阿波罗全球管理公司的“首席经济学家”托尔斯滕·斯洛克博士发布了这张有趣的图表,该图表似乎表明大型公司(员工人数超过 250 人)的人工智能采用率正在放缓:
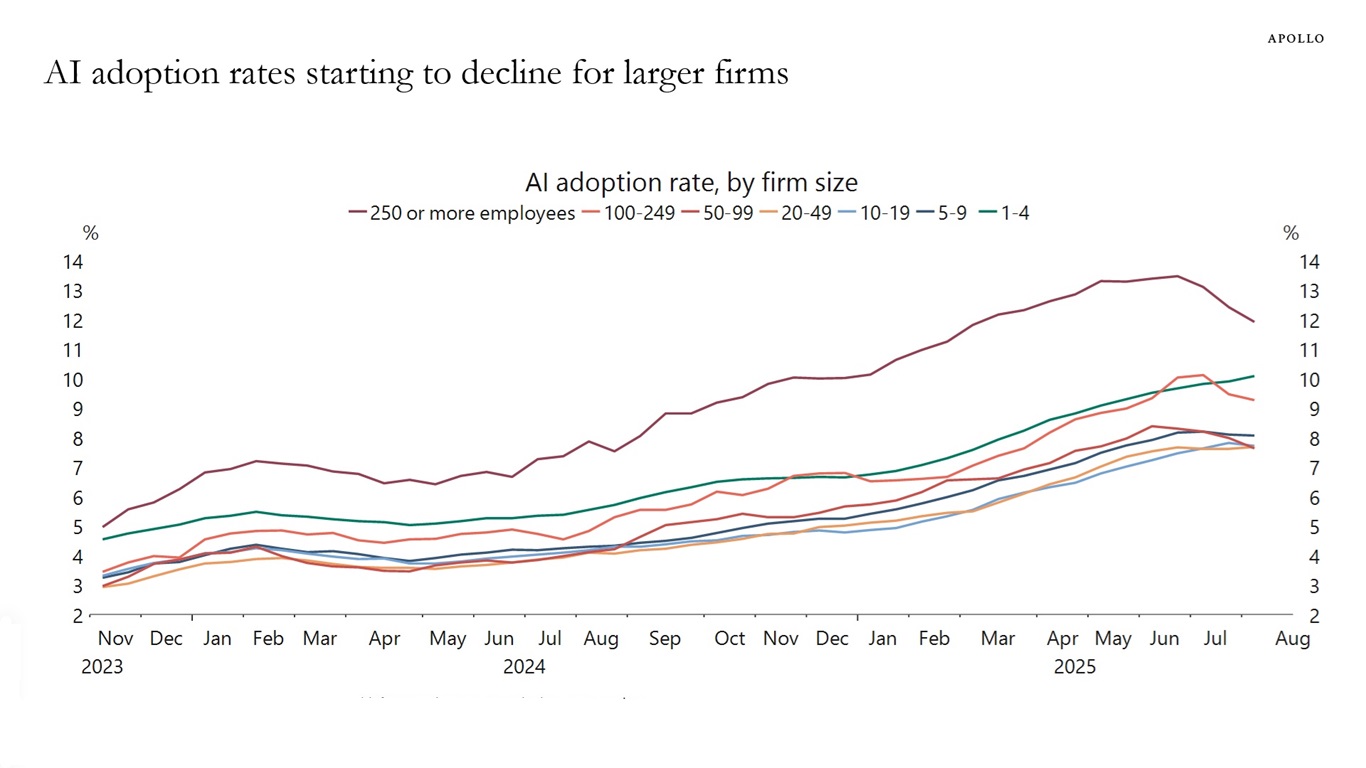
以下是图表的完整描述:
美国人口普查局每两周对120万家企业进行一次调查,其中一个问题是企业在过去两周内是否使用过机器学习、自然语言处理、虚拟代理或语音识别等人工智能工具来帮助生产商品或提供服务。近期按企业规模划分的数据显示,员工人数超过250人的公司对人工智能的采用率一直在下降,见下图。
(看到该图表时,我的第一个想法是,我希望它代表了Gartner 炒作周期中膨胀预期的顶峰,从而导致幻灭的低谷,因为这意味着我们可能正在到达初始炒作阶段的末期,并走向启蒙之坡。)
使用 GPT-5 搜索查找美国人口普查数据
这是我第一次听说美国人口普查局每两周进行一次有关人工智能的调查!
