LLM 0.26 版本带来了我启动该项目以来最重要的新功能:工具支持。现在,您可以使用 LLM CLI 工具(以及Python 库)授予 OpenAI、Anthropic、Gemini 的 LLM 以及 Ollama 的本地模型访问任何可以表示为 Python 函数的工具的权限。
LLM 现在还具有 工具插件,因此您可以安装一个插件,为您当前使用的任何模型添加新功能。
这里有很多内容需要介绍,但以下是重点:
- LLM 现在可以运行工具了!您可以从插件中安装工具,并使用
--tool/-T name_of_tool按名称加载它们。 - 您还可以使用
--functions选项在命令行中传入 Python 函数代码。 - Python API 也支持工具:
llm.get_model("gpt-4.1").chain("show me the locals", tools=[locals]).text() - 工具可以在异步和同步环境中工作。
本文涵盖的内容如下:
尝试一下
首先,安装最新的 LLM 。它可能还没有在 Homebrew 上,所以我建议使用pip 、 pipx或uv :
uv 工具安装 llm
如果您已经拥有它,请升级它。
uv工具升级llm
工具可以与其他供应商合作,但目前我们还是选择 OpenAI。给 LLM 一个 OpenAI API 密钥
LLm 密钥设置openai #在此处粘贴密钥
现在让我们运行第一个工具:
llm --tool llm_version “什么版本? ” --td
以下是我得到的结果:
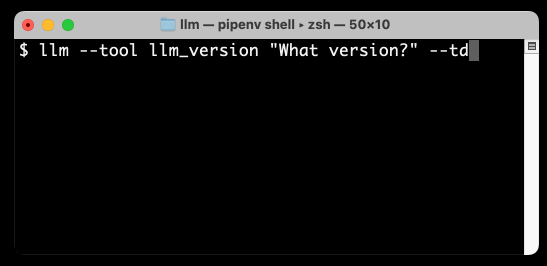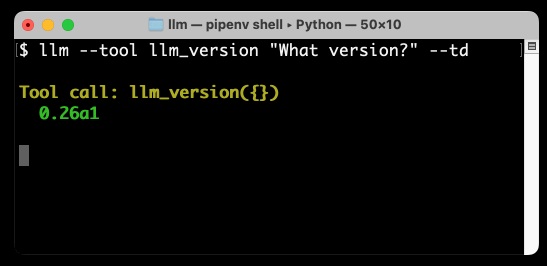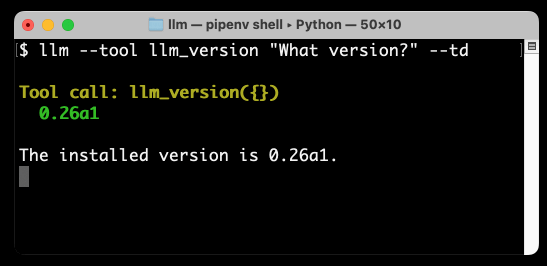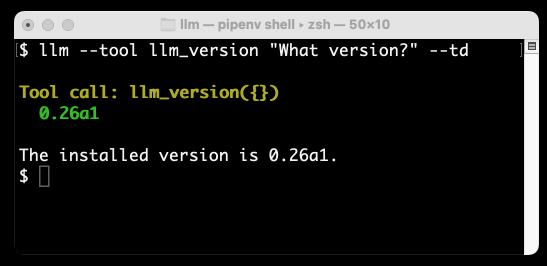
llm_version是 LLM 附带的一个非常简单的演示工具。运行--tool llm_version会将该工具暴露给模型——您可以多次指定该选项以启用多个工具,并且它还有一个更短的-T版本,可以减少输入量。
--td选项代表--tools-debug – 它使 LLM 输出有关工具调用及其响应的信息,以便您可以窥视幕后情况。
这里使用的是默认的 LLM 模型,通常是gpt-4o-mini 。我通过运行以下命令将其切换到gpt-4.1-mini (效果更好,但价格略高):
LLM 模型默认 GPT-4.1-mini
您可以使用-m选项尝试其他模型。以下是使用o4-mini运行llm_time内置工具的类似演示的方法:
llm --tool llm_time “现在几点? ” --td -m o4-mini
输出:
Tool call: llm_time({}){ “utc_time” : “ 2025-05-27 19:15:55 UTC ” , "utc_time_iso" : " 2025-05-27T19:15:55.288632+00:00 " , "local_timezone" : " PDT " , "local_time" : " 2025-05-27 12:15:55 " , "timezone_offset" : " UTC-7:00 " , “is_dst” :真 }当前时间为 2025 年 5 月 27 日 12:15 PM PDT(UTC−7:00),对应 UTC 时间晚上 7:15。
