我在 3 月份发布了shot-scraper ,作为一种工具,用于使文档中的屏幕截图保持最新。
Web 应用程序文档中的功能屏幕截图很容易随着软件本身的最新设计而过时。
shot-scraper是一个旨在解决这个问题的命令行工具。
您可以使用它来获取一次性屏幕截图,如下所示:
shot-scraper https://latest.datasette.io/ --height 800
或者您可以在单个 YAML 文件中定义多个屏幕截图 – 我们称之为shots.yml :
-网址: https ://latest.datasette.io/ 身高: 800 输出: index.png -网址: https ://latest.datasette.io/fixtures 身高: 800 输出:数据库.png
像这样一次运行它们:
shot-scraper multi shots.yml
今天早上,我使用shot-scraper将Datasette 文档中的所有现有屏幕截图替换为最新的自动等效屏幕截图。
我决定以此为契机创建一个更详细的教程,介绍如何将shot-scraper用于此类屏幕截图自动化项目。
四个要替换的屏幕截图
Datasette 的文档包括四个我想用自动等效项替换的屏幕截图。
full_text_search.png说明了全文搜索功能:
{kind=link}
advanced_export.png显示 Datasette 的“高级导出”对话框:
binary_data.png仅显示带有二进制下载链接的表的一小部分:
{kind=link}

facets.png演示了针对表格的刻面:
{kind=link}

我将依次浏览每个屏幕截图。
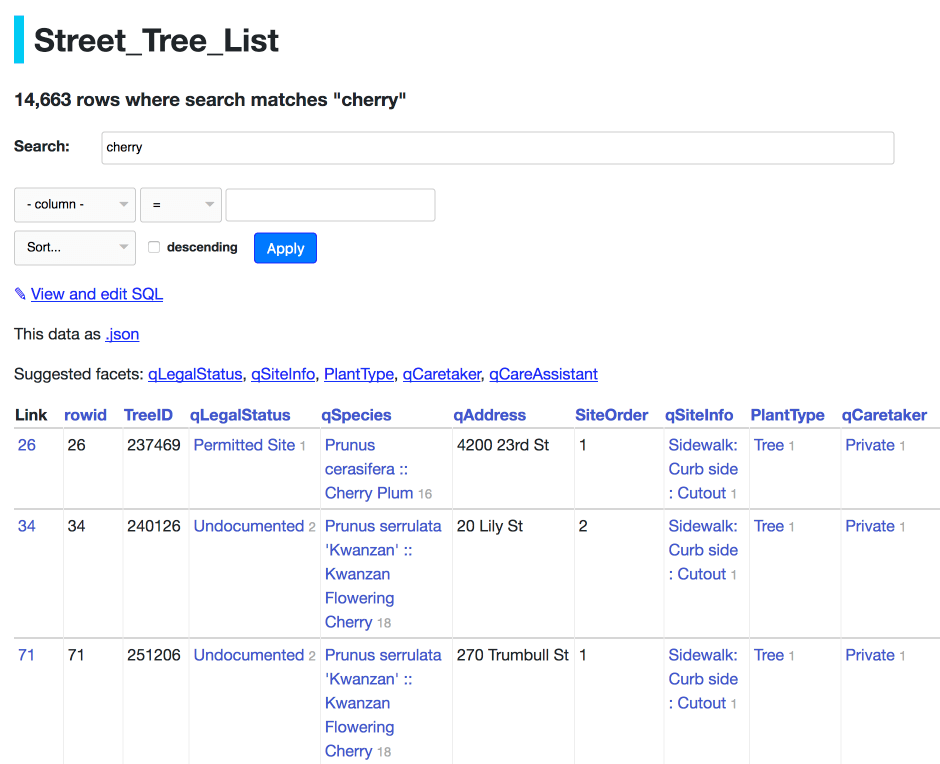
全文搜索.png
我决定为新的屏幕截图使用不同的示例,因为我目前没有针对最新 Datasette 版本运行的该表的实时实例。
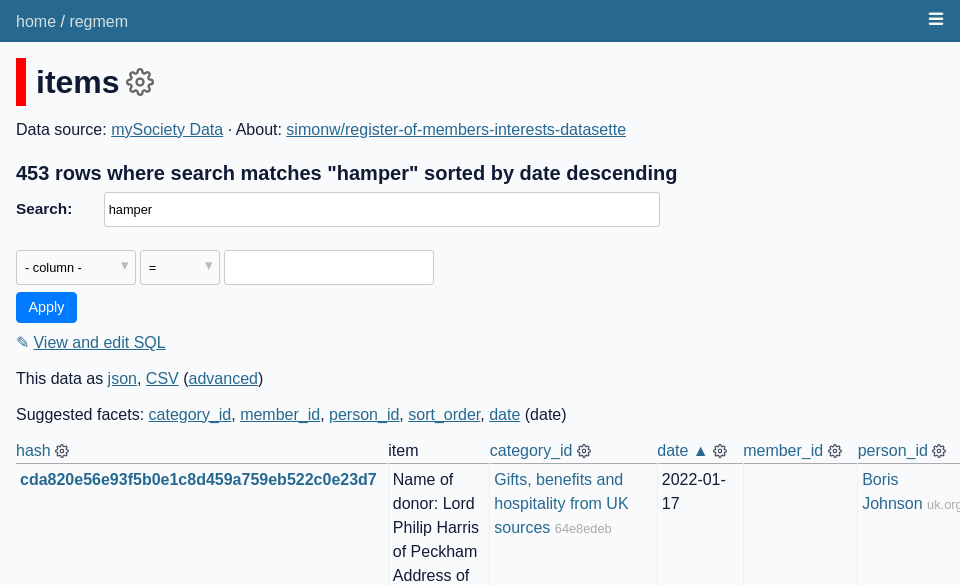
我选择了https://register-of-members-interests.datasettes.com/regmem/items?_search=hamper&_sort_desc=date – 在英国会员利益登记中搜索“hamper”(请参阅探索英国会员登记对 SQL 和数据集感兴趣)。
文档中的现有图像是 960 像素宽,所以我坚持使用它并尝试了几次迭代,直到找到我喜欢的高度。
我安装了 shot-scraper并在我的/tmp目录中运行以下命令:
shot-scraper 'https://register-of-members-interests.datasettes.com/regmem/items?_search=hamper&_sort_desc=date' \ -h 585 \ -w 960
这产生了一个register-of-members-interests-datasettes-com-regmem-items.png文件,当我在预览中打开它时看起来不错。
