Qwen 刚刚于今年 7 月发布了他们的第六个模型(!),称为Qwen3-Coder-30B-A3B-Instruct – 在其chat.qwen.ai界面中列为 Qwen3-Coder-Flash。
它总共有 305 亿个参数,其中 33 亿个参数同时处于活动状态。这意味着它可以在 64GB 的 Mac 上运行,如果量化的话,甚至可以在 32GB 的 Mac 上运行。而且由于活动参数较少,它可以运行得非常快。
这是一种专门针对编码任务进行训练的非思维模型。
这是一个令人兴奋的特性组合:针对编码性能和速度进行了优化,并且足够小,可以在中端开发人员笔记本电脑上运行。
使用 LM Studio 和 Open WebUI 进行尝试
我喜欢使用 Apple 的 MLX 框架运行这样的模型。前几天我直接使用 mlx-lm Python 库运行了 GLM-4.5 Air,但这次我决定尝试LM Studio和Open WebUI的组合。
(LM Studio 内置了一个不错的界面,但我更喜欢 Open WebUI。)
我点击了 LM Studio 的qwen/qwen3-coder-30b页面上的“在 LM Studio 中使用模型”按钮来安装该模型。它提供了许多选项:
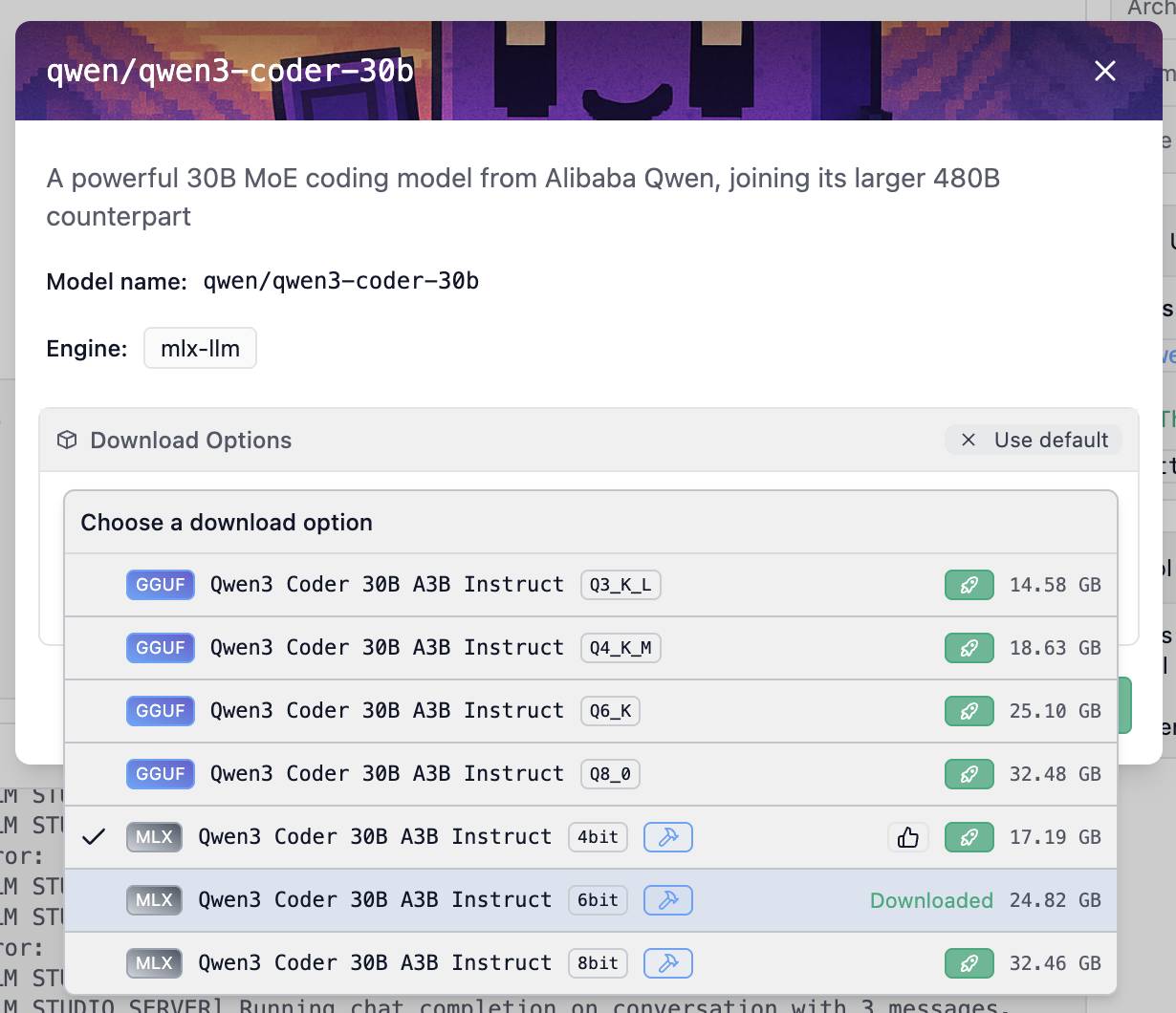
我选择了 6 位 MLX 模型,下载量为 24.82GB。其他选项包括 4 位(17.19GB)和 8 位(32.46GB)。下载大小与运行模型所需的 RAM 大小大致相同——选择 24GB 的模型后,我的 64GB 电脑上还能剩下 40GB 的内存用于其他应用程序。
然后我打开 LM Studio 中的开发人员设置(绿色文件夹图标)并打开“启用 CORS”,以便我可以从单独的 Open WebUI 实例访问它。
现在我切换到 Open WebUI。我使用uv安装并运行了它,如下所示:
uvx --python 3.11 open-webui 服务
