Google Research 刚刚发布了MusicLM:从文本生成音乐。这是一种新的生成式 AI 模型,它采用描述性提示并生成“高保真”音乐曲目。这是论文(以及使用 arXiv Vanity的更具可读性的版本)。
目前还没有交互式演示,但网站上有许多示例。提示是这样的:
雷鬼和电子舞曲的融合,带有空旷的、超凡脱俗的声音。引发迷失在太空中的体验,音乐的设计旨在唤起一种惊奇和敬畏的感觉,同时又适合跳舞。
包括歌剧、爵士乐、秘鲁朋克、柏林 90 年代的房子等等。这是一个非常有趣的探索页面。
MusicCaps 数据集
论文摘要包括这一行:
为了支持未来的研究,我们公开发布了 MusicCaps,这是一个由 5.5k 音乐文本对组成的数据集,其中包含由人类专家提供的丰富文本描述。
这是他们在 Kaggle 上发布数据的地方。
我喜欢深入研究这些训练数据集——这个数据集非常小。我决定看一看,看看我能学到什么。
我构建了 musiccaps.datasette.io来支持探索和搜索数据。
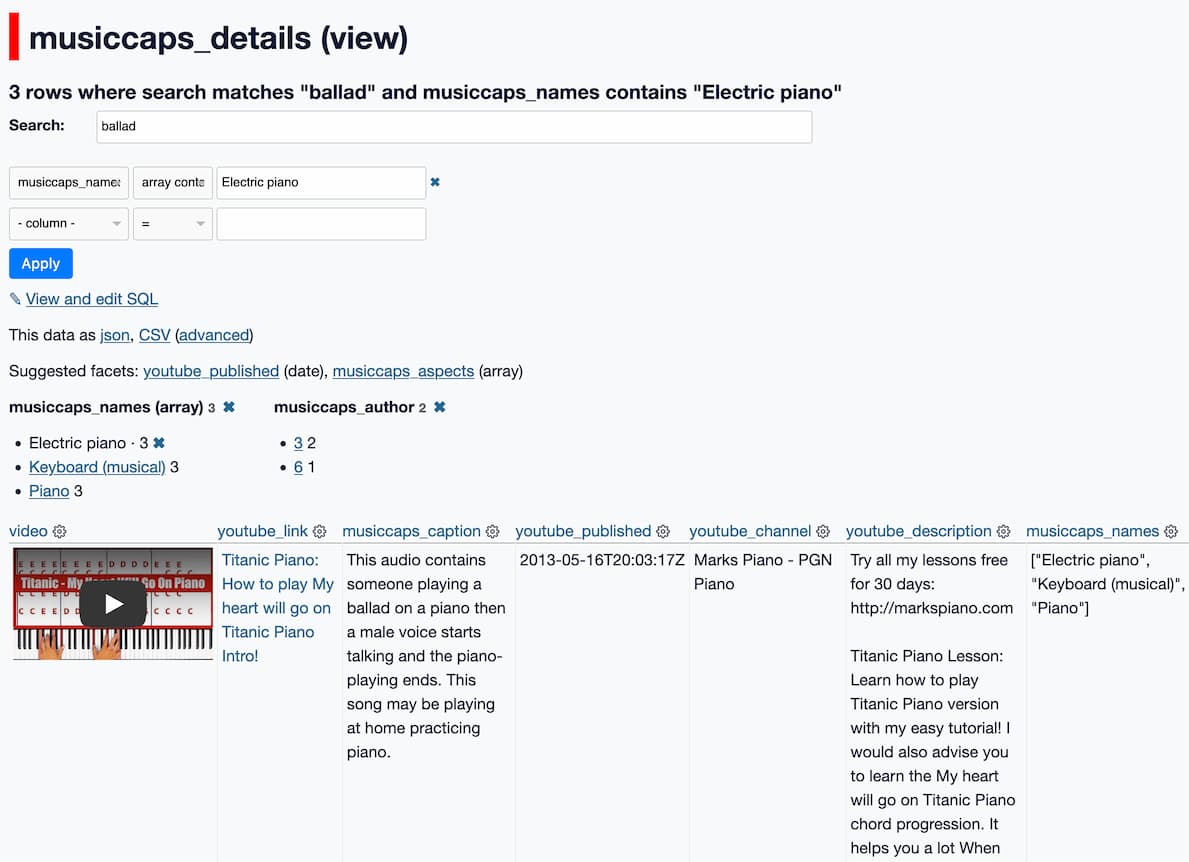
数据集本身根本没有任何音频剪辑——相反,每一行数据都包含一个 YouTube 视频 ID 以及其中剪辑的开始和结束时间。
这类似于用于稳定扩散的 LAION 数据集的工作方式——该数据集包含图像的 URL,但不包含图像本身。
YouTube 视频 ID 只是一个字符串,如zYM0gtd_PRo – 数据集没有更多信息。
但是…有关这些视频的信息可通过 YouTube API 获得。所以我取回了所有 5,500 个视频的全部详细信息,并将它们也包含在数据库中。
这意味着我们可以开始回答各种有趣的问题:
- 哪些 YouTube 频道在数据集中最多? – 答案是ProGuitarShopDemos有 12 个, Berliner Philharmoniker有 8 个, Prymaxe有 8 个 – 虽然一般来说分布很广,有 5,163 个通道。
- YouTube 上不再有多少视频? – 根据 YouTube API,数据集中引用的 18 个视频不再存在。
- 有多少视频包含神奇的 YouTube 描述短语“无意侵犯版权”? – 其中有 31 个。有关此迷信的背景,请参阅 Andy Baio 的No Copyright Intended 。
搜索功能配置为针对作为 MusicCaps 数据集的关键功能提供的人工描述运行 – 尝试一些搜索,如歌剧、 民谣、 吉他或异想天开。
我是如何建造这个的
该数据集可在 Kaggle上获得,但由于它已获得 CC BY-SA 4.0 许可,我获取了它的副本并将 CSV 文件放入此 GitHub 存储库中。
您可以通过以下网址使用Datasette Lite探索它:
这是一个不错的起点,但能够单击“播放”并收听该音频真的很重要。
我为此构建了一个新的 Datasette 插件: datasette-youtube-embed 。
该插件通过查找以下格式的 YouTube 网址来工作:
-
https://www.youtube.com/watch?v=-U16iKiXGuY -
https://www.youtube.com/watch?v=-U16iKiXGuY&start=30 -
https://www.youtube.com/watch?v=-U16iKiXGuY&start=30&end=40
如果它找到其中之一,它会将其替换为通过start和end参数(如果存在)的 YouTube 嵌入。
这意味着它可以播放 MusicCaps 数据集引用的确切剪辑。
我第一次尝试使用这个插件使用常规的 YouTube 嵌入,但 Datasette 默认返回一个页面上最多 100 行,而 100 个 YouTube iframe 嵌入是相当重的!
相反,我将插件切换为使用 Paul Irish 的Lite YouTube 嵌入Web 组件。
遗憾的是,这意味着该插件不适用于 Datasette Lite,因此我改为将完整的 Datasette 实例部署到 Vercel。
