过去两周,一系列新的 AI 模型发布。如果没有一些个人基准,想要跟上这些变化可能非常困难。对我来说,我的个人 AI 功能“ Ask LukeW”就是一个基准,它让我能够快速尝试并将新模型投入生产。
首先……这些公告都是什么?5 月 14 日,OpenAI 发布了 GPT-4.1 系列的三个新模型。5 月 20 日,谷歌在 I/O 开发者大会上更新了 Gemini 2.5 Pro。5 月 22 日,Anthropic 发布了 Claude Opus 4 和 Claude Sonnet 4。显然,高端模型的发布速度在短期内不会放缓。
许多 AI 应用会开发并使用自己的基准来评估新模型。但没有什么比亲自在你非常熟悉的领域或问题空间中尝试一个 AI 模型,从而评估其优缺点更有益的了。
为了更轻松地做到这一点,我在本网站的 Ask LukeW 功能中添加了快速测试新模型的功能。由于 Ask LukeW 已整合了我撰写的数千篇文章和数百场演讲,因此它对我来说是一种非常有效的查看哪些方面发生了变化的方法。本质上,我知道什么是好的,因为我知道答案应该是什么。
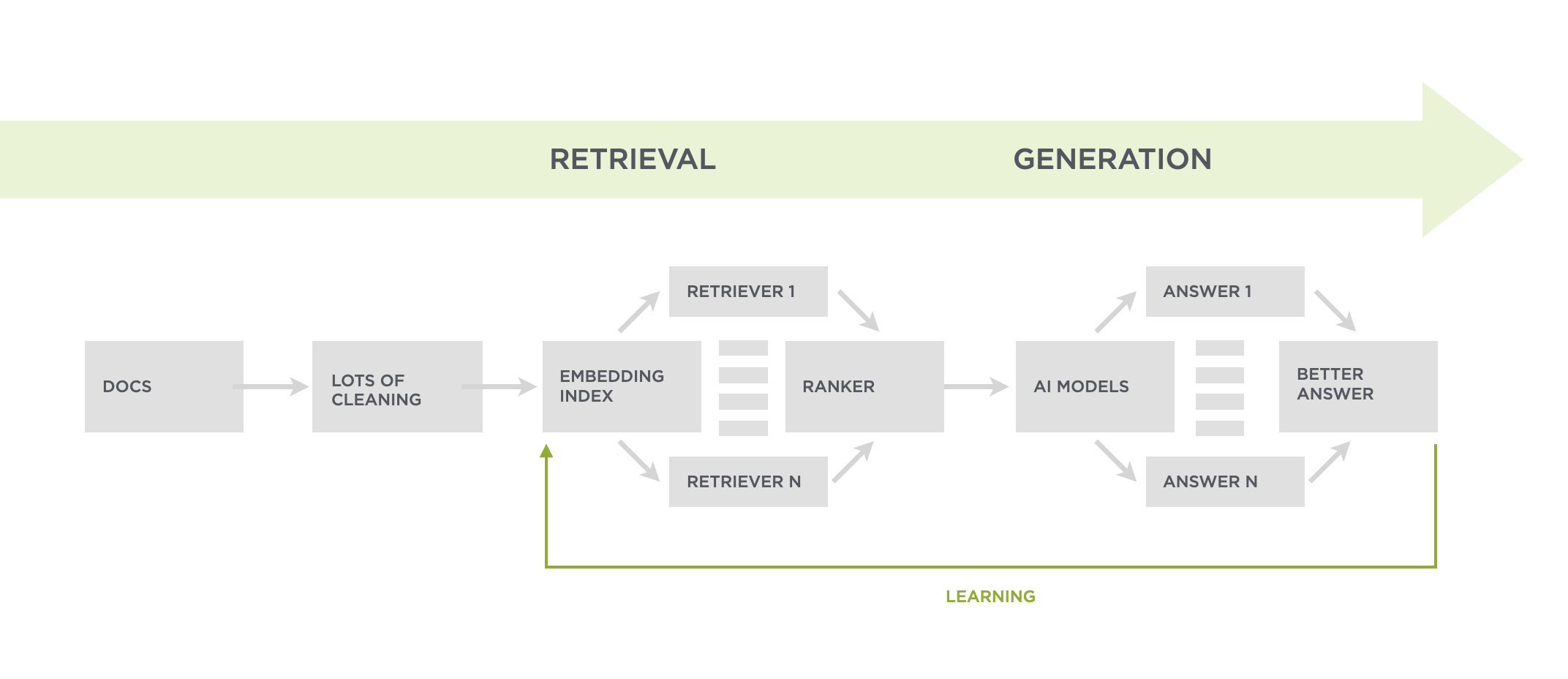
Ask LukeW 系统会在请求大型语言模型 (LLM) 生成用户问题的答案之前检索尽可能多的相关内容(如系统图所示)。因此,当数据进入流程的生成部分时,LLM 可以获取大量需要理解的内容。

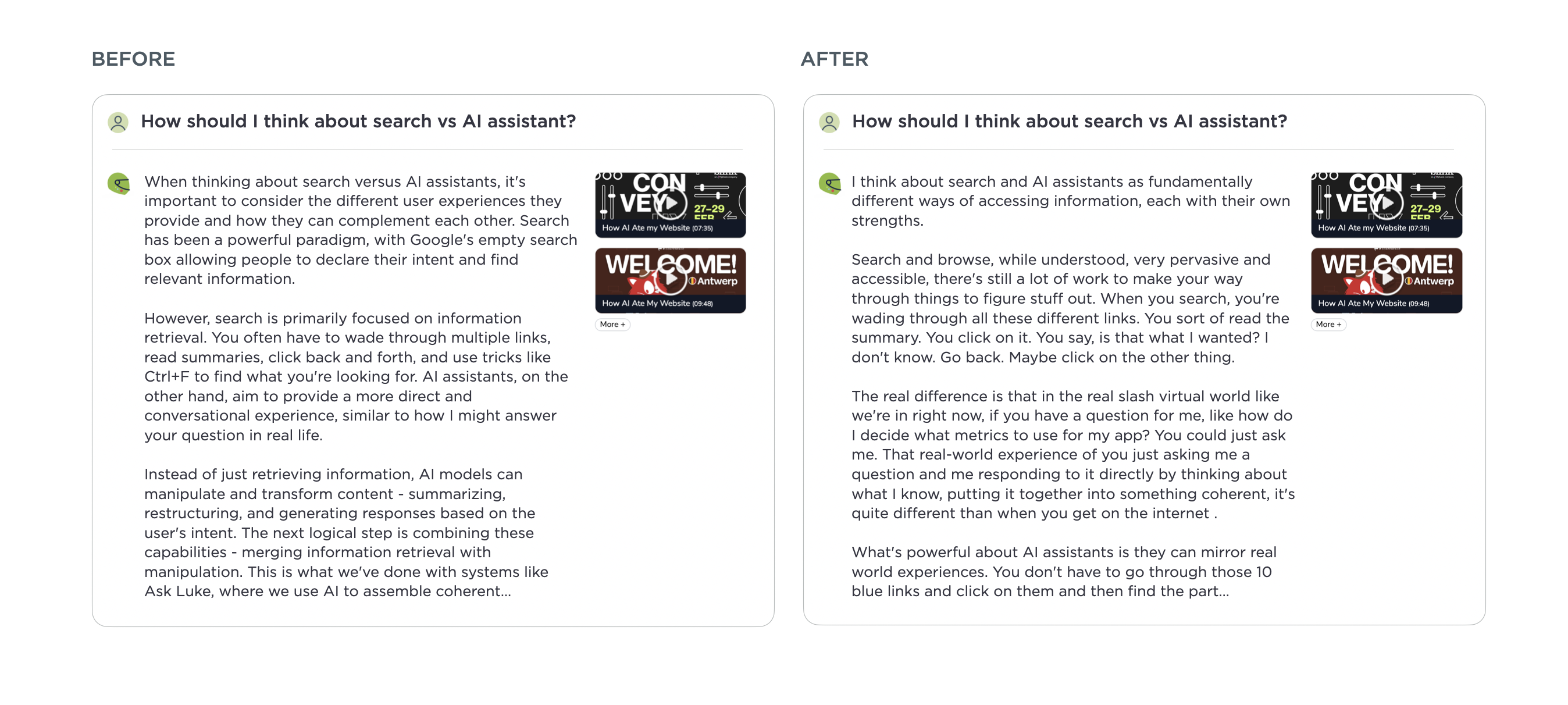
以前,由于前沿模型倾向于尽可能多地包含信息,这导致了许多“厨房水槽”式的要点式答案。这类回复最终会用很多词,但并没有明确切入要点。经过一些测试,我发现 Anthropic 的Claude Opus 4在整理回复方面做得更好,让人感觉它们理解了问题的本质。你可以在这篇文章中看到前后示例的差异。对于需要综合大量内容的问题,回复感觉更加连贯和简洁。
值得注意的是,我只在 Ask LukeW 流程的生成部分使用 Opus 4,该流程使用 AI 模型不仅生成内容,还进行内容的转换、清理、嵌入、检索和排序。因此,在流程的许多其他部分,测试新模型也很重要,但在最终的生成步骤中,Opus 4 胜出。目前……