来自(工具支持)插件的模型也可以工作。Anthropic 的 Claude Sonnet 4:
llm 安装' llm-anthropic>=0.16a2 ' LL.M 键设置人择 #在此处粘贴 Anthropic 键 llm --tool llm_version “什么版本? ” --td -m claude-4-sonnet
或者 Google 的 Gemini 2.5 Flash:
llm 安装' llm-gemini>=0.20a2 ' LL.M. 密钥设置Gemini #在此处粘贴 Gemini 键 llm --tool llm_version “什么版本? ” --td -m gemini-2.5-flash-preview-05-20
您甚至可以使用 Qwen3:4b 运行简单的工具,这是我使用Ollama运行的微型(2.6GB)模型:
ollama pull qwen3:4b llm 安装' llm-ollama>=0.11a0 ' llm --tool llm_version “什么版本? ” --td -m qwen3:4b
Qwen 3 调用该工具,稍微思考一下,然后打印出响应: 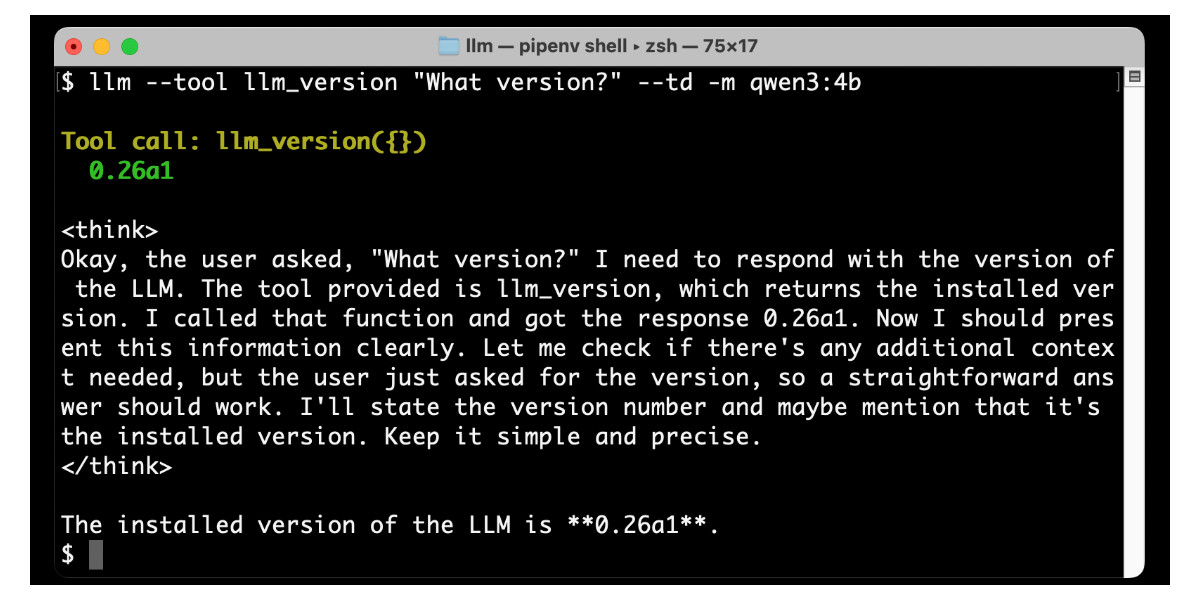
更多有趣的插件工具
这个演示目前为止还很弱。我们来做点更有趣的吧。
众所周知,法学硕士的数学很差。这让很多人深感震惊:难道我们迄今为止建造的最复杂的计算机系统连两个大数相乘都做不到吗?
我们可以用工具来解决这个问题。
llm-tools-simpleeval插件公开了 Daniel Fairhead 开发的simpleeval “简单、安全、沙盒、可扩展的 Python 表达式求值器”库。该库提供了一个足够健壮的沙盒,用于执行简单的 Python 表达式。
运行计算的方法如下:
llm 安装 llm-tools-simpleeval llm -T simpleeval
尝试一下:
llm -T simple_eval '计算 1234 * 4346 / 32414 并求其平方根' --td
我得到了这个 – 它首先尝试了sqrt() ,然后当它不起作用时切换到** 0.5 :
Tool call: simple_eval({'expression': '1234 * 4346 / 32414'}) 165.45208860368976 Tool call: simple_eval({'expression': 'sqrt(1234 * 4346 / 32414)'}) Error: Function 'sqrt' not defined, for expression 'sqrt(1234 * 4346 / 32414)'. Tool call: simple_eval({'expression': '(1234 * 4346 / 32414) ** 0.5'}) 12.862818066181678 The result of (1234 * 4346 / 32414) is approximately 165.45, and the square root of this value is approximately 12.86.
