Dropbox 添加了一些新的 AI 功能。过去几天,这些言论引起了猛烈的批评。 Benj Edwards 在Dropbox 中用新的 AI 功能来吓唬用户,这些功能会在使用时将数据发送到 OpenAI 。
这里的关键问题是,人们担心他们在 Dropbox 上的私人文件会被传递给 OpenAI 用作其模型的训练数据 – 这一说法被 Dropbox 极力否认。
据我所知,Dropbox 构建了一些明智的功能 – 按需总结、通过检索增强生成“与您的数据聊天” – 并且在传达其工作方式方面做得还算不错……但是当涉及到数据隐私和人工智能,“还算不错的工作”,就是不及格的成绩。特别是如果您像 Dropbox 一样拥有尽可能多的人们的私人数据!
有两个细节显得尤为重要。 Dropbox 有一份AI 原则文档,其中包括:
客户信任和数据隐私是我们的基础。未经同意,我们不会使用客户数据来训练人工智能模型。
他们的设置深处还有一个隐藏的复选框,如下所示:
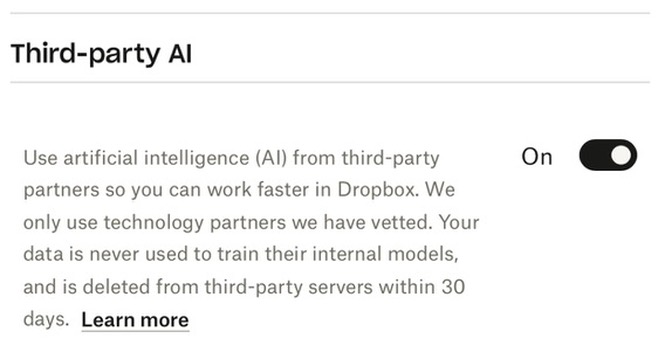
更新:从我发布这篇文章到四个小时后,该链接停止工作。
我用自己的帐户截取了该屏幕截图。它已“打开” – 但我自己从未打开过它。
这是否意味着我被标记为“同意”使用我的数据来训练人工智能模型?
我不这么认为:我认为这是令人困惑的措辞和“同意”一词含义的永恒模糊性的结合,在这个世界上,每个人都同意一切的条款和条件而不阅读它们。
但很多人得出的结论是,这意味着他们的私人数据(他们向 Dropbox 付费来保护这些数据)现在正被流入 OpenAI 培训深渊。
人们不相信 OpenAI
以下是 Dropbox 首选项框中的副本,谈论他们的“第三方合作伙伴” – 在本例中为 OpenAI:
您的数据绝不会用于训练其内部模型,并且会在 30 天内从第三方服务器中删除。
我越来越清楚,当人们被告知数据不会用于训练时,他们根本不相信 OpenAI 。
这里真正发生的事情是更深层次的:人工智能正面临信任危机。
我在 Twitter 上调侃道:
“OpenAI 正在对他们看到的每一条数据进行训练,即使他们说不是”,新的“Facebook 会根据你通过手机麦克风无意中听到的一切内容向你展示广告”
这就是我的意思。
Facebook 不会通过您的麦克风监视您
您是否听说过 Facebook 通过您手机的麦克风监视您并根据您所说的内容向您展示广告?
这个理论已经流传多年。从技术角度来看,应该很容易反驳:
- 手机操作系统不允许应用程序无形地访问麦克风。
- 隐私研究人员可以审核设备与 Facebook 之间的通信,以确认这种情况是否正在发生。
- 大规模运行这样的高质量语音识别是非常昂贵的——几年前,我与一位在苹果公司从事基于服务器的机器学习工作的朋友进行了交谈,他发现整个想法很可笑。
非技术原因更为强烈:
- Facebook 表示他们不会这样做。如果他们撒谎被揭穿,他们的声誉将面临巨大的风险。
- 与许多阴谋论一样,太多人必须“知情”而不揭发。
- Facebook 不需要这样做:有比通过麦克风进行间谍活动更便宜、更有效的方法来针对您投放广告。这些方法多年来一直非常有效。
- Facebook 每年向我们展示数千条广告。其中 99% 的内容与我们大声说出的任何内容都没有丝毫关联。如果你持续掷骰子足够长的时间,最终就会出现巧合。
但事情是这样的:这些争论都不重要。
如果您曾经经历过 Facebook 向您展示您之前大声谈论的某件事的广告,那么您已经驳回了我刚才所说的一切。你亲身经历过的轶事证据推翻了我在这里的所有论点。
以下是 Novemember 2017 的一集回复全部播客,探讨了这个问题: 109 Facebook 正在监视你吗? 。他们的结论是:Facebook 不会通过你的麦克风进行间谍活动。但如果有人已经相信,没有任何论据可以说服他们。
我自己也经历过这种效应——在过去的几年里,我一直试图说服人们不要这样做,作为我个人对这种阴谋论的粘性的迷恋的一部分。
这里的关键问题与 OpenAI 培训问题相同:当这些公司说他们没有做某事时,人们不相信他们。
