蛋白质折叠模型是人工智能在科学领域取得的成功案例。
在2010年代后期,谷歌DeepMind的研究人员利用机器学习技术预测蛋白质的三维形状。2020年发布的AlphaFold 2模型非常出色,以至于其开发者与一位外部学者共同分享了2024年诺贝尔化学奖。
然而,许多学者对DeepMind取得的进展褒贬不一。2018年,时任哈佛大学研究员的穆罕默德·阿尔库雷希(Mohammed AlQuraishi)撰写了一篇广为流传的博客文章,报道了蛋白质折叠研究人员普遍存在的“生存焦虑”。
AlphaFold 的第一个版本刚刚赢得了 CASP13,这是一项著名的蛋白质折叠竞赛。AlQuraishi 写道,他和他的学术同行们担心“蛋白质结构预测作为一个学术领域是否有未来,或者像机器学习的许多分支一样,未来最好的研究是否会在工业实验室完成,而学术团队只能获得一些零星的成果。”
工业实验室不太可能完全分享其研究成果,或者研究那些没有直接商业应用前景的问题。如果没有学术研究,下一代的研究成果最终可能会被少数几家公司垄断,从而减缓整个领域的发展。
这些担忧在2024年发布的AlphaFold 3中得到了证实,该模型最初对模型权重保密。如今,科学家可以下载这些权重用于某些非商业用途,“但最终决定权在谷歌DeepMind手中”。DeepMind人工智能科学主管普什米特·科利(Pushmeet Kohli)告诉《自然》杂志,DeepMind必须在确保模型“易于获取”且对科学家有实际影响,以及Alphabet希望通过其子公司Isomorphic Labs“推进商业药物研发”之间取得平衡。
阿尔库雷希后来成为哥伦比亚大学的教授,并一直致力于保障学术研究人员的权益。2021年,他联合创立了OpenFold项目,旨在以开放的方式复制AlphaFold的创新成果。这不仅需要艰巨的技术工作,还需要在组织和筹款方面进行创新。
为了获得所需的价值数百万美元的计算能力,阿尔库雷希和他的同事们求助于一个意想不到的盟友:制药行业。众所周知,制药公司并不热衷于开放科学,但他们确实不想依赖谷歌。
支持 OpenFold 项目可以让这些制药公司参与到项目的研究重点中来。制药公司还可以提前获得 OpenFold 的模型供内部使用。但至关重要的是,OpenFold 会向公众发布其模型,以及完整的训练数据、源代码和其他一些在近期 AlphaFold 版本中未包含的材料。
“我希望看到这项工作产生影响,”阿尔库雷希在周一的采访中告诉我。他希望为新的发现和新疗法的研发做出贡献。他说,如今“大部分工作都在工业界进行”。但像OpenFold这样的项目可以帮助学术研究人员发挥更大的作用,从而加快科学发现的步伐。
蛋白质折叠:从序列到结构
蛋白质是生命必需的大分子。它们执行多种生物学功能,从调节血糖(如胰岛素)到作为抗体发挥作用。
蛋白质的形状对其功能至关重要。以肌红蛋白(如图所示)为例,它负责在肌肉组织中储存氧气。肌红蛋白的形状形成了一个小小的口袋,可以容纳一个含铁分子(图中灰色圆圈所示)。这个口袋的形状使得铁可以与氧气可逆地结合,从而使蛋白质能够根据需要在肌肉中捕获和释放氧气。
