任何人都可以越来越容易地用别人的声音制作出令人信服的音频,这让很多人感到紧张,这是理所当然的。 Resemble AI对生成的语音加水印的提议可能无法解决问题,但这是朝着正确方向迈出的一步。
AI 生成的语音被用于各种合法目的,从屏幕阅读器到替换配音演员(当然是在他们的许可下)。但与几乎所有技术一样,语音生成也可以被用于恶意目的,产生政客或名人的虚假引述。非常希望找到一种不依赖公关人员或仔细聆听的方法来辨别真假。
水印是一种通过在图像或声音上印上可识别的图案来显示其来源的技术。我们都见过明显的水印,例如图像上的徽标,但并非所有水印都如此引人注目。
在图像中,隐藏的水印可能会逐个像素地隐藏图案,使图像在人眼看来未被修改但可被计算机识别。音频也是如此:偶尔安静的声音编码信息可能不是随便的听众会听到的。
这些细微水印的问题在于,即使对媒体进行微小修改,它们也往往会被抹去。调整图像大小?这就是您的像素完美代码。对音频进行编码以进行流式传输?秘密音调被压缩得不复存在。
Resemble AI 是一批新的生成式 AI 初创公司之一,旨在使用微调的语音模型来制作配音、有声读物和其他通常由普通人的声音制作的媒体。但是,如果这些模型( 可能是根据演员提供的数小时音频进行训练)落入恶意人士手中,这些公司可能会发现自己处于公关灾难的中心,并可能承担严重的责任。因此,找到一种方法使他们的录音尽可能逼真,并且易于验证是否由 AI 生成,这非常符合他们的兴趣。
PerTh 是 Resemble 为此目的提出的水印过程,是“感知”和“阈值”的尴尬组合。
“我们已经开发了一个额外的安全层,它使用机器学习模型将数据包嵌入到我们生成的语音内容中,并在稍后恢复所述数据,”该公司在解释该技术的博客文章中写道。 “因为数据是不可察觉的,同时与语音信息紧密耦合,它既难以去除,又提供了一种验证给定剪辑是否由 Resemble 生成的方法。重要的是,这种‘水印’技术还可以容忍各种音频操作,如加速、减速、转换为 MP3 等压缩格式等。”
它依赖于人类处理音频的方式的一个怪癖,通过这种方式,具有高可听度的音调基本上“掩盖”了附近振幅较小的音调。因此,如果有人笑并且它在 5,000 赫兹、8,000 赫兹和 9,200 赫兹频率处产生峰值,您可以在几赫兹内同时出现的结构化音调中滑动,听众或多或少会察觉不到。但是如果你做对了,它们也能抵抗移除,因为它们非常接近音频的重要部分。
图表来了:
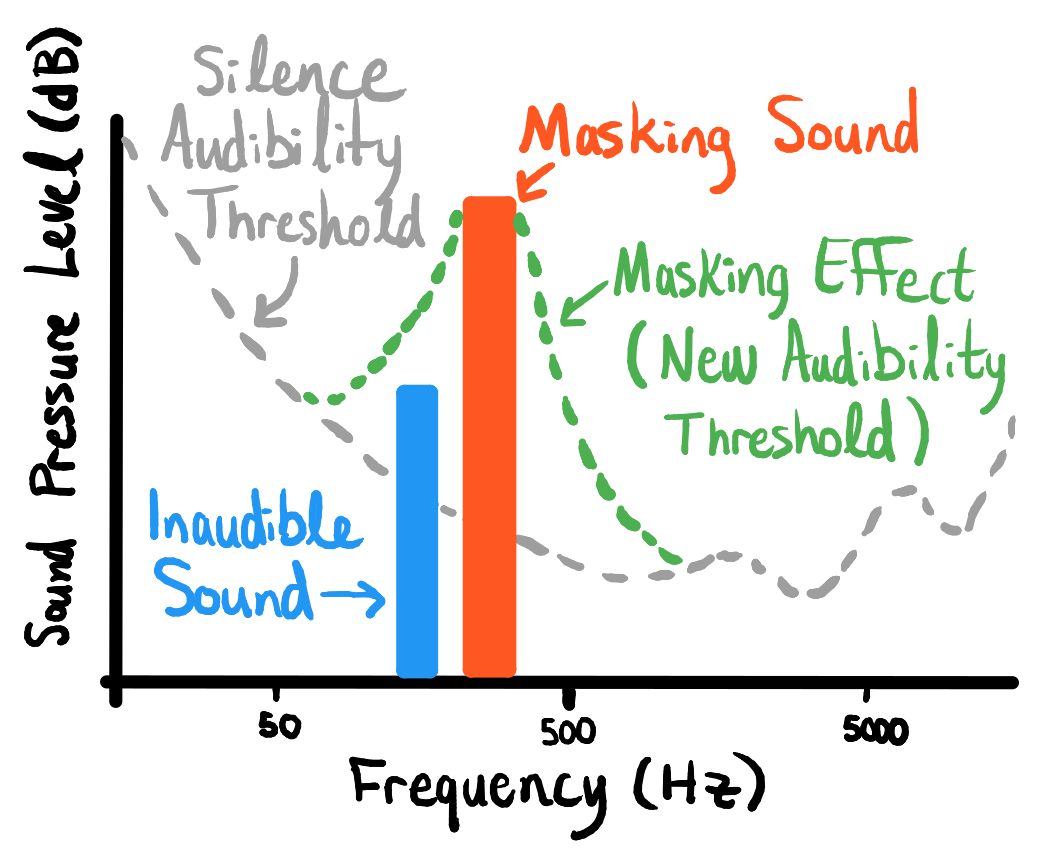
显示较小的音调如何被附近的峰值“掩盖”的图表。
这很直观,但挑战无疑是创建一个机器学习模型,该模型可以定位候选波形部分并自动生成适当但听不见的带有识别信息的音频。然后它必须逆转该过程,同时保持对上述常见声音操作的鲁棒性。
这是他们提供的两个例子。看看你能不能找出哪一个是水印的。将鼠标悬停在此处可在状态栏中查看答案。
我无法分辨其中的区别,甚至非常仔细地检查波形我也无法发现任何明显的异常情况。这些天我不太方便使用频谱分析仪来真正进入那里,但我怀疑那是你可能会看到一些东西的地方。无论如何,如果他们声称表明由 Resemble 生成的数据或多或少不可逆地编码到其中一个片段中,我会说这是成功的。
PerTh 将很快向 Resemble 的所有客户推出,现在需要明确的是,它只能标记和检测公司自己生成的语音。但如果他们这样做了,其他人可能也会这样做——而且这些引擎很可能很快就会与语音生成模型本身密不可分。恶意行为者总能找到解决此类问题的方法,但设置障碍应该有助于遏制部分此类行为。
不过,音频在这方面很特殊,类似的技巧不适用于文本或图像。因此,预计在这些领域中会在恐怖谷中停留一段时间。
“听不见”水印可以识别由Devin Coldewey最初发表在TechCrunch上的 AI 生成的声音
原文: https://techcrunch.com/2023/02/01/inaudible-watermark-could-identify-ai-generated-voices/