欧洲的 ChatGPT 用户现在可以使用网络表单或 OpenAI 提供的其他方式来请求删除他们的个人数据,以停止聊天机器人处理(和生成)有关他们的信息。他们还可以请求选择不使用他们的数据来训练其 AI。
为什么有人不希望他们的个人数据成为人工智能的素材?可能的原因有很多,尤其是 OpenAI 一开始从未征求过许可这一事实——尽管隐私是一项人权。换句话说,人们可能会担心这种强大且易于访问的技术可以用来揭示具名个人的什么信息。或者确实对构成虚假信息的大型语言模型 (LLM) 的核心缺陷提出异议。
ChatGPT 很快就证明自己是一个老练的说谎者,包括关于具名个人的说谎者——如果人工智能能够自动生成关于你或你身边的人的假新闻,就有可能造成名誉受损或其他类型的伤害。
试想一下,如果这种 AI 模型被滥用,那么训练有素的模仿你个人谈话的方式可能会对你(或你所爱的人)做些什么。
另一批问题涉及知识产权。如果您从事白领工作,您可能会担心生成式 AI 会推动对特定写作风格或其他一些核心专业知识的按钮式商业利用,这可能会使您自己的劳动变得多余或价值降低。而且,这些 AI 模型背后的科技巨头通常不会为利用数据牟利的个人提供任何补偿。
您可能还有一个非个人的担忧——例如 AI 聊天机器人扩大偏见和歧视的风险——并且只是希望您的信息不发挥任何作用。
或者,如果在依赖数据的 AI 服务时代,少数科技巨头继续积累大量数据,您可能会担心竞争市场和创新的未来。虽然从池中删除您自己的数据只是沧海一粟,但这是一种表达积极异议的方式,这也可以鼓励其他人也这样做——扩大为集体抗议行动。
此外,在通过更强有力的法律来管理如何应用 AI 之前,您的数据被如此不透明地使用,您可能会感到不舒服。因此,在安全可靠地使用如此强大的技术的适当法律治理框架之前,您可能更愿意保留您的数据;即等到对生成 AI 操作员应用更强大的检查和平衡。
虽然个人可能想要保护他们的信息免受大数据挖掘 AI 巨头的影响的原因有很多,但目前只有有限的控制措施。而且这些有限的控制大多只适用于数据保护法已经适用的欧洲用户。
向下滚动以了解有关如何行使可用数据权利的详细信息——或继续阅读上下文。
从病毒感觉到监管干预
ChatGPT 今年不容错过。近几个月来,“通用”AI 聊天机器人的病毒式传播已经见证了这项技术在主流媒体上的传播,来自各个主题领域的评论员开始尝试并被人类响应的模拟所震撼,尽管如此,不是人类。它刚刚接受了我们基于网络的大量聊天(以及其他数据源)的培训,可以作为人们交流方式的完美模仿。
然而,这种看似功能强大的自然语言技术的存在将注意力转移到了 ChatGPT 的开发细节上。
值得注意的是,围绕 ChatPT 的热议引起了欧盟隐私和数据保护监管机构的特别关注——意大利数据保护监管机构在 3 月底根据欧盟通用数据保护条例 (GDPR) 赋予的权力进行了早期干预),导致 ChatGPT 在上月初暂时停用。
监管机构提出的一个主要问题是,OpenAI 在开发这项技术时是否合法地使用了人们的数据。它正在继续调查这个问题。
意大利的监管机构还对 OpenAI 提供的有关其如何使用人们数据的信息质量提出了质疑。如果没有适当的披露,它是否也符合 GDPR 的公平性和问责制要求也存在疑问。
此外,监管机构表示担心未成年人访问 ChatGPT 的安全。它希望公司增加年龄验证技术。
欧盟的通用数据保护条例 (GDPR) 还为该地区的人们提供了一套数据控制权——例如要求更正有关他们的不正确信息或删除他们的数据的能力。如果我们在过去几个月中了解了有关 AI 聊天机器人的任何信息,那就是它们撒谎的程度。 (又名技术解决方案的“幻觉”)。
在意大利的 DPA 介入警告 OpenAI 它怀疑存在一系列 GDPR 违规行为后不久,该公司推出了一些新的隐私工具——为用户提供一个按钮来关闭聊天记录功能,该功能记录了他们与聊天机器人的所有互动,并表示这将导致在历史记录功能被禁用时开始的对话中没有被用于训练和改进其 AI 模型。
随后,OpenAI 进行了一些隐私披露并提出了额外的控制措施——时间安排是为了满足意大利 DPA 为其实施初步措施包以遵守欧盟隐私规则设定的最后期限。结果是 OpenAI 现在为网络用户提供了一些关于它如何处理他们的信息的发言权——尽管它提供的大部分让步都是针对特定地区的。因此,保护您的信息免受大数据驱动的 AI 矿工攻击的第一步是住在欧盟(或欧洲经济区),那里存在数据保护权并正在积极执行。
就目前而言,英国公民仍然受益于嵌入其国家法律的欧盟数据保护框架——因此也享有 GDPR 的全面权利——尽管政府的脱欧后改革看起来将淡化国家数据保护制度,因此国内的做法会如何改变还有待观察。 (英国部长们最近也表示,他们不打算在可预见的未来引入任何应用人工智能的定制规则。)
在欧洲之外,加拿大隐私专员正在调查有关该技术的投诉。其他国家/地区已经通过了 GDPR 式的数据保护制度,因此监管机构有权灵活调整。