从 YouTube API 添加视频详细信息
我想为每个视频添加更多背景信息。 YouTube 数据 API 有一个视频端点,它接受以逗号分隔的视频 ID 列表(一次最多 50 个,文档中未提及)并返回有关每个视频的详细信息。
经过一些实验,结果证明这是给了我想要的关键数据的方法:
https://www.googleapis.com/youtube/v3/videos ?part=snippet,statistics &id=video_id1,video_id2,video_id3 &key=youtube-api-key
我构建 了一个 Jupyter 笔记本,将所有 ID 分成 50 个一组,获取数据并使用sqlite-utils将其写入我的 SQLite 数据库。
初始 CSV 中的audioset_positive_labels列具有类似/m/0140xf,/m/02cjck,/m/04rlf ——这些结果是tensorflow/models GitHub 存储库中 AudioSet 类别的CSV 文件中的匹配 ID,所以我获取了并改变了那些。
我必须做一些额外的清理工作才能让一切按我想要的方式工作。最终结果是两个表,具有以下架构:
创建表 [musiccaps] ( [ytid]文本主键, [url]文本, [标题]文本, [aspect_list]文本, [audioset_names] TEXT , [author_id]文本, [start_s]文本, [end_s]文本, [is_balanced_subset]整数, [is_audioset_eval] INTEGER , [audioset_ids]文本 ); 创建表 [视频] ( [id]文本主键, [发布时间] TEXT , [channelId] TEXT , [标题]文本, [描述]文本, [缩略图] TEXT , [频道标题] TEXT , [标签]文本, [类别 ID]文本, [liveBroadcastContent] TEXT , [本地化] TEXT , [viewCount]整数, [likeCount]整数, [favoriteCount]整数, [commentCount]整数, [默认音频语言] TEXT , [默认语言]文本 );
我针对musiccaps.caption列配置了 SQLite 全文搜索。
最后一步是创建一个 SQL 视图,该视图组合了两个表中的关键数据。经过更多的迭代后,我想出了这个:
创建视图musiccaps_details作为选择 音乐帽。网址为视频, json_object( '标签' , 合并(视频。标题, '从 YouTube 中丢失' ), ' href ' , 音乐帽。网址 )作为youtube_link, 音乐帽。标题为musiccaps_caption, 视频。发布于youtube_published, 视频。频道标题为youtube_channel, 视频。描述为youtube_description, 音乐帽。 audioset_names作为musiccaps_names, 音乐帽。 aspect_list作为musiccaps_aspects, 音乐帽。 author_id作为musiccaps_author, 视频。 id为youtube_id, 音乐帽。 rowid作为musiccaps_rowid 从 音乐帽 离开加入musiccaps上的视频。 ytid =视频。编号;
我为实例主页构建了一个自定义模板以添加搜索框,然后使用datasette-publish-vercel插件将整个内容发送到 Vercel。
让我知道你发现了什么
挖掘这些数据非常有趣。我很想听听你的发现。如果您发现任何有趣的事情,请在 Mastodon 上联系我!
原文: http://simonwillison.net/2023/Jan/27/exploring-musiccaps/#atom-everything