我在我的shots.yml文件中把它变成了以下 YAML:
-网址: https ://register-of-members-interests.datasettes.com/regmem/items?_search=hamper&_sort_desc=date 身高: 585 宽度: 960 输出: regmem-search.png
针对该文件运行shot-scraper multi shots.yml生成了这个regmem-search.png图像:
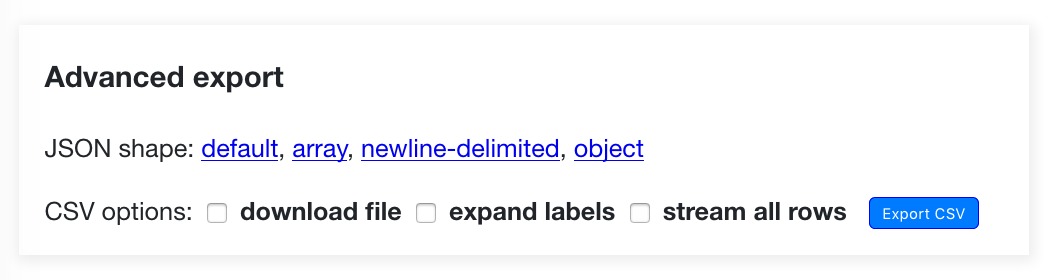
高级导出.png
下一张图片不是整页截图——它只是页面的一小部分。
shot-scraper可以基于一个或多个 CSS 选择器截取部分屏幕截图。给定一个 CSS 选择器,该工具会在该元素周围绘制一个框,并使用它来截取屏幕截图 – 添加可选填充。
这是高级导出框的配方 – 我使用了相同的register-of-members-interests.datasettes.com示例,因为它有足够的行来触发所有要显示的高级选项:
shot-scraper 'https://register-of-members-interests.datasettes.com/regmem/items?_search=hamper' \ -s '#export' \ -p 10
这里的-p 10指定 10px 的填充,需要捕获框上的投影。
这是等效的 YAML:
-网址: https ://register-of-members-interests.datasettes.com/regmem/items?_search=hamper 选择器: “ #export ” 输出:高级导出.png 填充: 10
结果:
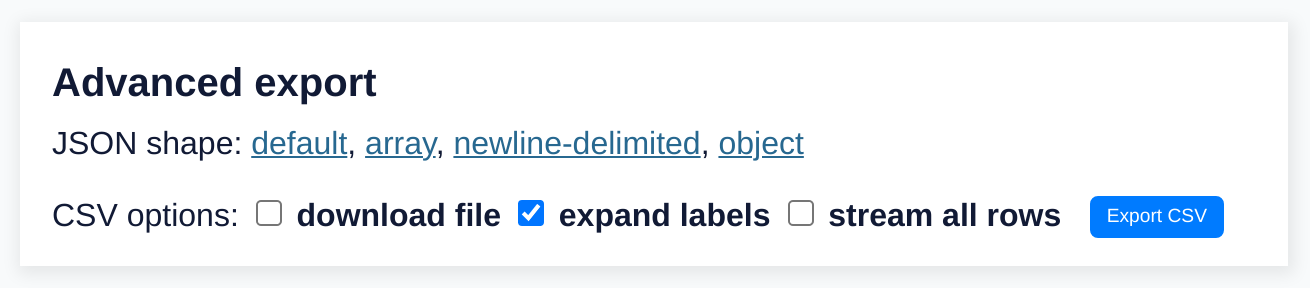
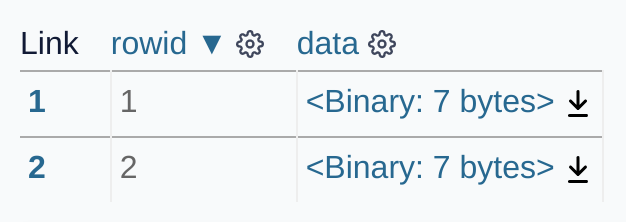
二进制数据.png
此屏幕截图需要不同的技巧。
我想截取这个页面上的表格。
完整的表格如下所示,包含三行:
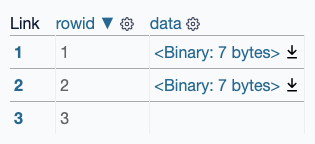
我只希望其中的前两个显示在屏幕截图中。
shot-scraper能够在截屏之前在页面上执行 JavaScript。这可用于首先删除元素。
这是我想出的删除除前两行之外的所有行的 JavaScript(实际上是前三行,因为表头也算作一行):
数组。从( 文件。 querySelectorAll ( 'tr:nth-child(n+3)' ) , 埃尔=>埃尔。父节点。移除孩子( el ) ) ;
我这样做是为了以后如果我在该测试表中添加更多行,代码仍然会删除除前两个之外的所有内容。
CSS 选择器tr:nth-child(n+3)选择不是前三个的所有行(一个标题加两个内容行)。
