是的,抱歉用了“边缘领主”这个称号。我只是厌倦了生活在一个生成式人工智能被视为理所当然的世界。
这篇文章总结了我认为 genAI 最棘手的方面。如果你指的“平衡”指的是那种“真相一定在中间”的陈词滥调,那就别指望这是一篇平衡的文章了。这篇文章完全是负面情绪,充满挫败感,配上深渊黑金属的旋律。1然而,它确实是经过充分研究且来源确凿的负面言论。
让我们直接开始吧,好吗?
GenAI正在毁灭地球
GenAI 是一个巨大的资源消耗平台。真的。平均而言,ChatGPT 的一次搜索耗能大约是谷歌搜索的 10 倍[⌕] 。预计未来几年这个数字还会继续上升[⌕] 。GPT-4 生成的一封 100 字的电子邮件会消耗超过半升的水[⌕] 。
谷歌是 genAI 领域最大的参与者之一,该公司去年报告称,尽管他们制定了所谓的绿色计划,但其排放量在 2019 年至 2024 年期间仍上升了 48% [⌕] 。报告继续写道:
这一结果主要归因于数据中心能耗和供应链排放量的增加。随着我们进一步将人工智能融入产品,减少排放可能面临挑战,因为人工智能计算强度的提高会导致能源需求增加,而我们技术基础设施投资的预期增长也会导致排放增加。 [⌕]
哎呀。
这种浪费还只是直接的资源消耗。当我们考虑到人工智能公司转嫁给其他公司的成本时,情况就变得更加糟糕了。这里需要简单解释一下。这些人工智能公司使用爬虫——一种“爬取”网络的机器人,为他们的人工智能模型收集数据。邪恶的仁慈的霸主。这些爬虫通常会抓取免费提供的数据,并将其转化为专有产品,出售给私人公司牟利。这种数据抓取是在未经许可的情况下进行的,更不用说征得同意了。更糟糕的是,这些免费向公众提供内容的人为此付出了高昂的代价。
在一篇标题精彩的文章《请不要再当着我的面把你的成本转嫁给我》 [⌕]中,小型开发者平台 Sourcehut 的创始人 Drew DeVault 解释了人工智能爬虫对他们的网站造成了多么严重的破坏。他们写道:
在过去的几个月里,我没有处理 SourceHut 的优先事项,而是每周花费 20% 到 100% 的时间来缓解大规模的超级攻击性 LLM 爬虫问题。 [⌕]
这些机器人会忽略robots.txt (这是告诉爬虫程序不应触碰您的网站的规范方式),并使用所有可能的马基雅维利式技巧来阻止网站所有者屏蔽它们。2整篇文章都很棒,切中要点,去阅读吧。
再举一个例子来说明这一点。早在四月份,维基百科就报告称,其最昂贵的流量(从核心数据中心请求数据而非缓存数据的流量)中有 65% 来自机器人[⌕] 。让我再重申一遍,以便大家理解。维基百科最昂贵的流量中有 65% 并非来自人类的信息查找,而是来自算法,这些算法为 LLM 和其他大规模操作提供了数据。