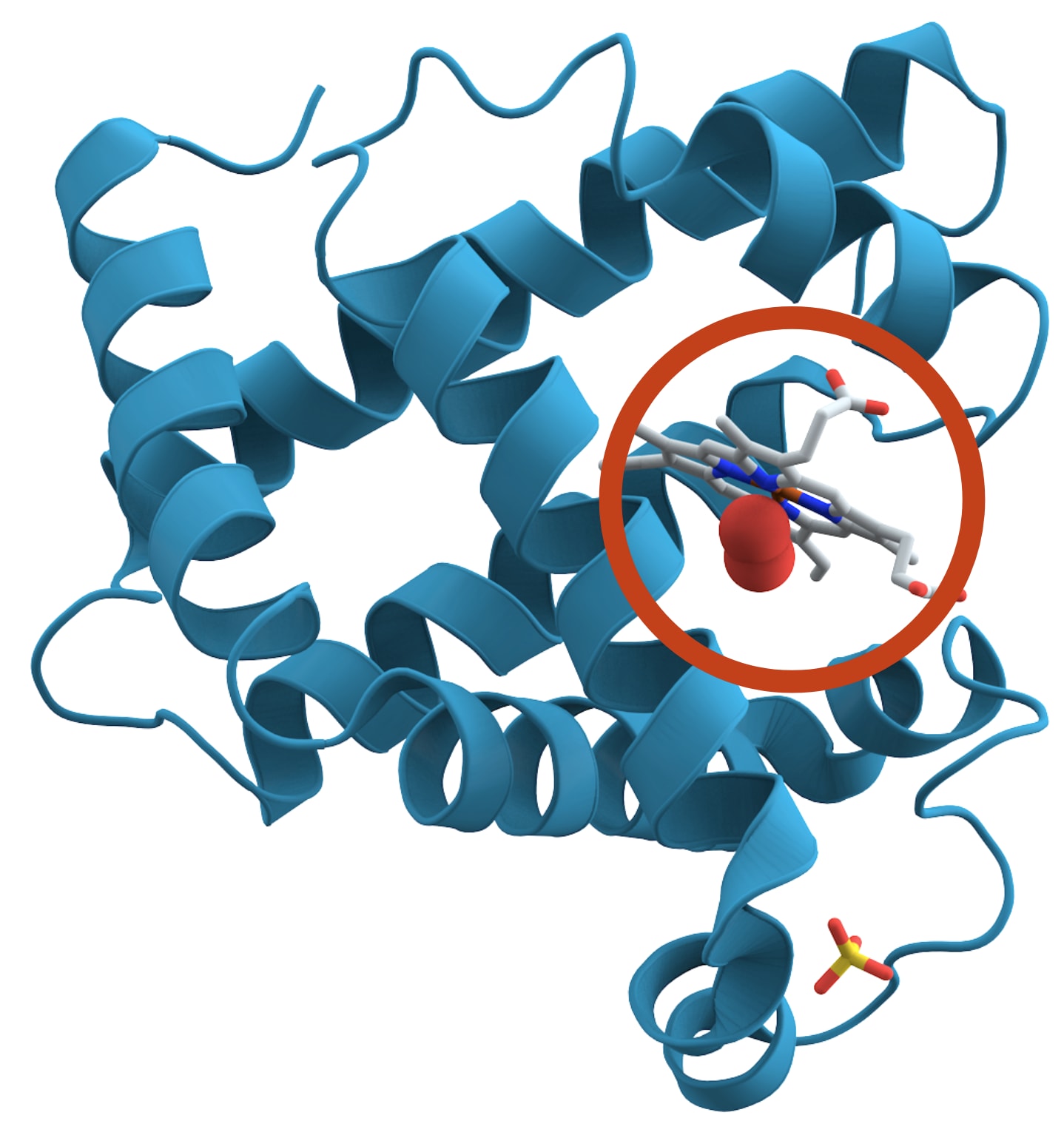
然而,通过实验确定蛋白质的形状成本很高。传统方法是将蛋白质结晶,然后分析X射线在晶体结构上的散射情况。这个过程称为X射线晶体学,对于结构复杂的蛋白质,可能需要数月甚至数年的时间。虽然一些新方法速度更快,但仍然很昂贵。
因此,科学家们经常尝试通过计算来预测蛋白质的结构。每种蛋白质都是由氨基酸链组成的——只有20种氨基酸——这些氨基酸链折叠成三维形状。德克萨斯大学奥斯汀分校生物学教授克劳斯·威尔克表示,与直接确定蛋白质结构相比,确定蛋白质的氨基酸链“非常容易”。
但是,从氨基酸预测三维结构——也就是弄清楚蛋白质如何折叠——并非易事。可能性太多了,如果采用穷举法搜索,所需的时间甚至会超过宇宙的年龄。
科学家们长期以来一直使用各种技巧来简化这个问题。例如,他们可以将序列与蛋白质数据库(PDB)中大约20万个结构进行比较。相似的序列很可能具有相似的形状。但是,找到一种准确便捷的预测方法,在50多年里一直是一个悬而未决的问题。
AlphaFold 2 的出现改变了这一现状,它极大地简化了蛋白质结构的预测。虽然它并没有“解决”蛋白质折叠的根本问题——例如,预测结果并非总是准确——但这无疑是一项重大进步。欧洲生物信息学研究所 (EMBL-EBI) 的一项研究显示, 2022 年发表在《自然》杂志上的一篇文章指出,在 2.14 亿个蛋白质结构预测中,有 80% 的预测结果足够准确,至少可以用于某些应用。
AlphaFold 2 融合了卓越的工程技术和多项巧妙的科学理念。DeepMind 使用的一项重要技术是共进化。其基本思路是将目标蛋白与序列高度相似的蛋白进行比较。关键步骤是计算多序列比对 (MSA)——一种将蛋白质序列排列成网格的模型,其中相同的氨基酸位于同一列。在 AlphaFold 的输入中包含 MSA 有助于它推断蛋白质结构的细节信息。
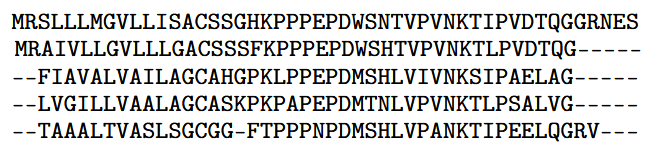
这是一个多序列比对示例。顶行是目标蛋白的氨基酸序列;其下每一行都是一个相关蛋白的序列。短横线表示序列间的空位。(来自OpenProteinSet:Ahdritz 等人开发的用于大规模结构生物学训练的数据,采用 CC BY 4.0 许可协议)
最初的 OpenFold
DeepMind 发布了 AlphaFold 2 的模型权重和架构的高级描述,但并未包含训练代码或全部训练数据。成立于 2021 年的 OpenFold 致力于免费提供此类信息。
阿尔库雷希的背景使他能够胜任该项目的联合创始人。他从小在巴格达长大,是个电脑迷——五岁时就拥有了一台Commodore 64电脑。十二岁时,他随家人搬到了旧金山湾区。高中三年级时,他创办了一家互联网初创公司,之后进入圣克拉拉大学攻读计算机工程专业。
在大学期间,阿尔库雷希的兴趣从科技创业转向了科学。在为Wolfram Mathematica软件添加计算生物学功能一年半后,他前往斯坦福大学攻读生物学博士学位。博士毕业后,他继续研究机器学习在蛋白质折叠问题中的应用。