这里一个有趣的区别是,在 Facebook 的例子中,人们拥有个人证据,使他们相信自己了解正在发生的事情。
对于人工智能,我们的情况几乎完全相反:人工智能模型是奇怪的黑匣子,秘密构建,无法理解训练数据是什么或它如何影响模型。
就像人工智能领域的许多事情一样,人们除了“共鸣”之外什么也没有。而且气氛很糟糕。
这真的很重要
信任真的很重要。公司在处理您的隐私时撒谎是一项非常严重的指控。
如果大公司在如何处理我们的数据方面公然撒谎,并且不承担任何后果,那么这个社会就是一个非常不健康的社会。
政府的一个关键作用是防止这种情况发生。如果 OpenAI 正在使用他们声称不会使用的数据进行训练,或者 Facebook 通过我们手机的麦克风监视我们,那么他们应该被拖到监管机构面前和/或被起诉。
如果我们相信他们这样做不会产生任何后果,并且多年来一直逍遥法外,那么我们对企业不当行为的不容忍也会成为受害者。由于我们错误地相信了阴谋论,我们冒着让公司真正的不当行为逍遥法外的风险。
隐私很重要,而且很容易被误解。人们既高估又低估了公司正在做的事情以及可能性。人工智能技术意味着可能性的范围正在以难以理解的速度变化,即使你对这个领域有深刻的认识,这一事实也无济于事。
如果我们想保护我们的隐私,我们需要了解正在发生的事情。更重要的是,我们需要能够信任公司诚实、清晰地解释他们如何处理我们的数据。
就个人而言,我们可能会失去有用的工具。过去 48 小时内有多少人取消了 Dropbox 帐户?还有多少人关闭了人工智能开关,排除了评估这些功能对他们是否有用的可能性?
我们对于它可以做些什么呢?
大型人工智能实验室可以做一些事情来提供帮助:告诉我们你是如何训练的!
这里的基本问题是关于训练数据:OpenAI 使用什么来训练他们的模型?
答案是:我们不知道!整个过程再不透明了。
鉴于此,当 OpenAI 说“我们不会根据通过 API 提交的数据进行训练”时,人们很难相信他们,这有什么奇怪的吗?
ChatGPT 本身的情况就更混乱了。 OpenAI 表示,他们确实使用 ChatGPT 交互来改进他们的模型 – 甚至是那些来自付费客户的模型,但“致电我们”定价的ChatGPT Enterprise除外。
如果我将私人文档粘贴到 ChatGPT 中以请求摘要,那么在下一次模型更新后,该文档的片段是否会泄露给未来的用户?如果没有更多关于他们如何使用 ChatGPT 来改进模型的详细信息,我无法回答这个问题。
对这些东西如何工作的清晰解释可以大大有助于改善 OpenAI 与其用户乃至整个世界的信任关系。
也许可以借鉴大型平台公司的经验。他们发布有关停电的公开事后事故报告,通过透明地了解到底发生了什么以及他们正在采取的措施来防止类似情况再次发生,从而重新获得客户的信任。 Dan Luu 收集了很多例子。
本地模特的机会
我在有关此问题的对话中看到的一个一致主题是,人们更愿意将数据信任给在自己设备上运行的本地模型,而不是托管在云中的模型。
好消息是,本地模型的质量不断提高,尺寸不断缩小。
昨晚我弄清楚了如何在我的笔记本电脑上运行 Mixtral-8x7b-Instruct – 这是我尝试过的第一个本地模型,它的质量似乎确实与 ChatGPT 3.5 相当。
Microsoft 的Phi-2是一个令人着迷的新模型,因为它只有 27 亿个参数(最有用的本地模型从 70 亿个参数起),但声称与一些较大模型相比具有最先进的性能。看起来他们训练它的花费约为 35,000 美元。
虽然我对本地模型的潜力感到兴奋,但我不想看到我们因隐私问题而失去大型托管模型的功能和便利性,而事实证明这是不正确的。
人工智能和隐私的交叉点是一个关键问题。我们需要能够就此事进行最高质量的对话,并以最大程度的透明度和对实际情况的了解。
这已经很难了,如果我们直接不相信公司告诉我们的任何事情,那就更难了。这些公司需要赢得我们的信任。我们如何帮助他们了解如何做到这一点?
原文: https://simonwillison.net/2023/Dec/14/ai-trust-crisis/#atom-everything