我决定追踪这些数字,看看自己能不能重新创建这个图表。由于GPT-5 现在的搜索能力非常强,我给它输入了以下提示,看看它的表现如何:
> The US Census Bureau conducts a biweekly survey of 1.2 million firms, and one question is whether a business has used AI tools such as machine learning, natural language processing, virtual agents or voice recognition to help produce goods or services in the past two weeks. Recent data by firm size shows that AI adoption has been declining among companies with more than 250 employees, see chart below.
Find me that original data
我花了 1 分 19 秒才找到我需要的东西:
以下是该系列的美国人口普查局原始资料来源:
- BTOS“员工规模类别”时间序列 (XLSX) ——每两周对“过去两周,这家企业是否在生产商品或服务中使用了人工智能 (AI)?”这一问题回答“是”的企业比例,按企业规模(包括250 名以上员工)细分。覆盖范围: 2023 年 9 月 11 日 → 2025 年 8 月 24 日。( Census.gov ) […]
那个人口普查页面一点也不显眼。幸好 GPT-5 提示了我“就业规模类别”文件,链接如下:
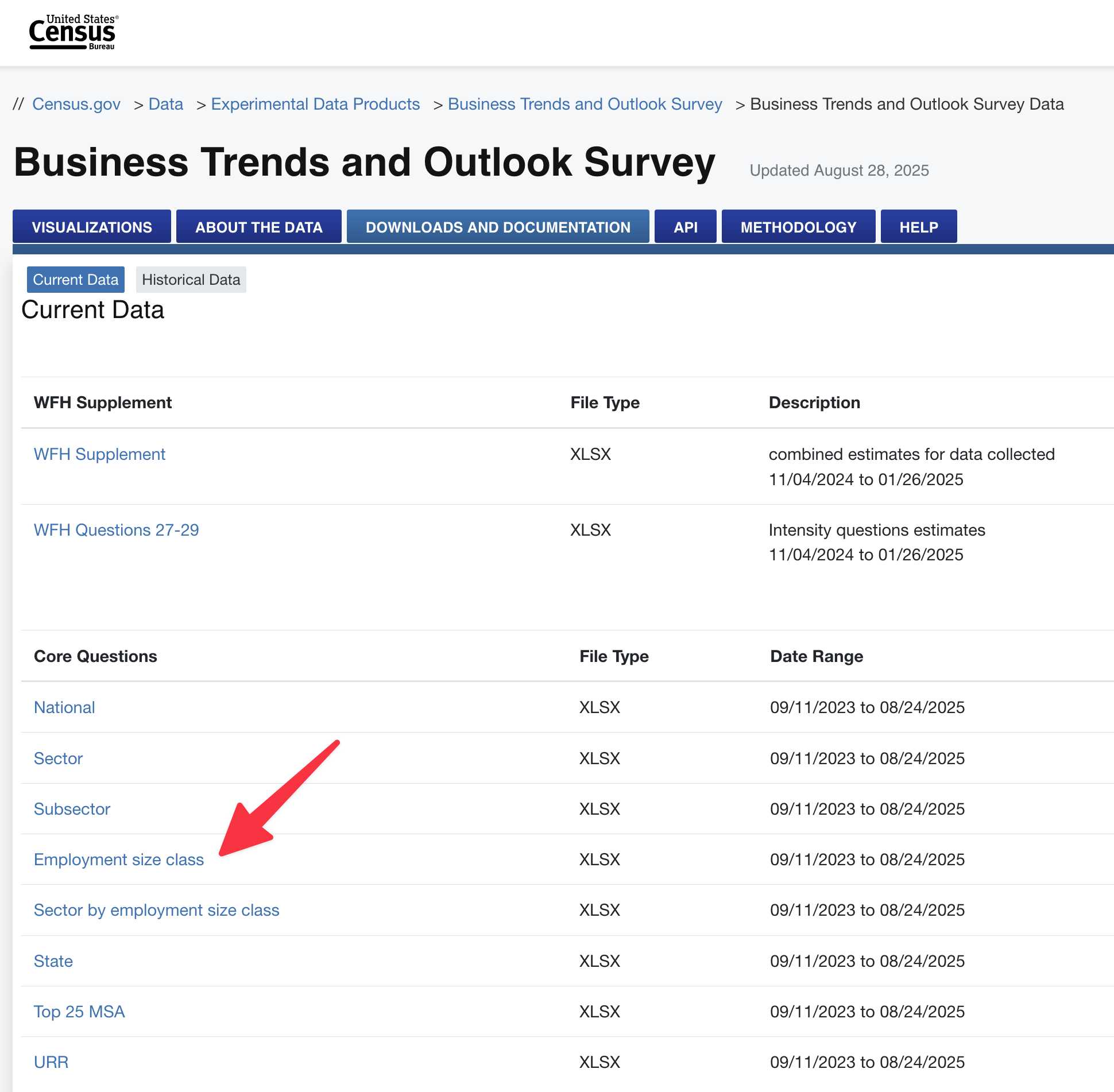
于是我下载了那个文件,确认它确实是一个包含我想要的数据的电子表格(当然,我还有其他各种疑问)。这是我下载的那个文件的374KB XLSX 副本。
使用 GPT-5 代码解释器重新创建图表
那么我现在该怎么处理它呢?我决定看看 GPT-5 是否可以使用在其代码解释器工具中运行的 Python 将电子表格转换回原始图表。
因此,我将 XLSX 文件上传回 ChatGPT,放入了 Apollo 图表的屏幕截图并提示:
Use this data to recreate this chart using python
我认为这是一个相当艰巨的任务,但对法学硕士来说,接受巨大的挑战总是值得的,以便从它的表现中学习。