在 AlphaFold 于 2018 年赢得 CASP13 竞赛后,AlQuraishi写道,DeepMind 的成功“对学术科学提出了严重的质疑”。尽管学术界人士的数量比 DeepMind 的团队多一个数量级,但他们却被一家在该领域崭露头角的科技公司抢先一步。
阿尔库雷希认为,要解决蛋白质折叠这类重大问题,需要对组织结构进行重新思考。传统的学术实验室通常由一位资深科学家指导几名研究生组成。阿尔库雷希担心,像这样的小型机构可能缺乏足够的人力和财力来解决蛋白质折叠这类重大问题。

“我一直都乐于尝试组织学术研究的新方法,”阿尔库雷希周一告诉我。
AlQuraishi认为,学术实验室需要更频繁的沟通和更好的软件工程。他们还需要大量的计算资源:2013年Geoff Hinton加入谷歌时,AlQuraishi 曾预测,“如果无法获得强大的计算能力,学术界的机器学习研究将越来越难以保持其相关性。”
因此,在2021年,AlQuraishi与Nazim Bouatta和Gustaf Ahdritz合作,共同创立了OpenFold项目。该项目不仅有着雄心勃勃的技术目标,而且其组织结构也极具创新性。
OpenFold 的首要目标是逆向工程 AlphaFold 2 中 DeepMind 未公开的部分——包括用于训练模型的代码和数据。尽管 DeepMind 在训练过程中仅使用了公开数据集,但它并未发布用于训练的多序列比对 (MSA) 数据。MSA 的计算成本很高,因此许多其他研究团队选择对 AlphaFold 2 进行微调,而不是从头开始重新训练。OpenFold 发布了一个公开的 MSA数据集(使用了 400 万小时的捐赠计算资源)以及训练代码。
第二个目标是重构 AlphaFold 2 的代码,使其性能更高、模块化程度更高、更易于使用。AlphaFold 2 使用的是 JAX(谷歌的机器学习框架)而非更流行的 PyTorch。OpenFold 则使用 PyTorch 编写代码,这提升了性能,也使其更容易被其他项目采用。例如,Meta 在其ESM-Fold 项目中就使用了 OpenFold 的部分架构。
第三个目标——这与AlQuraishi的计算机科学背景相符——是研究模型本身。在他们的预印本中,OpenFold团队分析了AlphaFold架构的训练动态。例如,他们发现该模型在训练的前3%时间内就达到了最终准确率的90%。
最后,AlQuraishi 和他的合作者希望确保有一个可供制药公司使用的蛋白质折叠模型。他们认为这是必要的,因为 AlphaFold 2 最初是以非商业许可发布的。但随着 AlphaFold 2 许可的开放性提高,这个目标也就不再重要了。
截至2022年6月22日,OpenFold团队在所有这些目标上都取得了实质性进展。当天,他们宣布发布OpenFold及其MSA数据集中的首批40万个蛋白质。虽然仍有许多改进工作要做——预印本还要五个月才能发表;模型代码也需要不断迭代——但OpenFold还有其他科学目标。AlphaFold 2最初只能预测单个氨基酸链的结构;OpenFold能否复制后续预测更复杂结构的努力呢?