以下是如何从命令行运行它,然后在页面上的表格被 JavaScript 修改后截取 10 像素的填充屏幕截图:
shot-scraper 'https://latest.datasette.io/fixtures/binary_data' \ -j 'Array.from(document.querySelectorAll("tr:nth-child(n+3)"), el => el.parentNode.removeChild(el));' \ -s table -p 10
我添加到shots.yml的 YAML:
-网址: https ://latest.datasette.io/fixtures/binary_data 选择器:表 javascript : |- 数组.from( document.querySelectorAll('tr:nth-child(n+3)'), el => el.parentNode.removeChild(el) ); 填充: 10 输出:二进制数据.png
结果图像:
刻面.png
我把最复杂的截图留到最后。
对于分面屏幕截图,我想在页面顶部包含“建议的分面”链接、一组活动分面,然后是下表的前三行。
但是…该表有很多列。为了获得更整洁的屏幕截图,我只想在最终镜头中包含一部分列。
这是我最终拍摄的屏幕截图:
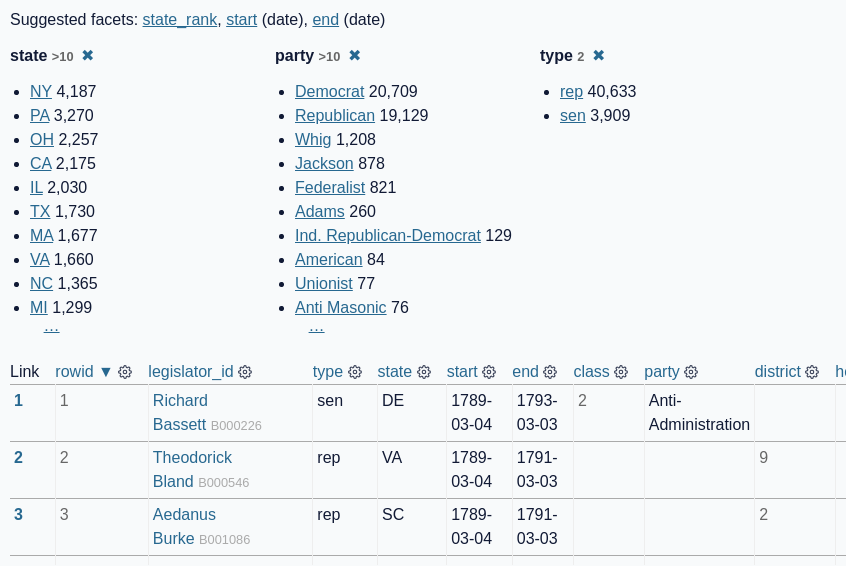
还有 YAML 配方:
-网址: https ://congress-legislators.datasettes.com/legislators/legislator_terms?_facet=type&_facet=party&_facet=state&_facet_size=10 选择器_所有: - .suggested-facets a - tr:not(tr:nth-child(n+4)) td:not(:nth-child(n+11)) 填充: 10 输出: faceting-details.png
我在这里使用的关键技巧是selectors_all列表。
通常的shot-scraper选择器选项会在页面上找到与指定 CSS 选择器匹配的第一个元素并对其进行截图。
--selector-all – 或 YAML 等效的selectors_all – 而是查找与任何指定选择器匹配的每个元素,并绘制一个包含所有选择器的边界框。
我希望该边界框包围页面上表格单元格的子集。我使用这个 CSS 选择器来指示该子集:
tr:not(tr:nth-child(n+4)) td:not(:nth-child(n+11))
如果您要求 GPT-3 解释选择器,以下是 GPT-3 所说的:
解释这个 CSS 选择器:
tr:not(tr:nth-child(n+4)) td:not(:nth-child(n+11))
此选择器选择不是第四行或更大的行中的所有表格单元格,并且不在第 11 列或更大的列中。
(另请参阅此 TIL 。)
使用 GitHub Actions 自动化一切