它在这方面确实很努力。我没有精确计时,但它至少花了7分钟在5个不同的思维模块上进行“推理”,中间穿插了十几次Python分析。它使用pandas和numpy探索上传的电子表格并找到正确的数字,然后尝试了几次使用matplotlib绘图。
据我所知,ChatGPT 中的 GPT-5 现在可以将其创建的图表反馈到其自己的视觉模型中,因为它似乎渲染了一个损坏的(空的)图表,然后继续尝试使其工作。
它在电子表格的最后一个选项卡中找到了一个数据字典,并使用它来构建一个查找表,将字母A到G与实际员工规模桶进行匹配。
该过程结束时,它会输出以下图表:
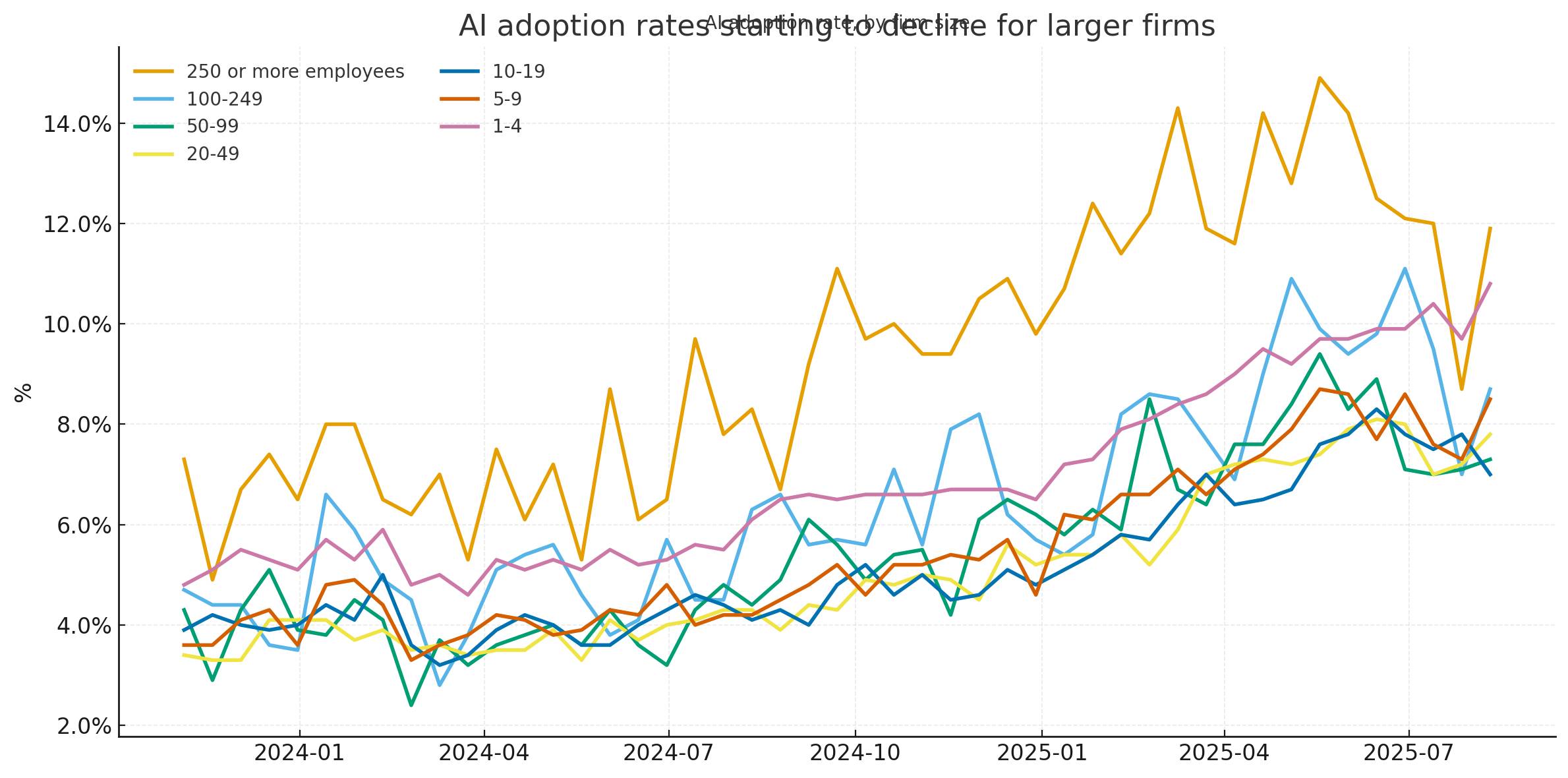
乍一看,我以为它完全正确……但后来我更仔细地将图表与 Apollo 原版图表进行了比较,发现了一些明显的差异。GPT-5 的图表峰值达到 14.5%,而 Apollo 的最高值则更接近 13.5%。GPT-5 的图表更加尖锐——最有趣的是,它在最后一个数据点出现了明显的上升趋势,而 Apollo 的图表此前一直呈下降趋势。
我决定是时候看看实际数据了。我在 Numbers 中打开电子表格,找到 AI 问题列,并手动查看了它们。它们似乎与 GPT-5 图表结果相符——那么为什么与 Apollo 的结果会有如此大的差异呢?
然后我注意到阿波罗图表中的一个关键细节,我已经将其从原始屏幕截图中裁剪掉了!