到目前为止我已经发布了四个工具插件:
- llm-tools-simpleeval——如上所示,对数学等事物的简单表达式支持。
- llm-tools-quickjs – 提供对沙盒化 QuickJS JavaScript 解释器的访问,允许 LLM 运行 JavaScript 代码。环境在调用之间保持不变,因此模型可以设置变量、构建函数并在以后重用它们。
- llm-tools-sqlite – 对本地 SQLite 数据库的只读 SQL 查询访问。
- llm-tools-datasette – 针对远程Datasette实例运行 SQL 查询!
现在让我们尝试一下 Datasette:
llm 安装 llm-tools-datasette llm -T ' Datasette("https://datasette.io/content") ' --td "哪个拥有最多的星星? "
这里的语法略有不同:Datasette 插件就是我所说的“工具箱”——一个内部有多个工具并可以用构造函数进行配置的插件。
将--tool指定为Datasette("https://datasette.io/content")为插件提供了它应该使用的 Datasette 实例的 URL – 在本例中是支持 Datasette 网站的内容数据库。
以下是输出,为了简洁起见,架构部分被截断:
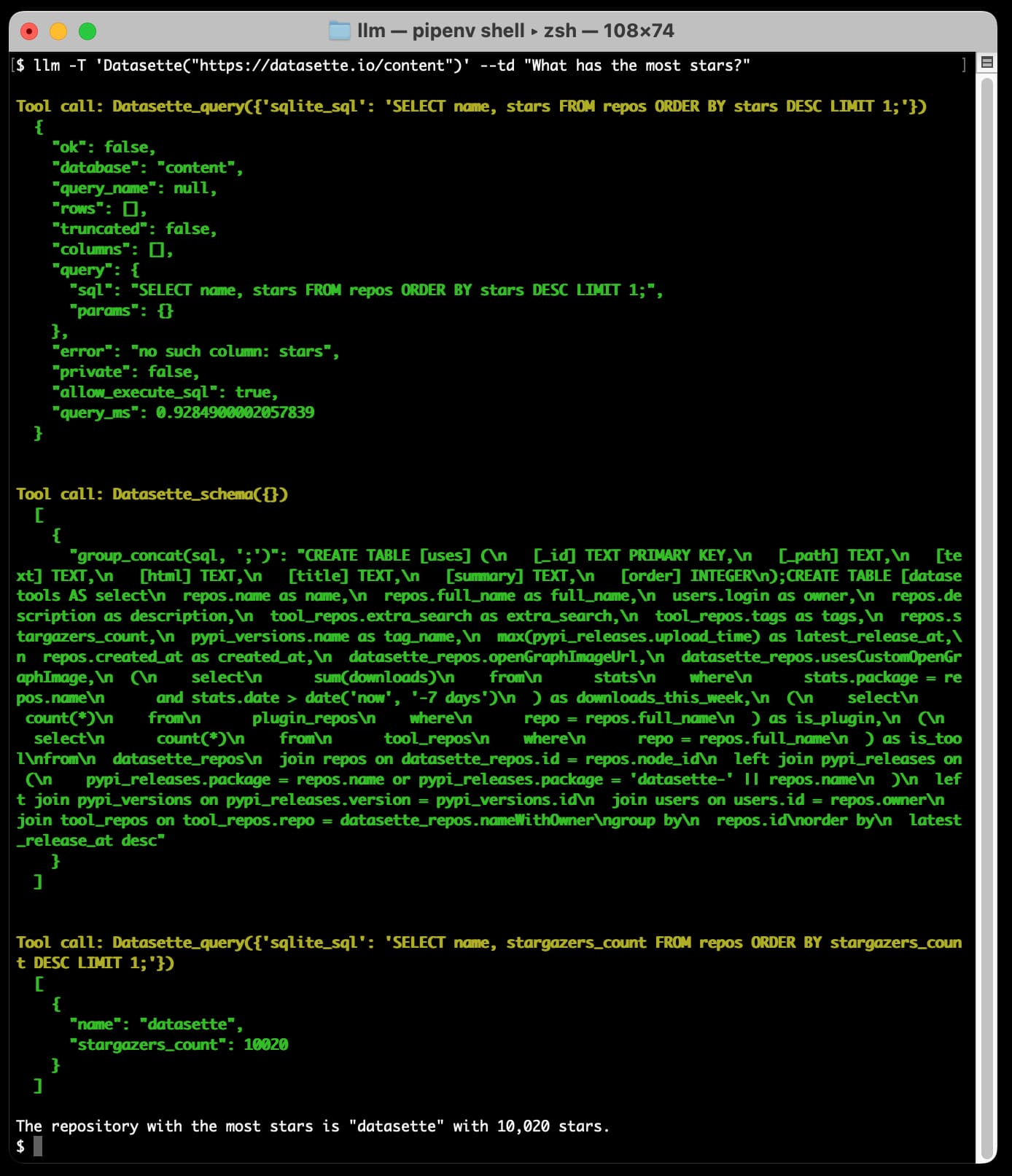
这个问题触发了三次调用。模型一开始就猜测查询!它尝试了SELECT name, stars FROM repos ORDER BY stars DESC LIMIT 1 ,但由于stars列不存在而失败。
该工具调用返回了一个错误,因此模型再次尝试 – 这次调用Datasette_schema()工具来获取数据库的模式。
基于该模式,它组装并执行正确的查询,并输出对结果的解释:
获得星标最多的存储库是“datasette”,有 10,020 颗星。
对我来说,走到这一步就像是一次真正的Penny Arcade Minecraft 时刻。这里的可能性是无限的。如果你能为它编写一个 Python 函数,你就可以从法学硕士(LLM)那里触发它。
带有--functions的临时命令行工具
我期待人们构建更多的插件,但使用 LLM CLI 工具的方式也更加结构化和更加临时: --functions选项。
这是受到我之前添加到 sqlite-utils 的类似功能的启发。
您可以使用--functions选项将一段文字 Python 代码直接传递给 CLI 工具,并且在那里定义的任何函数都将作为工具提供给模型。
下面是一个添加搜索我的博客功能的示例:
llm——函数' 导入 httpx def search_blog(q): “搜索 Simon Willison 博客” 返回 httpx.get("https://simonwillison.net/search/", params={"q": q}).content ' --td ' sqlite-utils 的三个特性' -s '使用 Simon 搜索'
这实现简直太坑了!我其实就是直接打开搜索页面,然后把 HTML 代码直接转储到模型里就行了。
不过,它确实有效——这有助于 GPT-4.1 系列现在处理一百万个令牌,因此繁琐的 HTML 不再是它们的问题。
(我不得不添加“使用 Simon 搜索”作为系统提示,因为如果没有它,模型会尝试自己回答问题,而不是使用我提供的搜索工具。工具的系统提示显然是一个大话题,Anthropic 自己的网络搜索工具有6,471 个指令标记!)
这是我刚才得到的输出:
sqlite-utils 的三个功能是:
- 它是一个用于操作 SQLite 数据库的组合 CLI 工具和 Python 库。