这是生成所有这四个屏幕截图所需的完整shots.yml YAML:
-网址: https ://register-of-members-interests.datasettes.com/regmem/items?_search=hamper&_sort_desc=date 身高: 585 宽度: 960 输出: regmem-search.png -网址: https ://register-of-members-interests.datasettes.com/regmem/items?_search=hamper 选择器: “ #export ” 输出:高级导出.png 填充: 10 -网址: https ://congress-legislators.datasettes.com/legislators/legislator_terms?_facet=type&_facet=party&_facet=state&_facet_size=10 选择器_所有: - .suggested-facets a - tr:not(tr:nth-child(n+4)) td:not(:nth-child(n+11)) 填充: 10 输出: faceting-details.png -网址: https ://latest.datasette.io/fixtures/binary_data 选择器:表 javascript : |- 数组.from( document.querySelectorAll('tr:nth-child(n+3)'), el => el.parentNode.removeChild(el) ); 填充: 10 输出:二进制数据.png
对这个文件运行shot-scraper shots shots.yml会截取所有四个屏幕截图。
但我希望这是完全自动化的!所以我转向了GitHub Actions 。
不久前,我创建了一个模板存储库,用于设置 GitHub Actions 以使用shot-scraper截取屏幕截图并将它们写回同一个 repo。我在Instantly create a GitHub repository to take screenshot of a web page中写到了这一点。
我之前曾使用该配方创建我的数据集截图存储库 – 使用它自己的shots.yml文件。
所以我将新的 YAML 添加到现有文件中,提交更改,等待一分钟,结果是所有四个图像都存储在该存储库中!
我的datasette-screenshots工作流程实际上与我的默认模板相比有两个关键更改。首先,它对每个屏幕截图进行两次——一次作为视网膜图像,一次作为常规图像:
-名称:拍摄视网膜照片 运行: | shot-scraper 多镜头.yml --retina -名称:拍摄非视网膜照片 运行: | mkdir -p 非视网膜 cd 非视网膜 shot-scraper multi ../shots.yml 光盘..
这为每个屏幕截图提供了高质量图像和更小、更快加载的图像。