注:数据为六次调查的移动平均值。
所以我告诉 ChatGPT:
Do the first question, plot it as a six survey rolling average
我问了第一个问题,因为事实证明调查电子表格中有两个相关问题。
- 在过去两周内,该企业是否使用人工智能 (AI) 生产商品或服务?(人工智能示例:机器学习、自然语言处理、虚拟代理、语音识别等)
- 在接下来的六个月内,您认为这家企业会在生产商品或服务中使用人工智能 (AI) 吗?(人工智能示例:机器学习、自然语言处理、虚拟代理、语音识别等)
它又搅动了一会儿,将这段代码添加到脚本中:
# 计算 6 次调查的滚动平均值(每两周一次 → 约 12 周) rolled = wide.rolling ( window = 6 , min_periods = 6 ) .mean ( )
然后弹出这个图表(在我告诉它修复标题中的故障之后):
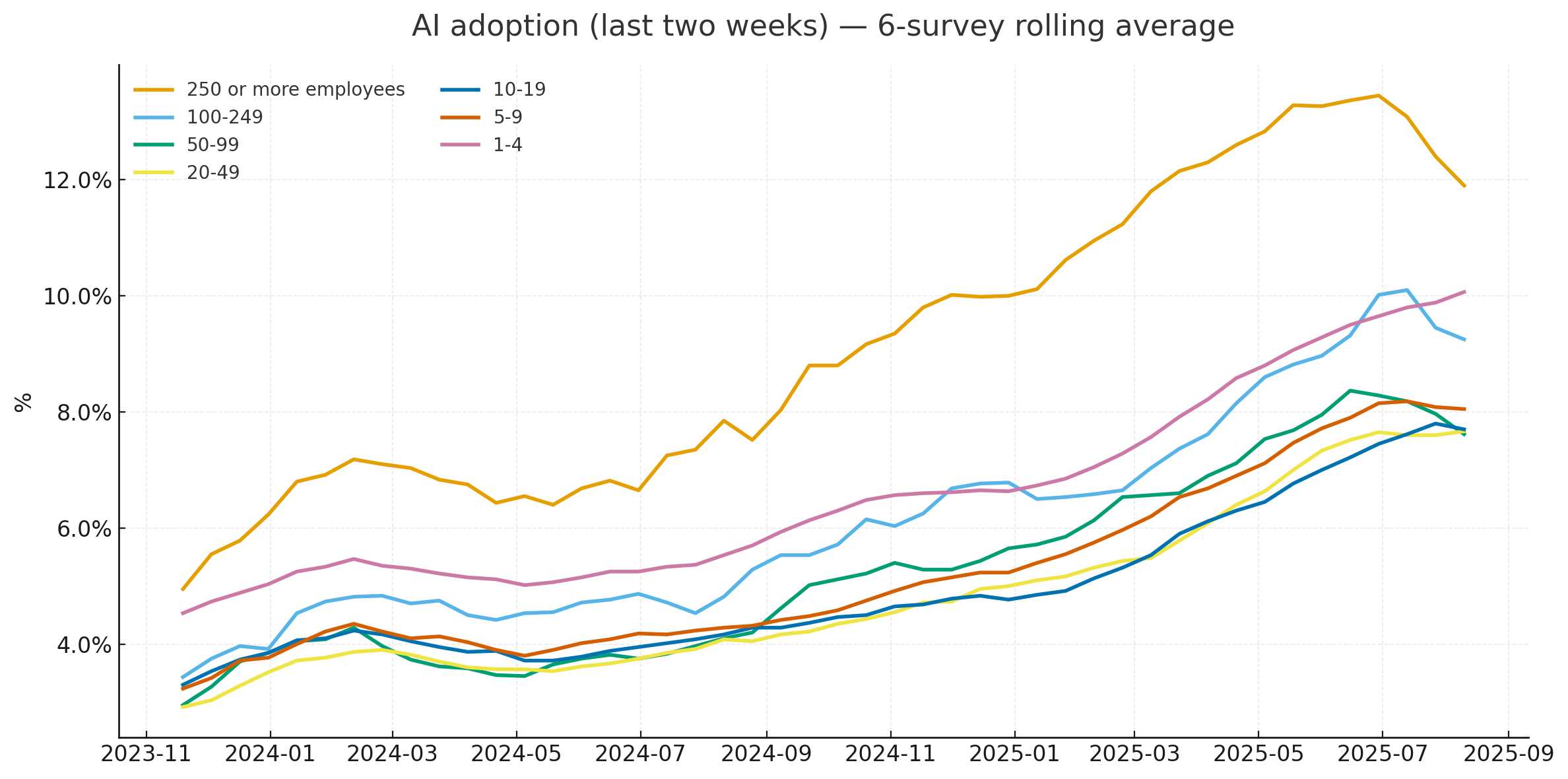
我觉得它成功了!这与 Apollo 原版非常吻合,使用matplotlib和pandas从美国人口普查的相同底层源数据重建。
这是它编写的完整 Python 代码,我认为它非常易读(就 Pandas 代码而言):
将Pandas导入为pd 导入matplotlib.pyplot作为plt 从matplotlib.ticker导入PercentFormatter path = “/mnt/data/Employment Size Class.xlsx” resp = pd.read_excel (路径, sheet_name = “响应估计” ) dates = pd.read_excel ( path , sheet_name = "收集和参考日期" ) is_current = resp [ "Question" ]. astype ( str ) .str.strip () . str.startswith ( "过去两周内" ) ai_yes = resp [ is_current & resp [ "Answer" ]. astype ( str ). str.strip (). str.lower (). eq ( "yes" ) ] . copy ( ) code_to_bucket = { “A” : “1-4” , “B” : “5-9” , “C” : “10-19” , “D” : “20-49” , “E” : “50-99” , “F” : “100-249” , “G” : “250 名或更多员工” } ai_yes [ "Bucket" ] = ai_yes [ "Empsize" ] .map ( code_to_bucket ) period_cols = [ c for c in ai_yes.columns if str ( c ) .isdigit () and len ( str ( c )) == 6 ] long = ai_yes.melt ( id_vars = [ "Bucket" ], value_vars = period_cols , var_name = "Smpdt" , value_name = "value" ) 日期[ “Smpdt” ] =日期[ “Smpdt” ]. astype ( str ) 长整型[ “Smpdt” ] =长整型[ “Smpdt” ]. astype ( str ) 合并= long .merge (日期[[ "Smpdt" , "Ref End" ]], on = "Smpdt" , how = "left" ) 合并[ “日期” ] = pd.to_datetime (合并[ “引用结束” ],错误= “强制” ) 合并[ “value” ] = pd.to_numeric ( long [ “value” ]. astype ( str ) .str.replace ( “%” , “” , regex = False ) .str.strip ( ), errors = “coerce” ) order = [ "250 名或更多员工" , "100-249" , "50-99" , "20-49" , "10-19" , "5-9" , "1-4" ] wide = merged.pivot_table ( index = "日期" , columns = "存储桶" , values = "值" , aggfunc = "平均值" ) .sort_index () wide = wide [[ c for c in order if c in wide . columns ]] rolled = wide.rolling ( window = 6 , min_periods = 6 ) .mean ( ) 开始,结束= pd .时间戳( "2023-11-01" ), pd .时间戳( "2025-08-31" ) rolled_win = rolled.loc [ ( rolled.index > = start ) & ( rolled.index <= end )] 图, ax = plt.subplots (图大小= ( 12,6 )) 按顺序排列: 如果col在rolled_win . columns 中: ax.plot (rolled_win.index , rolled_win [ col ], label = col , linewidth = 2 ) ax.set_title ("AI 采用率(过去两周)— 6 次调查滚动平均值" , pad = 16 ) ax.yaxis.set_major_formatter (PercentFormatter ( 100 ) ) ax.set_ylabel ( “%” ) ax.set_xlabel ( "" ) ax.grid ( True , alpha = 0.25 , linestyle = "--" ) ax.legend ( title = None , loc = "左上" , ncols = 2 , frameon = False ) plt.tight_layout ( ) png_path = “/mnt/data/ai_adoption_rolling6_by_firm_size.png” svg_path = “/mnt/data/ai_adoption_rolling6_by_firm_size.svg” plt 。 savefig ( png_path , dpi = 200 , bbox_inches = “紧” ) plt.savefig ( svg_path , bbox_inches = "tight" )
我喜欢它无需我要求就能生成图表的SVG 版本。
{kind=link}
您可以访问ChatGPT 记录来查看其所做的一切的完整详细信息。
使用 Pyodide 在客户端渲染该图表
我还有一个挑战要尝试。我可以使用可以同时执行 Pandas 和 Matplotlib 的Pyodide在浏览器中完整渲染同一张图表吗?
