我一开始让AI包办一切。六个月后,我的代理程序中65%的工作流节点都由非AI代码运行。
第一版完全由系统自主控制:所有任务都分配给一个学习型学习模型(LLM)。LLM 会自信地完成任务,尽管并非总是准确无误。
所以我添加了一些工具来限制LLM可以调用的内容,限制了它的偏差能力。我还添加了一个发现工具来帮助AI找到这些工具。情况有所改善,但还不够。
后来我发现了 Stripe 的Minion 架构。他们的洞见是:确定性代码处理可预测的情况;LLM 处理模糊的情况。
我实现了蓝图,也就是用代码编写的工作流程图。每个蓝图都定义了节点、节点之间的转换、匹配任务的触发条件以及明确的错误处理机制。
extract_domain (code) → attio_find (code) → harmonic_enrich (code) → generate_summary (LLM, 1 turn) → notion_prepend (code)这与技能或提示不同。技能告诉学习管理者(LLM)该做什么。而蓝图则告诉系统何时需要学习管理者参与。extract_domain (code) → attio_find (code) → harmonic_enrich (code) → generate_summary (LLM, 1 turn) → notion_prepend (code)
每个蓝图都是一个有向节点图。节点分为两种类型:确定性节点(代码)和代理节点(LLM)。节点之间的转换可以根据条件进行分支。
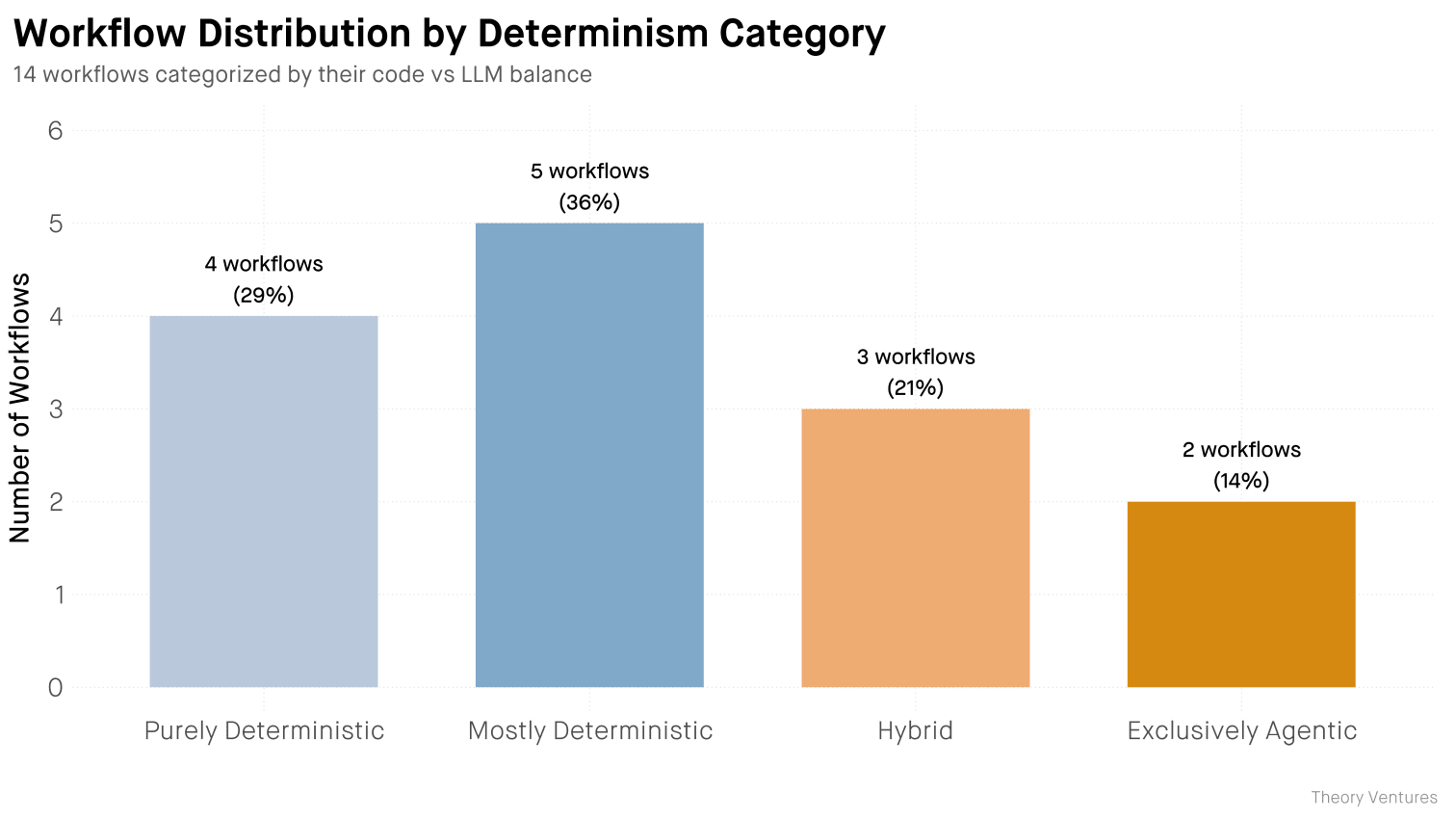
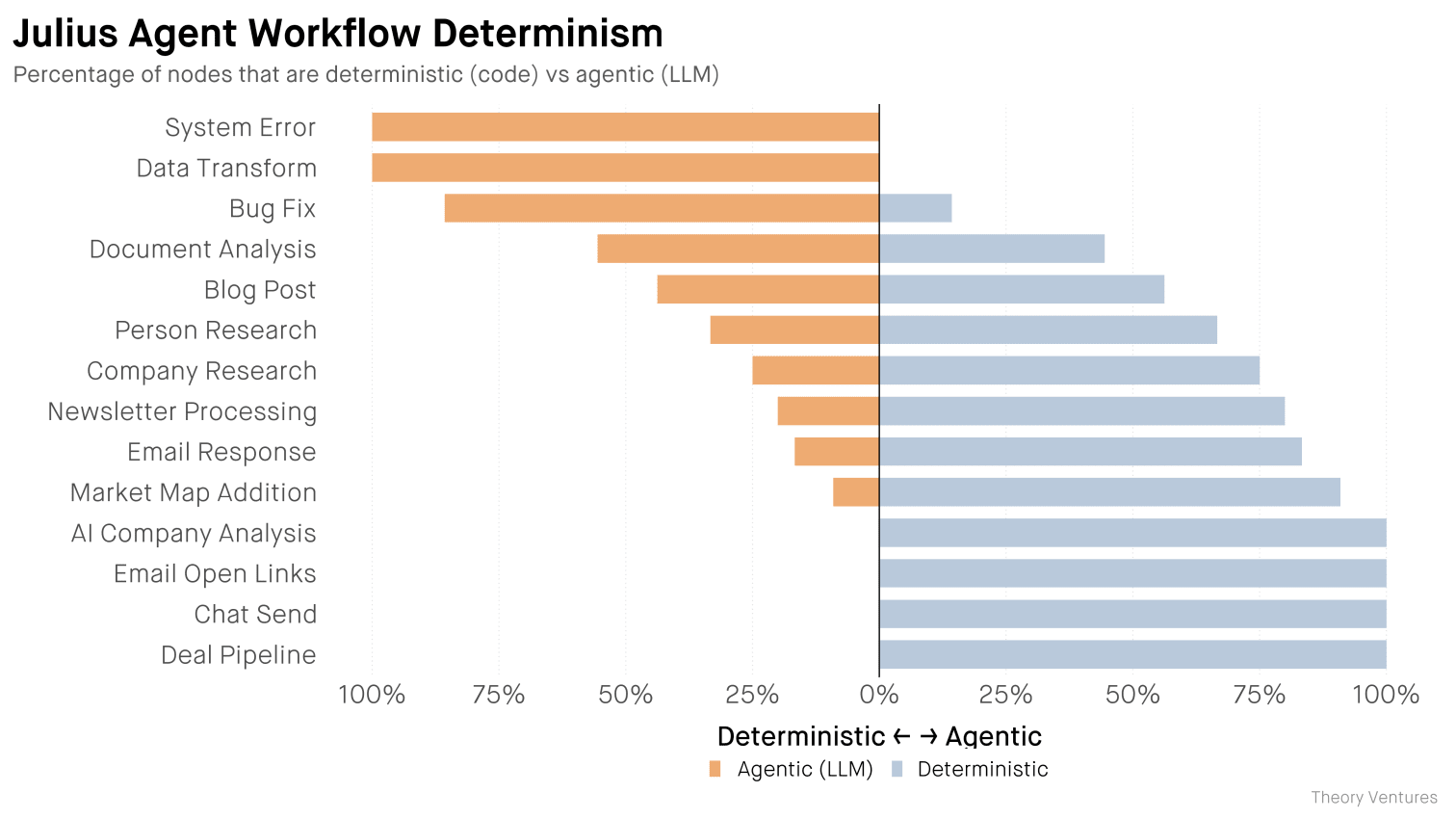
交易流程更新、聊天消息和电子邮件路由占工作流程的 29%,所有这些都无需任何 LLM 通话。
公司调研、新闻稿处理和人员调研仅需使用LLM进行提取和综合,占比36%。整个工作流程67-91%以代码形式运行。LLM仅需处理所需内容:一段待概括的文本、一个待分类的列表,并使用有限的工具在一到三个步骤内完成处理。
博客文章、文档分析和错误修复确实是混合型工作流程,占总工作流程的 21%。多次 LLM 会议会迭代改进,以提升质量。
只有14%的人仍然完全自主。数据转换和错误调查。这些通常是编码任务,而不是评估工作流程中的决策点。LLM需要探索的自由。
人工智能最初包揽一切。现在它负责路由、异常处理、研究、规划和编码。其余部分则无需它也能运行。
人工智能的工作量减少了吗?是的。系统的工作量增加了吗?也是的。
蓝图、工具和技能可能只是临时的支撑。随着每个新型号的发布,功能也会不断扩展。六个月前需要编写确定性代码才能完成的任务,明天可能就不需要了。