其次,它在将 PNG 提交到 repo 之前运行oxipng来优化 PNG:
-名称:优化 PNG 运行: |- oxipng -o 4 -i 0 --strip safe *.png oxipng -o 4 -i 0 --strip safe non-retina/*.png
shot-scraper 文档更详细地描述了这种模式。
有了所有这些,只需对shots.yml文件进行更改就足以生成和存储新的屏幕截图。
链接到图像
最后一个要解决的问题:我想将这些图像包含在我的文档中,这意味着我需要一种链接到它们的方法。
我决定使用 GitHub 直接托管这些内容,通过raw.githubusercontent.com域——它以 Fastly CDN 为前端。
我关心最新的图像,但我也希望不同版本的 Datasette 文档在他们的屏幕截图中反映相应的设计 – 所以我需要一种方法将这些屏幕截图快照到已知版本。
存储库标签是执行此操作的一种方法。
我用0.62标记了datasette-screenshots存储库,因为这是截取屏幕截图的 Datasette 版本。
这给了我以下图片的 URL:
- https://raw.githubusercontent.com/simonw/datasette-screenshots/0.62/advanced-export.png (视网膜)
- https://raw.githubusercontent.com/simonw/datasette-screenshots/0.62/non-retina/regmem-search.png
- https://raw.githubusercontent.com/simonw/datasette-screenshots/0.62/binary-data.png (视网膜)
- https://raw.githubusercontent.com/simonw/datasette-screenshots/0.62/non-retina/faceting-details.png
为了节省页面加载时间,我决定对两个较大的图像使用非视网膜 URL。
这是更新 Datasette 文档以链接到这些新图像的提交(并从存储库中删除了旧图像)。
您可以在这些页面的文档中看到新图像:
- https://docs.datasette.io/en/latest/csv_export.html
- https://docs.datasette.io/en/latest/binary_data.html
- https://docs.datasette.io/en/latest/facets.html
- https://docs.datasette.io/en/latest/full_text_search.html
原文: http://simonwillison.net/2022/Oct/14/automating-screenshots/#atom-everything