元的纪录,同比增长66%,这对于我们这样的规模而言是一项了不起的成就。
基础设施建设正在飞速发展,明年规模将达到数千亿美元,英伟达预测规模将达到数万亿美元,并指出“到 2030 年,数据中心规模将达到 3 万亿至 4 万亿美元”。
正如Gavin Baker 指出的那样,Nvidia 证实 Blackwell Ultra 的训练速度比 Hopper 快 5 倍。
Gemini 3 证明了缩放规律依然成立,因此 Blackwell 的额外能力将直接转化为更好的模型能力,而不仅仅是成本效益。
这两个数据点共同推翻了规模壁垒论。
原文: https://www.tomtunguz.com/gemini-3-proves-pretraining-scaling-laws-intact/