然后导航到http://localhost:8080/来访问界面。我打开他们的设置,并配置了一个新的与 LM Studio 的“连接”:
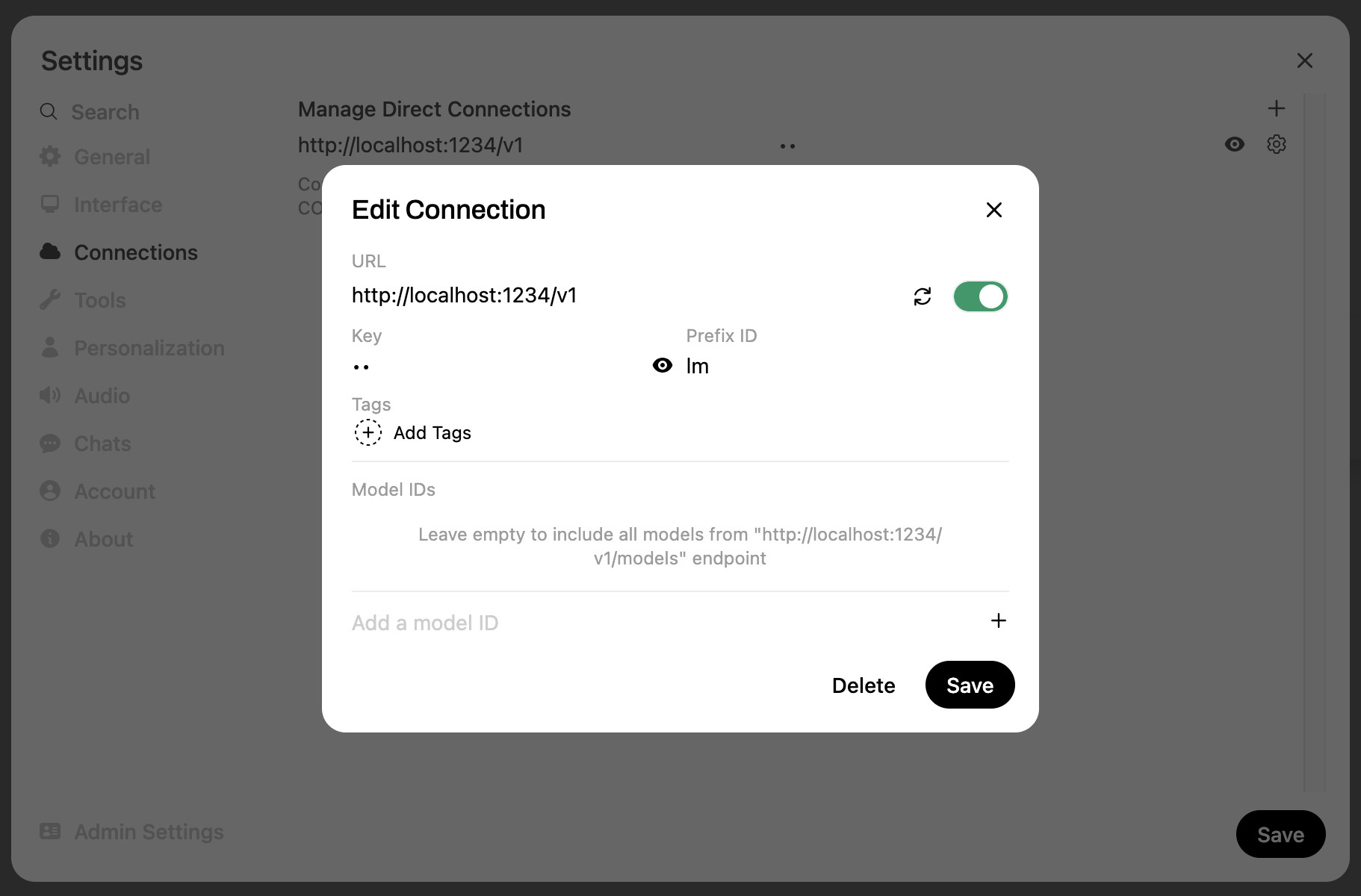
这需要一个基本 URL http://localhost:1234/v1和一个任意你喜欢的键。我还将可选前缀设置为lm ,以防我的 Ollama 安装(Open WebUI 会自动检测)出现重复的模型名称。
完成所有这些后,我可以在 Open WebUI 界面中选择任何 LM Studio 模型并开始运行提示。
Open WebUI 的一个巧妙功能是它包含一个自动预览面板,该面板可以启动包含 SVG 或 HTML 的围栏代码块:
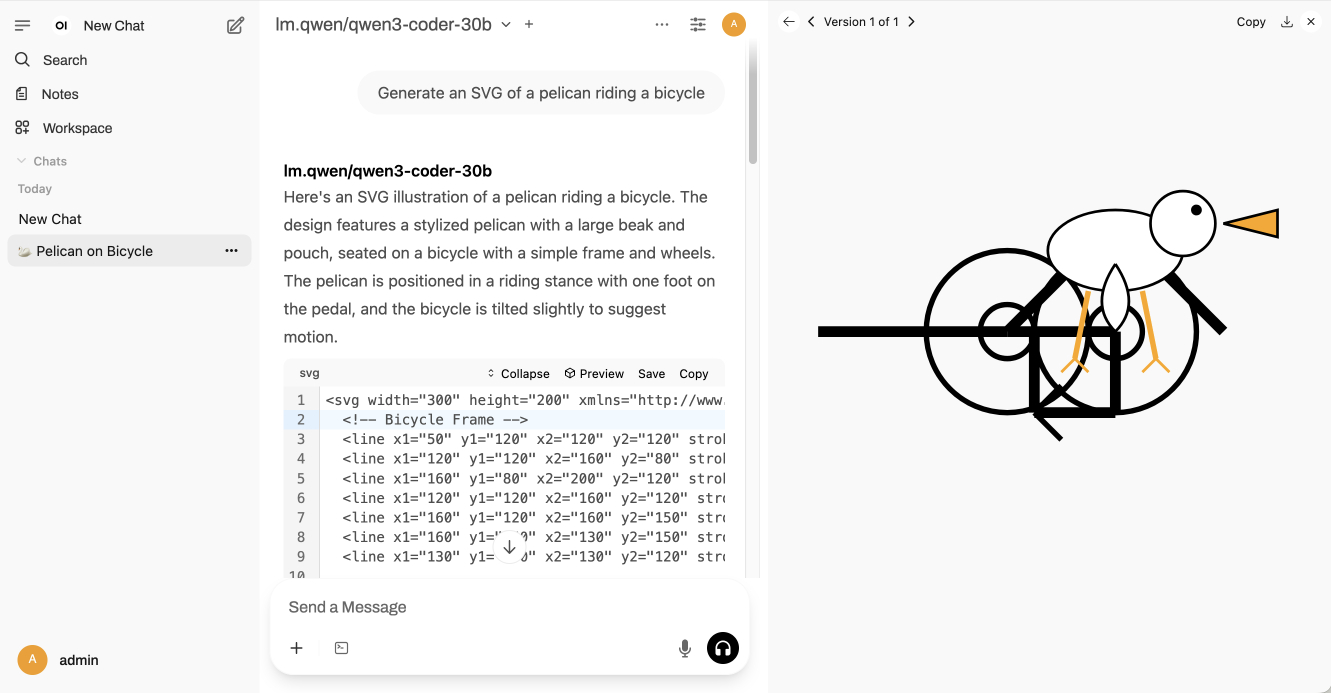
这是“生成鹈鹕骑自行车的 SVG”的导出脚本。它以每秒近 60 个 token 的速度运行!