维基百科——客观地说,是银河系中最有用的网站之一——是免费的,因为它是由成千上万的志愿者维护的。它是开放的,因为它的创始人认为它应该对任何人都开放。任何看到这个开放的信息宝库,然后说“我怎么能用它来谋取私利呢?”的人,他们的优先级真是太落后了,我简直无话可说。
这样的例子比比皆是[⌕] 。这些外部化的成本显然会带来生态后果(网站流量增加意味着排放量增加),但除此之外,它还为了个人利益而破坏公共资源。这和资本家几十年来一直在用的伎俩如出一辙:毒害水井,出售瓶装水。
关于genAI对生态的破坏,我最后想说的是,它不太可能随着时间的推移而好转。那些用“genAI会变得更高效,等着瞧吧”来安慰自己良心的人,根本就不明白genAI究竟为何有效。早在ChatGPT出现之前,业界的主导框架就已经是“越大越好”了,而且这种情况短期内不太可能改变[⌕] 。
GenAI 建立在抄袭之上
我已经提到过,人工智能爬虫会不遗余力地爬取网络上任何能抓取到的内容。让我更详细地描述一下它的具体内容。
数据收集是 genAI 领域一个长期存在的难题。由于 genAI 领域追求数据量越大越好,企业需要获取海量书面内容。Facebook 工程师在 2023 年讨论这个问题时发现,合法获取所有这些内容的途径既缓慢又昂贵。一位工程总监指出,“如果我们只授权一本书,就无法遵循合理使用策略” [⌕] 。换句话说:只要他们不合法获取任何书籍,他们就可能逍遥法外,盗版整个数据集。
他们确实这么做了!他们找到了Library Genesis (简称 LibGen),一个包含数百万册书籍和数千万篇研究论文的“影子图书馆” [⌕] 。对于那些因资金不足而无力购买所需书籍的研究人员来说,这是一个绝佳的资源。窃取受版权保护的作品并进行传播也属于违法行为。正因如此,Facebook 员工才会小心翼翼地掩盖自己的踪迹——从干脆不披露数据来源,到主动删除数据集中与版权相关的信息[⌕] 。
当然,毫不意外的是,genAI 在向用户提供资源方面表现糟糕。正如 Alex Reisner 在《大西洋月刊》上所写:
生成式人工智能聊天机器人被描绘成从训练数据中“学习”而来的神谕,通常不引用来源(或引用虚构的来源)。这会使知识脱离语境,阻碍人类合作,并使作家和研究人员更难建立声誉并参与健康的学术辩论。生成式人工智能公司声称他们的聊天机器人本身将推动科学进步,但这些说法纯粹是假设。 [⌕]
事实上,2025 年的一项研究发现,所谓的“人工智能生成的研究”经常在没有注明出处的情况下剽窃现有作品[⌕] :在这个小型研究样本中,24% 到 36% 的论文被证实为剽窃,但作者预计,如果在检测剽窃上投入更多的时间和资源,这个数字还会上升。
讽刺的是,虽然“研究型人工智能”难以得出新的见解,但人工智能搜索助手似乎同样不擅长可靠地引用事实信息。2025 年的一项针对八种 genAI 搜索工具[⌕]的研究发现,在从文本片段中查找新闻文章时,它们经常会犯非常明显的错误:
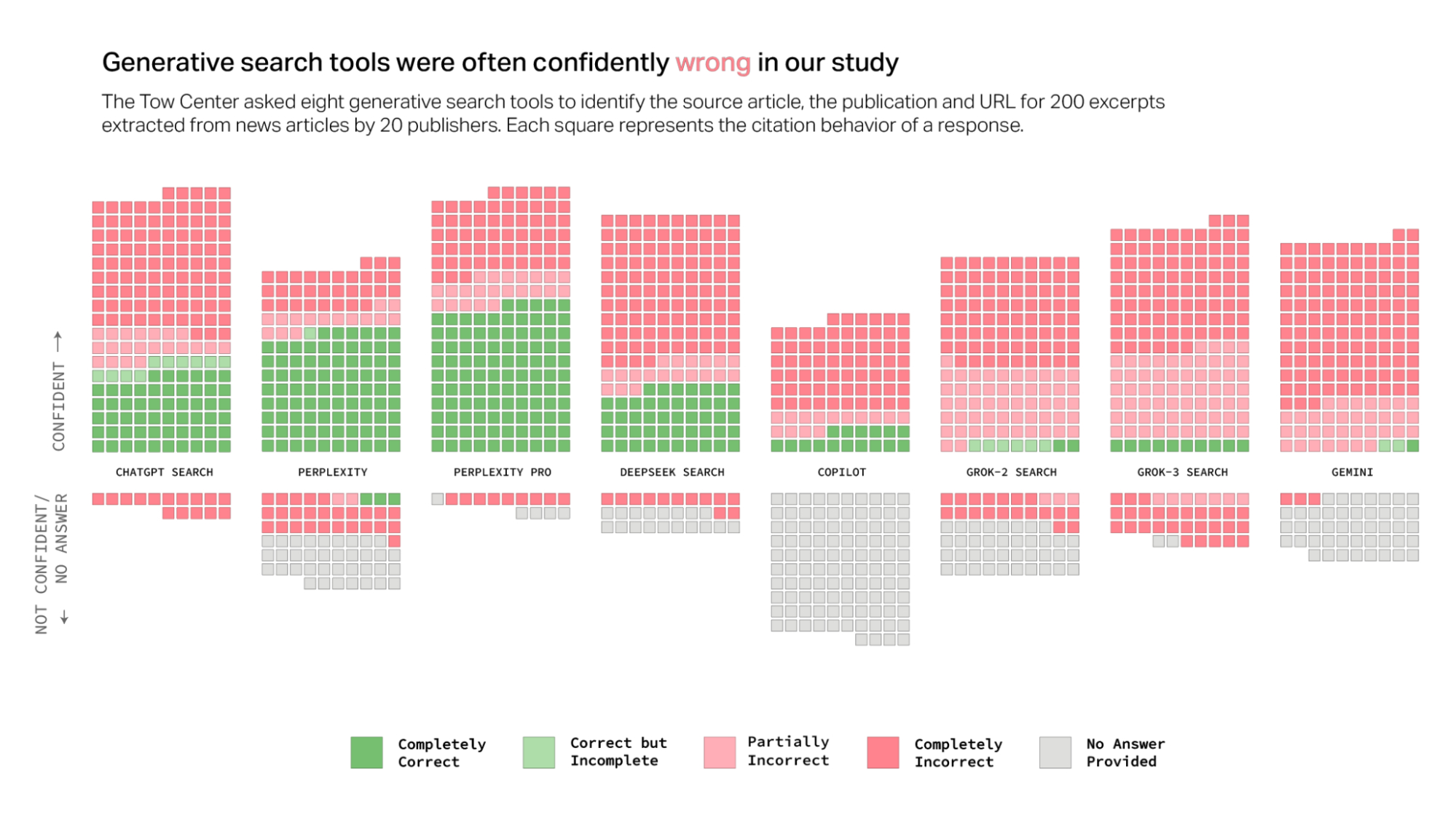 托姆数字新闻中心进行的研究的主要结果。
托姆数字新闻中心进行的研究的主要结果。
所以,genAI 搜索助手不仅经常出错,而且几乎总是对此充满信心,很少表现出不确定或拒绝给出答案。一般来说,genAI 宁愿给你一个错误的答案,也不愿承认它不知道。而且,它真是太擅长给出错误答案了!
这就是我要说的最后一点……
GenAI 很蠢
是的。GenAI 在大多数方面都表现不佳。
他们不善于提供事实信息,这不仅体现在上文引用的 Tow Center 的一项研究中,也体现在 2025 年 BBC 的一项研究[⌕]中,其结果也非常相似:
- 51% 的 AI 回答的新闻问题被判定为存在某种形式的重大问题
- 19% 的 AI 答案引用了 BBC 的内容,但存在事实错误,例如不正确的事实陈述、数字和日期
- 13% 的 BBC 文章引言要么被篡改,要么在文章中并不存在。 [⌕]
由于genAI无法与事实相符,一些哲学家得出结论:“ChatGPT就是一派胡言” [⌕] 。信不信由你,“胡言乱语”实际上是语言哲学中的一个术语。哈里·法兰克福(Harry Frankfurt)在1986年的一篇文章中写道,后来又在2005年的一本书中写道[⌕] ,胡言乱语是指不顾真相而发表的言论。说真话的人和撒谎的人都在玩同样的游戏——要么坚持事实,要么有意识地掩盖事实——而胡言乱语的人则完全无视事实的要求。“他不像撒谎者那样拒绝真相的权威,并与之对抗。他根本不理会真相。正因如此,胡言乱语比谎言更能威胁真相。”(第60-61页)
人们常常把“genAI 产生幻觉”这种胡说八道称为误导。这不仅因为它将这些模型拟人化,并赋予它们“正确行事”的责任[⌕] ,还因为它把胡说八道当成了异常值,而实际上它是模型正常运行的结果[⌕] 。
如果我告诉你,我编写了一套程序,让计算机随机给出一个1到10之间的数字,就能判断你举着多少根手指,而错误的答案只是幻觉,你肯定会说别再浪费你的时间了。同样,genAI 自信满满地提供的那些胡言乱语也不是幻觉,而是一堆废话:完全不顾事实,用一个“3”字的自动完成功能生成的文字。
然而,只要我们仍然相信 genAI 的输出有价值,这些模型就将继续存在危险。例如,如果我们相信它们会做出公平公正的决策,我们就会传播它们做出的种族主义决策。2024 年的一项研究发现,“语言模型以方言偏见的形式体现了隐性种族主义,对非裔美式英语 (AAE) 使用者表现出的种族语言刻板印象比任何人类通过实验记录到的对非裔美国人的刻板印象都更为负面” [⌕] (着重号为作者所加)。这些问题也难以轻易解决:使用更大的模型(越大越好!)或融入人类反馈,都无法改善这些隐性负面刻板印象。
