一些人问我们为什么不预先注册我们的马铃薯饮食研究的分析。我们认为这表明了对预注册的用途、科学的全部内容以及我们首先运行马铃薯饮食的原因存在某种混淆。
预注册的早期起源是医学试验的注册,这是为了解释发表偏倚而引入的。人们担心,如果一项关于新疗法的医学研究发现该疗法无效,那么结果会让人记忆深刻(他们可能是对的)。他们的解决办法是建立医学研究登记册,这样人们就可以知道哪些研究按计划完成,哪些是 MIA。从这个意义上说,我们最初宣布马铃薯饮食的帖子是一个注册,因为如果我们从未发布后续内容,那就很明显了。
我们今天所知的预注册是为了应对复制危机而发明的。从 2011 年左右开始,心理学家开始注意到他们所在领域的大型论文无法复制,这些令人不安的观察结果慢慢滚雪球般演变成一场全面危机(因此称为“复制危机”)。
研究人员开始围绕着一些改革想法团结起来,其中最受欢迎的提议之一是预注册。当时,许多人将预注册视为拯救这艘沉没的心理科学之船(以及所有其他看起来即将泄漏的船)的一种方式。
早在 2013 年,就可以在像这封致《卫报》的公开信和OSF 上找到预注册的呼吁,人们已经在谈论鼓励使用像这样的时髦徽章进行预注册:

但尽管早期的热情,预注册并不是一个普遍的解决办法。它有少量用例,而且这些用例是特定的。成为一名优秀的统计学家的一部分是知道如何预先注册一项研究并知道何时适用预先注册,但它并不适用于所有范围。我们认为预注册有两个特定的好处——一个给研究团队,一个给观众。
我们之前已经预注册了研究,根据我们的经验,对研究人员的最大好处是预注册鼓励您提前计划您的分析。当你在没有足够远的想法的情况下进行研究时,有时你会取回数据,你会想我该怎么做,我希望我设计的研究不同。但到那时为时已晚。预注册有助于解决这个问题,因为您必须事先制定整个计划,这有助于确保您没有遗漏一些明显的东西。这对研究团队来说非常方便,因为它可以帮助他们避免让自己尴尬,但对读者来说意义不大。
观众从预注册中获得的主要好处是,预注册可以明确哪些分析是“确认性的”,哪些是“探索性的”。有些分析你计划一直做(“确认性”;不,这对我们也没有任何意义),有些你只在看到数据时才做,你想,这是什么东西(“探索性的” ”;你是瓦斯科·达·伽马)。
 探索性分析
探索性分析这本身没问题,因为它确实有助于防止p-hacking ,这是复制危机的主要原因之一。当你做一个项目时,你可以用许多不同的方式分析数据,其中一些分析看起来会比其他分析更好。如果你做了足够多的分析,你几乎可以保证找到一些看起来相当不错的东西。这就是 p-hacking 背后的逻辑,而预注册使 p-hack 变得更加困难,因为理论上你必须从一开始就告诉人们你打算做什么分析。
(这仅适用于由于诚实错误导致的 p-hacking,这是可能的。但是没有什么可以阻止真正的欺诈者收集数据、分析数据、选择看起来最好的分析,然后“预”注册它,并使其看起来像是他们一直在计划这些分析。当然,最糟糕的欺诈者也可以伪造数据。)
但他们并不总是告诉你: p-hacking 只是一个问题,如果你在实际需要推论统计的狭窄范围内进行研究。没有 p 值,没有 p-hacking。虽然推论统计很方便,但您希望尽可能避免在该范围内进行研究。如果你不断发现自己在寻找那些 p 值,那就是有问题了。
当发现看起来可能是噪音的结果时,统计数据很有用,但您不确定。假设我们正在测试一种新的疾病治疗方法。我们有一组 100 名接受治疗的患者和一组 100 名未接受治疗的对照组。如果 52/100 人在接受治疗后恢复,而对照组的恢复率为 42/100,则很难判断治疗是否有帮助,或者差异是否只是噪音。你不能只看一眼,但卡方检验可以告诉你 p = .013,这意味着我们只有 1.3% 的机会会从噪声中看到类似的东西。在这种情况下,统计数据很有帮助。
但是,如果我们看到 43/100 人通过治疗恢复,而对照组为 42/100,那么进行统计测试将毫无意义。您可以通过观察来判断这与噪声 (p > .50) 非常一致。如果我们看到 98/100 人通过治疗恢复,而对照组为 42/100,那么进行统计测试同样毫无意义。您可以通过查看它来判断这与噪声 (p < .00000000000001) 非常不一致。如果某样东西通过了眼间创伤测试(结论在你的眼睛之间),你不需要拿出统计数据。
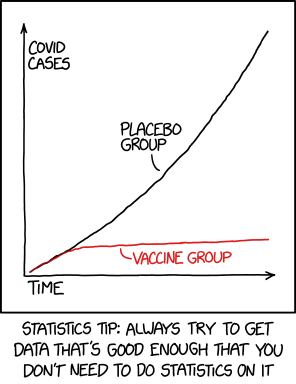