因此,就在同一天,OpenFold 还宣布,对蛋白质折叠这类问题同样感兴趣的制药公司将帮助资助 OpenFold 的进一步研究,以换取对其研究方向的意见。
AlphaFold 3 的复制竞赛
同行评审过程极其缓慢,以至于OpenFold的正式论文直到2024年5月才发表在《自然·方法》杂志上——距离最初发布已经过去了一年半的时间。就在论文发表前一周,谷歌DeepMind公司意外地展现了开放研究的价值。
DeepMind 发布了AlphaFold 3 ,该模型能够预测蛋白质与其他类型分子的相互作用将如何影响其三维结构。但有一个前提条件:该模型不会公开发布。DeepMind 与 Isomorphic(谷歌旗下的 AI 药物研发初创公司,由 Hassabis 于 2021 年创立)合作开发了 AlphaFold 3。Isomorphic 将获得该模型的完整访问权限和商业使用权;其他用户只能通过网页界面使用该模型。
科学家们对此感到愤怒。超过1000名科学家签署了一封公开信,抨击《自然》杂志允许DeepMind公司发表关于AlphaFold 3的论文,却没有提供更多关于该模型的细节。信中指出,“AlphaFold 3论文中披露的信息量,对于公司网站上的公告来说尚可接受(事实上,作者也确实在网站上预览了这些进展),但它未能达到科学界对可用性、可扩展性和透明度的标准。”
DeepMind的回应是将每日迭代次数上限提高到20代,并承诺在六个月内发布模型权重“供学术用途”。然而,发布权重时却附加了诸多限制。访问权限严格限制为非商业用途,且“完全由谷歌DeepMind自行决定”。此外,科学家也无法对模型进行微调或提炼。
这立即引发了对 AlphaFold 3 开放复制模型的需求。几个月内,字节跳动和 Chai Discovery 等公司就发布了遵循 AlphaFold 3 论文中训练细节的模型。2024 年 11 月,麻省理工学院的一个实验室以开源许可证发布了 Boltz-1 模型。
2024 年 6 月,AlQuraishi 告诉GEN Biotechnology 杂志,他的研究小组已经在着手复制 AlphaFold 3。但与 AlphaFold 2 相比,复制 AlphaFold 3 面临着新的挑战。
逆向工程 AlphaFold 3 需要比 AlphaFold 2 在更多种类的任务上取得成功。“这些不同的模态之间经常存在冲突,”AlQuraishi 告诉我。即使一个模型在某个领域达到了 AlphaFold 3 的性能水平,它在另一个领域也可能表现不佳。“在所有这些模态之间找到合适的平衡点极具挑战性。”
AlQuraishi表示,这使得最终的模型训练起来更加“挑剔”。AlphaFold 2堪称“工程奇迹”,以至于OpenFold在首次训练中就基本能够复制它的效果。AlQuraishi告诉我,OpenFold 3的训练则需要更多“精心呵护”。
需要生成的数据量也增加了100倍。谷歌DeepMind使用了AlphaFold 2中数千万个置信度最高的预测结果来扩充AlphaFold 3的训练集,并且使用了比AlphaFold 2多得多的多序列比对(MSA)。OpenFold不得不重复上述所有步骤。目前正在参与OpenFold 3项目的博士生卢卡斯·雅罗什(Lukas Jarosch )告诉我,OpenFold 3正在构建的合成数据库可能是学术实验室计算出的规模最大的数据库。
所有这些都需要大量的计算资源。OpenFold 的业务拓展经理Mallory Tollefson在去年 12 月告诉我,该项目可能已经使用了价值约 1700 万美元的计算资源,这些资源来自各方的捐赠。其中很多用于创建数据集:AlQuraishi 估计,创建这些数据集的成本约为 1500 万美元。
OpenFold 具有不寻常的结构
协调所有这些计算工作需要大量精力。“穆罕默德·库雷希肯定需要动用很多关系才能让这样一个庞大的项目在实践中顺利进行,”雅罗什说道。
OpenFold 的组织结构及其在开放分子软件基金会 (Open Molecular Software Foundation ) 的成员身份正是该项目的关键所在。我认为这也体现了一种巧妙的激励机制。