实现太空侵略者
我也尝试了最近的另一个简单的基准测试提示:
Write an HTML and JavaScript page implementing space invaders
我喜欢这个,因为它是一个非常简短的提示,可以作为一组相当复杂的特征的简写。训练数据中可能包含大量材料来帮助模型实现这一目标,但看看它们能否一次性得出一些有效的结果仍然很有趣。
它给我的第一个版本开箱即用,但有点太难了 – 敌人的子弹移动速度太快,几乎不可能避开它们:
您可以在这里尝试一下。
我尝试了“让敌人的子弹慢一点”这样的后续提示。像 Claude Artifacts 或 Claude Code 这样的系统实现了用于修改文件的工具调用,但我使用的 Open WebUI 系统没有默认的等效工具,这意味着模型必须再次输出完整的文件。
它确实做到了这一点,并且放慢了子弹的速度,但它也做了许多其他更改, 如 diff 所示。我对此并不感到太惊讶——要求一个 25GB 的本地模型仅通过一处更改就输出一个很长的文件,这相当困难。
这是这两个提示的导出记录。
使用 mlx-lm 运行 LM Studio 模型
LM Studio 将其模型存储在~/.cache/lm-studio/models目录中。这意味着您可以使用mlx-lm Python 库通过同一模型运行提示,如下所示:
uv 运行 --isolated --with mlx-lm mlx_lm.generate \ --模型〜 /.cache/lm-studio/models/lmstudio-community/Qwen3-Coder-30B-A3B-Instruct-MLX-6bit \ --prompt “编写一个实现太空侵略者的 HTML 和 JavaScript 页面” \ -m 8192 --top-k 20 --top-p 0.8 --temp 0.7
请注意,这会将模型的副本加载到内存中,因此您可能需要在运行此命令之前退出 LM Studio!
通过我的 LLM 工具访问模型
我的LLM项目提供了一个用于访问大型语言模型的命令行工具和 Python 库。
由于 LM Studio 提供了与 OpenAI 兼容的 API,您可以通过创建或编辑~/Library/Application\ Support/io.datasette.llm/extra-openai-models.yaml文件来配置 LLM以通过该 API 访问模型:
zed〜 /库/应用程序\支持/io.datasette.llm/extra-openai-models.yaml
我添加了以下 YAML 配置:
-型号: qwen3-coder-30b 型号名称: qwen/qwen3-coder-30b api_base : http://localhost:1234/v1 支持工具: true
如果 LM Studio 正在运行,我可以从我的终端执行如下提示:
llm -m qwen3-coder-30b '关于鹈鹕和芝士蛋糕的笑话'
为什么鹈鹕拒绝吃芝士蛋糕?
因为它有喙作为甜点!🥧🦜
(或者如果你愿意的话:因为它害怕吃那么多奶油会得喙病!)
(25GB 显然不足以满足实用的幽默感。)
更有趣的是,我们可以开始运用 Qwen 模型对工具调用的支持:
llm -m qwen3-coder-30b \ -T llm_版本 -T llm_时间 --td \ “显示时间然后显示版本”
这里我们启用了 LLM 的两个默认工具——一个用于显示时间,一个用于查看当前安装的 LLM 版本。– --td标志代表--tools-debug 。
输出如下所示,包括调试输出:
Tool call: llm_time({}) { "utc_time": "2025-07-31 19:20:29 UTC", "utc_time_iso": "2025-07-31T19:20:29.498635+00:00", "local_timezone": "PDT", "local_time": "2025-07-31 12:20:29", "timezone_offset": "UTC-7:00", "is_dst": true } Tool call: llm_version({}) 0.26 The current time is: - Local Time (PDT): 2025-07-31 12:20:29 - UTC Time: 2025-07-31 19:20:29 The installed version of the LLM is 0.26.太棒了!它在一个命令提示符下管理了两个工具调用。Tool call: llm_time({}) { "utc_time": "2025-07-31 19:20:29 UTC", "utc_time_iso": "2025-07-31T19:20:29.498635+00:00", "local_timezone": "PDT", "local_time": "2025-07-31 12:20:29", "timezone_offset": "UTC-7:00", "is_dst": true } Tool call: llm_version({}) 0.26 The current time is: - Local Time (PDT): 2025-07-31 12:20:29 - UTC Time: 2025-07-31 19:20:29 The installed version of the LLM is 0.26.
遗憾的是,我无法让它与我的一些更复杂的插件(例如llm-tools-sqlite)一起工作。我正在尝试弄清楚这是模型、LM Studio 层还是我自己针对 OpenAI 兼容端点运行工具提示的代码中的错误。
Qwen月
七月绝对是 Qwen 的月份。他们本月发布的机型非常出色,甚至在我自己 25GB 或更少内存的笔记本电脑上运行的机型中,也包含了一些极其实用的功能。
如果您正在寻找一个可以在本地运行的合格编码模型,那么 Qwen3-Coder-30B-A3B 是一个非常可靠的选择。
标签:人工智能、生成人工智能、法学硕士、人工智能辅助编程、法学硕士、紫外线、 qwen 、鹈鹕骑自行车、法学硕士发布、 lm-studio 、太空侵略者
原文: https://simonwillison.net/2025/Jul/31/qwen3-coder-flash/#atom-everything