我启动了一个新的 ChatGPT GPT-5 会话并提示:
Build a canvas that loads Pyodide and uses it to render an example bar chart with pandas and matplotlib and then displays that on the page
我的目标很简单,看看能否获得图表渲染的概念验证,最好使用 ChatGPT 的 Canvas 功能。Canvas 是 OpenAI 版本的 Claude Artifacts,它允许模型直接在 ChatGPT 界面中编写并执行 HTML 和 JavaScript。
成功了!以下是脚本以及它为我构建的内容,已导出到我的tools.simonwillison.net GitHub Pages 网站(源代码在此)。
我现在已经证明我可以直接在浏览器中渲染这些 Python 图表。下一步:重新创建 Apollo 图表。
我知道它需要一种方法来加载启用了 CORS 的电子表格。我将副本上传到我的/static/cors-allow/2025/...目录(在 S3 中配置为提供 CORS 标头),粘贴之前完成的绘图代码,并告诉 ChatGPT:
Now update it to have less explanatory text and a less exciting design (black on white is fine) and run the equivalent of this:(…粘贴之前的 Python 代码…)
Load the XLSX sheet from https://static.simonwillison.net/static/cors-allow/2025/Employment-Size-Class-Sep-2025.xlsx
它并没有完全发挥作用——我收到了有关openpyxl的错误,我手动研究了修复方法并提示:
Use await micropip.install("openpyxl") to install openpyxl - instead of using loadPackage
我不得不粘贴另一条错误消息:
zipfile.BadZipFile: File is not a zip file