其他团队更快地发布了 AlphaFold 3 的部分复制版本:例如,Chai Discovery 公司于 2024 年 9 月发布了Chai-1,而 OpenFold 3 预览版则直到 2025 年 10 月才发布。目前,需要开放版本的科学家正在使用其他模型:我采访的几位人士都对 2025 年 6 月发布的Boltz-2赞不绝口。但这些复制版本要么由公司开发,要么由公司管理:Boltz 最近注册成为一家公益公司。
公司可以迅速行动并调动资源,但也有动机关闭其模型的访问权限,以便将产品授权给制药公司。
尽管个体学者获取资源的机会较少,但他们仍然有动机不分享具有商业价值的研究成果。德克萨斯大学奥斯汀分校教授威尔克表示,在某些领域,例如测量蛋白质与潜在药物的结合方式,“人们从未真正公开过代码,因为他们一直认为可以利用这些代码赚钱。” 他说,这种想法已经阻碍了该领域的发展“数十年”。
然而,据 Jarosch 估计,OpenFold“非常致力于长期开源,不会涉足任何商业领域”。他们是如何做到这一点的呢?部分原因是依靠制药公司的资金支持。
乍一看,制药公司似乎不太可能成为开源软件的推动者。众所周知,它们对知识产权的保护极其严密,例如其科学家通过实验确定的数十万种蛋白质结构。但制药公司需要一些它们自身难以开发的AI工具。
1700万美元用于计算资源是一笔巨款。但如果由37个人平分,就比从Alphabet旗下的Isomorphic等商业供应商那里购买模型授权要划算得多。再加上可以提前使用模型以及对研究重点进行投票的权利,OpenFold就成了一个极具吸引力的资助项目。
如果制药公司能够得逞,他们很可能会想要独占OpenFold的模型。(OpenFold的成员之一Apheris正在构建一个联邦化的OpenFold 3微调版本,专供那些提供专有训练数据的制药公司使用。)但对于实际构建模型的学术界人士来说,采用完全开放的模型不失为一个好的折衷方案。
从学术角度来看,这种合作关系也极具吸引力。制药公司的资源使得像 OpenFold 这样的大型项目更容易运行。OpenFold 的全职软件工程师Jennifer Wei表示,他们捐赠的计算资源更适合大规模训练,因为作业不像国家实验室那样受限于一天或一周的时间。此外,资金投入加上开源使命,有助于吸引像 Wei(一位前谷歌员工)这样的工程人才来编写高质量的代码。
制药行业的参与也使这项研究更具实际应用价值。博士生卢卡斯·雅罗什表示,他很感谢来自行业的帮助。“我希望让共折叠模型对实际药物研发产生重大影响,”他告诉我。
这些公司也提供了非常有益的反馈。“要建立真正模拟真实世界环境的基准非常困难,”Jarosch说道。制药公司拥有专有数据集,可以用来衡量模型在实践中的表现,但他们很少公开分享这些结果。OpenFold与制药公司的联系为获取高质量的反馈提供了一个天然的渠道。
当我问阿尔库雷希为什么留在学术界而不是去创业时,他告诉我两点。首先,他想“真正去探究一些基础性问题”,即使这些问题不能立即带来收益。他最终的目标是能够在计算机上完全模拟一个完整的工作单元。如果这可能需要几十年才能实现,他又该如何获得风险投资呢?
其次,目睹法学硕士(LLM)项目日益受限的经历,凸显了开源的重要性。“我以前从未想过自己会如此在意开源,”他告诉我,“现在我更像是一位真正的开源倡导者了。”
OpenFold 并没有推出 OpenFold 2。OpenFold 将其第二个模型命名为 OpenFold 3,是为了与它试图复现的 AlphaFold 版本保持一致。事实证明,这种令人困惑的模型命名并非 LLM 独有。
Boltz声称将保持其模型开源,并专注于围绕该模型提供端到端服务,例如根据企业的定制数据进行微调。情况或许会如此,但Boltz的最终动机指向的是从企业身上榨取尽可能多的利润。
原文: https://www.understandingai.org/p/an-unlikely-ally-for-open-source