如何要求 OpenAI 删除关于你的个人数据
OpenAI 表示,“某些司法管辖区”(例如欧盟)的个人可以通过填写此表格反对其 AI 模型处理他们的个人信息。这包括请求删除 AI 生成的关于您的参考资料的能力。尽管 OpenAI 指出它可能不会批准所有请求,因为它必须“根据适用法律”在隐私请求与言论自由之间取得平衡。
用于删除您请求的数据的 Web 表单标题为“OpenAI 个人数据删除请求”。这是它的链接:https: //share.hsforms.com/1UPy6xqxZSEqTrGDh4ywo_g4sk30
要求网络用户向其提供他们的联系数据和请求所针对的数据主体的详细信息;其法律适用于此人案件的国家;说明他们是否是公众人物(如果是公众人物,则提供更多关于他们是什么类型的公众人物的背景信息);以提示的形式提供数据处理的证据,这些提示会从模型中生成响应,其中提到数据主体和相关输出的屏幕截图。
还要求用户宣誓声明所提供的信息是准确的,并承认在提交表格之前,OpenAI 可能不会对不完整的提交内容采取行动。
这个过程类似于谷歌多年来提供的“被遗忘权”网络表单——最初是为了欧洲人通过从其搜索引擎结果中删除不准确、过时或不相关的个人数据来寻求行使 GDPR 权利。
GDPR 为个人提供了除请求数据删除之外的多项权利——例如要求更正、限制他们的信息或转移他们的个人数据。
OpenAI 规定,个人可以通过发送电子邮件至[email protected]寻求对其培训信息中可能包含的个人信息行使此类权利。然而,该公司告诉意大利监管机构,目前纠正其模型生成的不准确数据在技术上是不可行的。因此,它可能会通过提供删除个人数据来响应电子邮件请求,要求更正 AI 生成的虚假信息。 (但是,如果您提出了这样的请求并得到了 OpenAI 的回复,请发送电子邮件至 [email protected] 与我们联系。)
在其博客文章中,OpenAI 还警告说,它可能出于其他原因拒绝(和/或仅部分采取行动)请求,写道:“请注意,根据隐私法,某些权利可能不是绝对的。如果我们有合法理由,我们可能会拒绝请求。但是,我们努力优先保护个人信息并遵守所有适用的隐私法。如果您觉得我们没有充分解决问题,您有权向当地监管机构投诉。”
该公司如何处理欧洲人的数据主体访问请求 (DSAR) 可能会决定 ChatGPT 是否面临一波用户投诉,这可能导致该地区未来更多的监管执法。
由于 OpenAI 尚未建立负责处理欧盟用户数据的本地法律实体,因此任何成员国的监管机构都有权对其补丁采取行动。因此,意大利迅速采取行动。
如何要求 OpenAI 不要使用您的数据来训练 AI
在意大利 DPA 的干预之后,OpenAI 修改了其隐私政策,声明其处理人们数据以训练其 AI 所依赖的法律依据在 GDPR 中称为“合法利益”(LI)。
在其隐私政策中,OpenAI 写道,其处理“您的个人信息”的法律依据包括 [强调我们的]:
我们在保护我们的服务免受滥用、欺诈或安全风险方面的合法权益,或者在开发、改进或推广我们的服务方面的合法权益,包括在我们训练我们的模型时。这可能包括处理帐户信息、内容、社交信息和技术信息。
随着意大利监管机构(和其他机构)继续调查,依赖 LI 的通用 AI 聊天机器人是否会被视为 GDPR 下处理的适当和有效的法律依据仍然存在疑问。
在我们做出任何最终决定之前,这些详细调查可能需要一些时间——这可能会导致它停止使用 LI 进行此处理的命令(这将使 OpenAI 可以选择征求用户的同意,从而使其能力复杂化以目前的规模和速度开发技术)。尽管 EU DPA 可能最终决定在这种情况下使用 LI 是可以的。
与此同时,由于 OpenAI 声称依赖 LI,因此法律要求其向用户提供某些权利——特别是这意味着它必须提供反对处理的权利。
Facebook最近也被迫向欧洲用户提供这样的选择——即它处理他们的数据以定向行为广告——也是在转而声称 LI 作为其处理人们信息的法律依据之后。 (此外,鉴于 GDPR 包含对直接营销的任何数据处理的绝对要求——这可能在某种程度上解释OpenAI 热衷于强调它与广告技术巨头 Facebook 不属于同一行业,因此它声称:“我们不使用数据来销售我们的服务、广告或建立人们的档案——我们使用数据来使我们的模型更有帮助人们。”)
在其隐私政策中,ChatGPT 制造商通过了对依赖 LI 的反对要求的承认,将用户指向有关请求选择退出的更多信息——当它写道:“请参阅此处了解如何选择退出我们的说明使用您的信息来训练我们的模型。”
此链接打开另一篇博客文章,其中宣传人工智能将“随着时间的推移而改进”的概念,同时鼓励用户不要通过声称“共享您的数据”来行使反对个人数据处理的权利与我们一起……帮助我们的模型变得更准确,更好地解决您的特定问题,它还有助于提高它们的一般能力和安全性”。 (但是,好吧,如果这些东西已经在没有询问的情况下被拿走了,我们可以称之为共享数据吗?)