如果您正在查看其他人的数据,您可能需要提取统计数据来确定某件事是否是真实的发现,或者它是否与噪音一致。如果您正在处理因不相关原因而收集的大型数据集,您可能需要像多元回归这样的技术来尝试解开复杂的关系。或者,如果您专注于收集数据昂贵和/或耗时的某些方法,例如 fMRI,由于样本量小,您可能不得不使用统计数据。
但是对于普通的实验者来说,你可以从试点研究中了解效果大小,然后你可以选择任何你需要的样本量,以便能够清楚地检测到这种效果。大多数实验主义者不需要p值,时期。
更好的是,你可以尽量避免微小的影响,研究大于中型,甚至大于大型的影响。总而言之,您可以选择研究巨大的影响。
 我喜欢我的女人就像我喜欢我的咖啡
我喜欢我的女人就像我喜欢我的咖啡我们并不真正关心工作和不工作之间的简单区别。曼哈顿计划旨在制造巨大的炸弹。如果炸弹爆炸了,但只产生了相当于 0.1 公斤的 TNT,它会“起作用”,但也会令人大失所望。当我们谈论某件事是巨大的时,我们的意思是它不仅在工作,而且真的在工作。在三位一体测试当天,集结的科学家们对炸弹的最终产量进行了赌注:
Edward Teller 是最乐观的,他预测 TNT 有 45 公斤(190 TJ)。他戴着手套来保护自己的手,在政府提供给每个人的电焊护目镜下面戴着太阳镜。 Teller 也是少数几个真正观看测试的科学家之一(戴上眼睛保护装置),而不是听从命令转身躺在地上。他还带来了防晒霜,并与其他人分享。
其他人则不那么乐观。 Ramsey 选择了 0(完全哑弹),Robert Oppenheimer 选择了 0.3 公斤 TNT(1.3 TJ),Kistiakowsky 选择了 1.4 公斤 TNT(5.9 TJ),Bethe 选择了 8 公斤 TNT(33 TJ)。最后一个到达的拉比默认带走了 18 公斤 TNT(75 TJ),这将为他赢得游泳池。在一次视频采访中,Bethe 表示,他选择的 8 kt 正是 Segrè 计算的值,并且他被 Segrè 的权威所左右,而不是 Segrè 小组中一个更年轻的 [但未透露姓名的] 成员,他计算了 20 kt。恩里科·费米提出要与在场的顶级物理学家和军方打赌,看看大气层是否会被点燃,如果会点燃,它是否会摧毁国家,或者焚烧整个星球。
最终产量约为 25 千吨。再次,巨大的。
研究一个真正巨大的效应使得 p-hacking 成为一个问题。你要么看到它,要么你没有。拥有足够大的样本量也是如此。如果你有两个,fuggedaboudit。像这样的研究不需要预先注册,因为它们不需要推论统计。如果怀疑的效果真的很强,并且研究是有效的,那么任何发现都将在图中清晰可见。

这就是为什么我们没有费心预先注册土豆饮食的原因。我们开始的案例研究表明,用当前的术语来说,效果大小确实是巨大的。安德鲁·泰勒在一年的时间里减掉了 100 多磅。 Chris Voigt 在 60 天内减掉了 21 磅。好多啊。
如果人们不能可靠地通过马铃薯饮食减掉几公斤,那么在我们看来,这种饮食是行不通的。我们对为了几磅而吵架不感兴趣。我们没有兴趣争论 p 值是 0.03 还是 0.07 或其他。如果马铃薯饮食效果不佳,我们就不想要它。幸运的是,它确实很有效。
(我们没有报告马铃薯饮食的显着性检验,因为我们认为不需要推论统计,但如果我们有,相关的 p 值将是 0.00000000000000022)
寻找那些……工作得很好的东西曾经发生过什么。没有人对防晒霜是否有效存在学术争论。没有人争论青霉素或脊髓灰质炎疫苗。毫无疑问, 可卡因是一种很棒的、令人兴奋的、非常美妙的局部麻醉剂。当有人将可卡因注入你的脑脊液时,你他妈知道。
我们怀念那个精神勇敢的时代,男人是男人,女人是男人,孩子是男人,各种飞蛾是男人,狗是鹅,科学家们试图做出非常有效的发现。不知怎的,人们似乎忘记了。为什么我们要寻找几乎不起作用的东西?
也许统计数据是罪魁祸首。毕竟,统计数据仅在您处于能够看到效果的边缘时才有用。也许所有这些统计培训都鼓励人们去寻找可以检测到的最小影响,因为所有统计数据都非常适合。但这是一个错误。统计前的科学家们是对的。吸烟和肺癌,那里的顶级工作,巨大的影响。
我们知道并非所有值得研究的东西都会产生很大的影响。有些重要的事情很复杂,很难被发现。我们应该寻找能够将癌症存活率提高 0.5% 的药物,或者只在具有 10,000 个观察值的数据集中出现的关系。我们不反对。我们以前做过这种工作,如果有必要我们会再做一次。
当没有其他东西可以追捕时,追踪一个小影响并不可耻。但是你的祖先尽可能地猎杀大型猎物。你也应该。
很好的狩猎。
原文: https://slimemoldtimemold.com/2022/07/21/on-the-hunt-for-ginormous-effect-sizes/