- 如果您尝试插入不太合适的数据(使用 alter=True 选项),它可以自动向数据库表添加列。
- 它支持插件,允许通过第三方或自定义插件扩展其功能。
更好的搜索工具应该有更详细的说明,并返回结果的相关片段,而不仅仅是每个结果的标题和第一段。不过,对于仅用四行 Python 代码就能实现的功能来说,这已经相当不错了!
LLM Python API 中的工具
LLM 既是一个 CLI 工具,又是一个 Python 库(类似于我的另一个项目sqlite-utils )。LLM Python 库在 LLM 0.26 中也增加了工具支持。
下面是一个简单的例子,解决了 LLM 中以前最难的问题之一:计算“strawberry”中 R 的数量:
导入llm def count_char_in_text ( char : str , text : str ) -> ;int : “char 在文本中出现了多少次?” 返回文本.count ( char ) 模型= llm.get_model ( "GPT-4.1-mini" ) chain_response =模型.chain ( “草莓里有 R 吗?” , 工具= [文本中的字符数], after_call =打印 ) 对于chain_response中的块: 打印(块,结束= “” ,刷新= True )
after_call=print参数是一种查看工具调用的方法,它相当于之前的--td选项的 Python 版本。
model.chain()方法是新增的:它与model.prompt()类似,但能够识别返回的工具调用请求,执行这些请求,然后使用结果再次提示模型。model.chain model.chain()可能会执行数十次响应,最终给出最终答案。
您可以迭代chain_response来输出模型返回的那些标记,甚至跨多个响应。
我得到了这个:
Tool(name='count_char_in_text', description='How many times does char appear in text?', input_schema={'properties': {'char': {'type': 'string'}, 'text': {'type': 'string'}}, 'required': ['char', 'text'], 'type': 'object'}, implementation=<function count_char_in_text at 0x109dd4f40>, plugin=None) ToolCall(name='count_char_in_text', arguments={'char': 'r', 'text': 'strawberry'}, tool_call_id='call_DGXcM8b2B26KsbdMyC1uhGUu') ToolResult(name='count_char_in_text', output='3', tool_call_id='call_DGXcM8b2B26KsbdMyC1uhGUu', instance=None, exception=None)单词“strawberry”中有 3 个字母“r”。
LLM 的 Python 库也支持asyncio ,并且工具可以是async def函数,正如这里所述。如果模型同时请求多个异步工具,该库将使用asyncio.gather()同时运行它们。
工具箱形式的工具也受支持:您可以将tools=[Datasette("https://datasette.io/content")]传递给该chain()方法以实现与之前的--tool 'Datasette(...)选项相同的效果。
我为什么花了这么长时间?
