
在将数据序列化为 JSON、CSV 或进行日志记录时,我们需要将数字转换为字符串。浮点数以二进制形式存储,但我们需要将其转换为十进制字符串。第一个正式发表的算法是 Steele 和 White 于 1990 年提出的 Dragon 方案(具体来说是 Dragin2)。此后,出现了速度更快的算法:Grisu3、Ryū、Schubfach、Grisu-Exact 和 Dragonbox。在 C++17 中,我们提供了一个名为std::to_chars的标准函数来实现此目的。一个常见的目标是在保证能够唯一标识原始数字的前提下,生成最短的字符串。
我们最近发表了《将二进制浮点数转换为最短十进制字符串》一文。文中详细探讨了从浮点数到字符串的完整转换过程。实际上,转换过程包含两个步骤:首先,计算浮点数的有效数字和 10 的幂(步骤 1);然后,生成字符串(步骤 2)。例如,对于数字 π,您可能需要先计算31415927和-7 (步骤 1),然后再生成字符串3.1415927 。字符串生成需要将小数点放置在正确的位置,并在需要时切换到指数表示法。字符串生成成本相对较低,在旧方案中可能可以忽略不计,但随着软件速度的提升,它现在已成为一个更重要的组成部分(占用 20% 到 35% 的时间)。
根据转换的数据量不同,结果差异很大。但我们发现,Jeon 的 Dragonbox 和 Giulietti 的 Schubfach 这两种实现方式表现最佳。Adams 的 Ryū 实现方式紧随其后,速度也相当。所有这些技术都比 1990 年的初代 Dragon 4 快了大约 10 倍。三十年来性能提升十倍,相当于每年提升约 8%,这完全归功于更优秀的实现方式和算法。
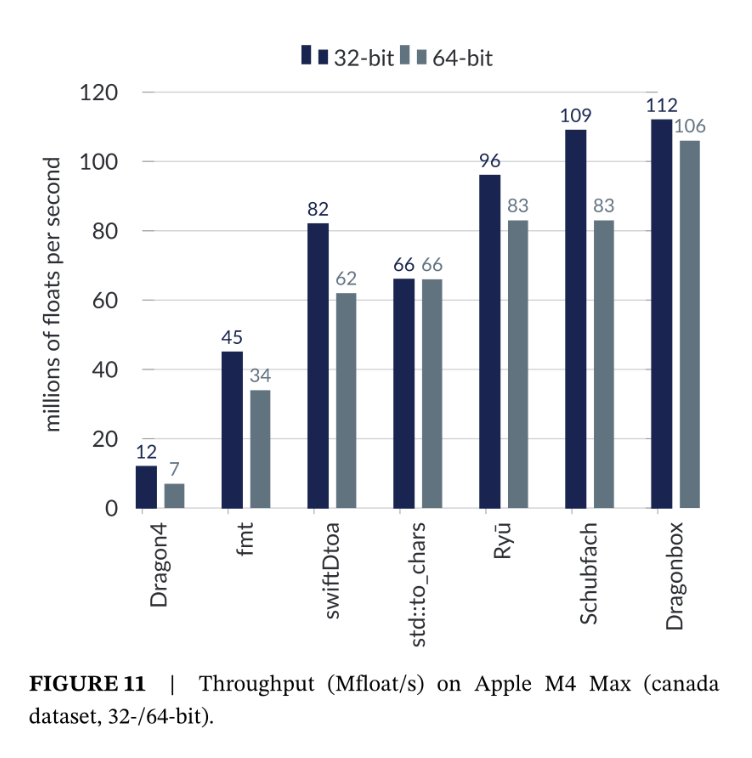
高效算法生成每个字符串大约需要 200 到 350 条指令。我们发现,Linux 系统下的标准函数std::to_chars使用的指令略多于实际所需(最多接近实际所需的两倍)。因此,常见的实现方式还有改进的空间。使用流行的 C++ 库 ` fmt效率略低。
一个有趣的发现是,我们发现所有可用的函数都无法生成最短的字符串。例如,C++ 的std::to_chars函数会将数字 0.00011 渲染成 0.00011(7 个字符),而更短的科学计数法表示为 1.1e-4 则可以。但是,按照惯例,切换到科学计数法时,需要将指数填充到两位(即 1.1e-04)。除了这个技术细节之外,我们发现没有任何实现能够始终生成最短的字符串。
我们所有的代码、数据集和原始结果都是开源的。基准测试套件位于 https://github.com/fastfloat/float_serialization_benchmark,测试数据位于 https://github.com/fastfloat/float-data。
参考:将二进制浮点数转换为最短整数
十进制字符串:实验性综述,《软件:实践与经验》(即将发表)
原文: https://lemire.me/blog/2026/02/01/converting-floats-to-strings-quickly/