然后,OpenAI 为用户提供了两种选择,可以让他们的数据退出训练:通过(另一个)网络表单或直接在帐户设置中。
您可以通过填写此网络表格(适用于 ChatGPT 的个人用户)并称为“用户内容选择退出请求”来选择不使用您的数据来训练其 AI。
用户还可以通过 ChatGPT 帐户设置(在“数据控制”下)禁用对其数据的训练。假设他们有一个帐户。
但是——请注意! – 选择退出的设置路径充满了黑暗模式,试图阻止用户关闭 OpenAI 使用他们的数据来训练其 AI 模型的能力。
(在这两种情况下,都不清楚非 ChatGPT 用户如何选择不处理他们的数据,因为公司要么需要您有一个帐户,要么通过表格请求您的帐户详细信息;因此我们要求它澄清一下。)
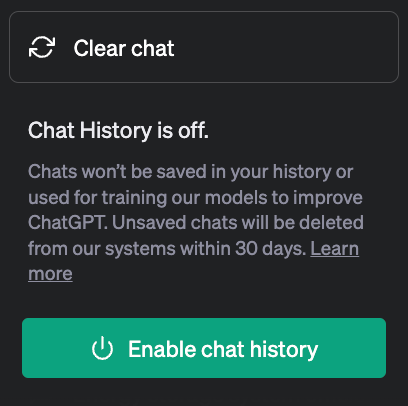
要找到“数据控制”菜单,请单击屏幕左下方(聊天记录栏下方)帐户名旁边的三个点;然后点击“设置”;然后单击以“显示”上述数据控件(漂亮的深色图案隐藏了此开关!);然后滑动开关以关闭“聊天记录和培训”。
说 OpenAI 不鼓励用户使用设置路径选择退出训练是一种轻描淡写的说法。尤其是因为它将此操作与无法访问您的 ChatGPT 历史记录的不便联系起来。但是当你将它切换回来时,你的聊天就会重新出现(至少如果你在 30 天内重新启用历史记录,根据其先前披露的数据保留政策。)
此外,在您禁用训练后,历史聊天的侧边栏将被一个颜色鲜艳的按钮所取代,该按钮显示在视线周围,永久性地提示用户“启用聊天历史”。这个按钮上没有提到点击它会切换回 OpenAI 训练你的数据的能力。相反,OpenAI 为一个无意义的电源按钮图标找到了空间——大概是另一种视觉技巧,鼓励用户打开该功能,以便它可以重新访问他们的数据。
图片来源:Natasha Lomas/TechCrunch
鉴于选择设置方法来阻止培训的用户将失去 ChatGPT 的聊天历史记录功能,提交网络表单看起来提供了更好的途径——因为从理论上讲,尽管要求您的对话不成为训练饲料。 (而且,至少,您已经以正式格式记录了您的反对意见,这可能比打开/关闭亮绿色按钮更重要。)
也就是说,在撰写本文时,尚不清楚 OpenAI 是否会在通过表单提出反对的情况下禁用聊天历史记录功能,一旦它处理了 Web 表单提交,要求数据不用于训练 AI。 (再次,我们已要求公司澄清这一点,如果我们得到它,将更新这份报告。)
OpenAI 的博客文章中还有一个警告——它写道选择退出:
我们会保留您与我们互动的某些数据,但我们会采取措施减少训练数据集中的个人信息量,然后再将其用于改进我们的模型。这些数据帮助我们更好地了解用户需求和偏好,使我们的模型随着时间的推移变得更加高效。
因此,当用户要求他们的信息不是 AI 培训饲料时,与您输入的其他类型的信息相比,它可能仍会继续处理的信息,甚至不清楚哪些确切的个人数据被防火墙从其培训池中隔离出来……
简而言之,这闻起来像软糖。 (或者业内称为合规剧院。)
事实上,GDPR 对个人数据有一个广泛的定义——这意味着它不仅仅是属于法规框架的直接标识符(例如姓名和电子邮件地址),还有许多类型的信息可以用来和/或结合起来识别一个自然人人。因此,这意味着这里的另一个关键问题是,当用户选择退出时,OpenAI 实际应用于其数据处理活动的减少量有多少?透明度和公平性是 GDPR 的其他关键原则。因此,在可预见的未来,这类问题可能会让欧洲数据保护机构忙个不停。
How to ask OpenAI for your personal data to be deleted or not used to train its AIs Natasha Lomas最初发表于TechCrunch