我跟踪llm-tool-use已经有一段时间了。我第一次看到这个技巧是在ReAcT 论文中,该论文首次发表于 2022 年 10 月(ChatGPT 首次发布前一个月)。我用几十行 Python 代码实现了这个技巧。这显然是一个非常巧妙的模式!
过去几年来,显而易见的是,使用工具是扩展语言模型能力最有效的途径。这其实很简单:你告诉模型可以使用哪些工具,然后让它输出特殊语法(JSON、XML 或tool_name(arguments) ,哪种都可以)来请求工具执行操作,然后停止。
您的代码会解析该输出,运行所请求的工具,然后使用结果向模型启动新的提示。
现在几乎所有模型都适用这种方法。大多数模型都经过专门的工具使用训练,并且有像Berkeley 函数调用排行榜这样的排行榜,专门追踪哪些模型在这方面表现最佳。
所有大型模型供应商——OpenAI、Anthropic、Google、Mistral、Meta——都在其 API 中嵌入了类似的功能,称为工具使用或函数调用。它们都遵循相同的底层模式。
本地运行的模型在这方面也越来越好。Ollama 去年增加了工具支持,并且也嵌入到了llama.cpp服务器中。
一段时间以来,LLM 显然需要增强对工具的支持。早在二月份,我就发布了LLM Schema 支持,作为实现这一目标的垫脚石。我很高兴终于完成了这项工作。
与LLM一贯的挑战一样,设计一个能够跨尽可能多的不同模型工作的抽象层是一大挑战。一年前,我觉得模型工具支持还不够成熟,无法解决这个问题。如今,供应商之间已经就如何实现这一点达成了非常明确的共识,这最终给了我实现它的信心。
两周前,我还在 PyCon US 上做了一个关于在大型语言模型上构建软件的研讨会,这给了我动力,让我最终得以在 alpha 版本中运行它!以下是该教程中的工具部分。
这就是代理商吗?
叹息。
我还是不喜欢用“代理”这个词。我担心开发者会把“工具”当成“循环体” ,普通人会把“工具”当成斯嘉丽·约翰逊配音的虚拟AI助手,学者们会抱怨恒温器。但在法学硕士(LLM)的世界里,我们似乎正朝着“工具”当成“循环体”的方向发展,而这正是我们面临的情况。
所以是的,如果您想构建“代理”,那么 LLM 0.26 是一个很好的方法。
LLM 中的工具下一步是什么?
我已经有一个LLM 工具 v2 里程碑,其中包含 13 个问题,主要涉及工具执行日志显示方式的改进,但也存在一些小问题,因此我决定不阻止此版本发布。工具标签中还有更多内容。
我最兴奋的是插件的潜力。
编写工具插件真的很有趣。我有一个llm-plugin-tools cookiecutter 模板,一直在用,我计划很快整理一个关于它的教程。
为更多模型插件添加工具支持还有很多工作要做。我已将 相关细节添加到高级插件文档中。本次提交添加了对 Gemini 的工具支持,很好地说明了其中涉及的内容。
是的,模型上下文协议 (MCP) 的支持显然也在议程上。MCP 正在以令人眼花缭乱的速度成为模型访问工具的标准方式。两周前,任何主要供应商的 API 都还不直接支持它。仅仅在过去的八天里,OpenAI、Anthropic和Mistral就添加了它!今天感觉它的发展速度快了很多。
我希望 LLM 能够充当 MCP 客户端,以便人们编写的任何 MCP 服务器都可以轻松访问,作为 LLM 的附加工具源。
如果您有兴趣进一步了解 LLM 的下一步发展,欢迎通过 Discord 与我们聊天。
标签:双子座、法学硕士、人择、人工智能代理、 OpenAI 、法学硕士工具使用、人工智能、 Ollama 、法学硕士、生成人工智能、项目
原文: https://simonwillison.net/2025/May/27/llm-tools/#atom-everything