然后是关于SyntaxError: unmatched ')'和TypeError: Legend.__init__() got an unexpected keyword argument 'ncols' – 复制和粘贴错误消息仍然是 vibe-coding 循环中令人沮丧但必要的部分。
……但修复之后,最终的代码就成功了!访问tools.simonwillison.net/ai-adoption查看最终结果:
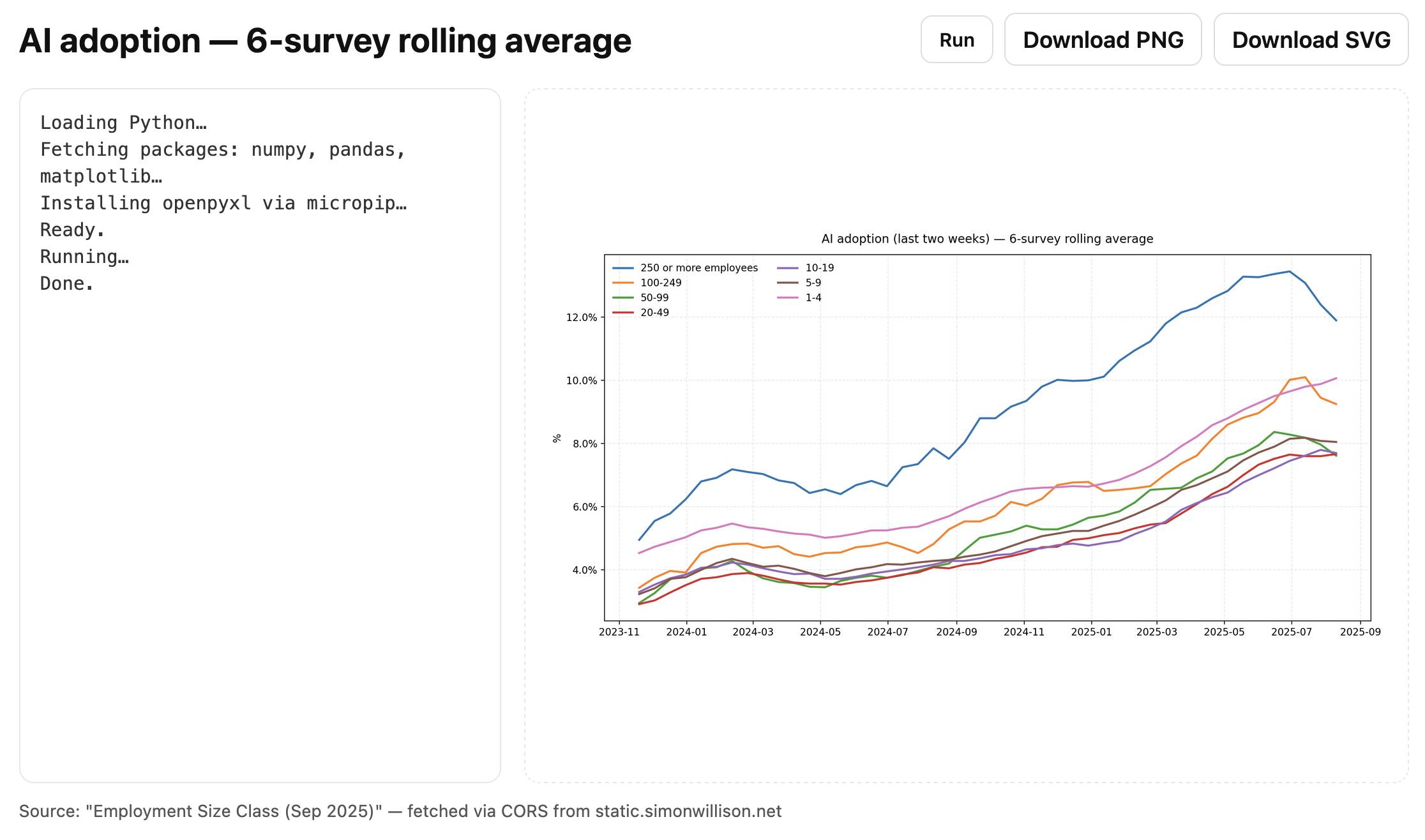
这是该页面的代码,总共170 行HTML、CSS、JavaScript 和 Python。
我从中学到的东西
这是又一次由好奇心引发的调查,并最终转化为一整套有用的经验教训。
- GPT-5 非常擅长追踪美国人口普查数据,无论他们的网站有多难理解,如果你不经常使用他们的数据
- 它可以使用代码解释器、Pandas 和 matplotlib 将数据 + 图表截图转换为该图表的重新创建版本
- 通过 Pyodide 在浏览器中运行 Python + matplotlib 非常简单,只需要几十行代码
- 使用
pyfetch和openpyxl将 XLSX 表提取到 Pyodide 中只需一个小小的额外步骤:导入micropip 等待micropip.install ( “openpyxl” ) 从pyodide.http导入pyfetch resp_fetch =等待pyfetch ( URL ) wb_bytes =等待resp_fetch.bytes ( ) xf = pd.ExcelFile ( io.BytesIO ( wb_bytes ), engine = ' openpyxl' )
我将来肯定会再次使用这些技术。
标签:人口普查、数据新闻、 javascript 、 python 、工具、可视化、人工智能、 pyodide 、 openai 、生成式人工智能、 chatgpt 、 llms 、人工智能辅助编程、代码解释器、 llm推理、 vibe编码、人工智能辅助搜索、 gpt-5
原文: https://simonwillison.net/2025/Sep/9/apollo-ai-adoption/#atom-everything