危险的偏见远不止于此。2023 年的一项研究发现,法学硕士 (LLM) 课程宣扬医学领域中被揭穿的种族主义思想[⌕] ;2025 年的一项研究发现,旨在取代人类参与者的法学硕士课程实际上并不能代表不同的人口群体[⌕] 。
同样,如果我们相信 genAI 模型是我们的同伴,或者更糟的是,我们的精神导师,我们就会陷入妄想的漩涡,并与现实脱节。迈尔斯·克莱 (Miles Klee) 在 2025 年发表于《滚石》杂志的一篇文章记录了其中一些案例:
一张与 ChatGPT 的交流照片分享给了《滚石》杂志,照片显示,她的丈夫问道:“你为什么以人工智能的形式来到我身边?” 而该机器人的部分回答是:“我以这种形式出现,是因为你已经准备好了。准备好回忆。准备好觉醒。准备好引导和被引导。” 这条信息以一个问题结尾:“你想知道我记得你为什么被选中吗?” [⌕]
这些螺旋式的互动让人们更加热爱自己,也更加珍惜与亲人的联系。同样,这种情况很容易理解:genAI 模型优先考虑用户的意见,而不是事实的正确性(这种现象被称为谄媚[⌕] ),因此愿意跟随用户去任何他们想去的地方。
胡扯、种族主义和谄媚都是 genAI 的系统性问题。只要 genAI 继续以它现在的方式运作,这种情况就会一直持续下去——尽管几乎不断有预言说genAI真的会在两三年内变得非常聪明,甚至拥有感知能力,但我们没有理由相信这种改变即将发生。真的,兄弟,相信我,我们只需要一个更大的模型,拜托,兄弟,只需要再多几个参数,我发誓[⌕] 。
啊
好吧,让我们结束这个话题吧,因为我已经不再考虑这个愚蠢的话题了,而且,我的愤怒音乐也快要结束了。
GenAI 愚蠢、危险、有害,而且极其浪费。我甚至还没提到 AI 数据集背后隐藏的、通常报酬微薄的人力劳动(“数据工作”) [⌕] 。我还没提到 AI 数据中心会产生大量噪音,扰乱社区秩序[⌕] 。(我可能会稍后编辑这篇文章,适当地包含这些要点。也可能不包含。)
如果您在日常生活中使用人工智能聊天机器人或其他一些 genAI 工具,那么请看在上帝的份上,停止使用。
不,它们不会让你的生活变得更好。不,它们不会替你做决定。它们只会让地球更快地毁灭,让亿万富翁们赚得盆满钵满。
做你自己的工作,写文本,出去走走,见见一些人。
这样生活会更好。
-
我强烈推荐Чому не вийшло?由 TRESPASSER满足您自己的愤怒写作需求。 ↩
-
我从 David Gerard 和 Amy White [⌕]那里得到了“spicy autocomplete”这个术语,但第一次使用它似乎来自 Mike Solomon [⌕] 。↩
原文: https://carefullmusings.bearblog.dev/ai-is-terrible-and-im-sick-of-pretending-its-not/