机器学习和人工智能领域的研究现在几乎是每个行业和公司的一项关键技术,但内容太多,任何人都无法阅读。本专栏 Perceptron(前身为Deep Science )旨在收集一些最相关的最新发现和论文——尤其是在但不限于人工智能方面——并解释它们为何重要。
本周在人工智能领域,一项新的研究揭示了偏见是人工智能系统中的一个常见问题,它可以从给予被招募人员的指令开始,以注释人工智能系统从中学习做出预测的数据。合著者发现,注释者会根据指令中的模式进行识别,这会影响他们提供注释,然后这些注释会在数据中出现过度表现,从而使 AI 系统偏向于这些注释。
如今,许多 AI 系统“学习”从注释器标记的示例中理解图像、视频、文本和音频。标签使系统能够将示例之间的关系(例如,标题“厨房水槽”和厨房水槽照片之间的链接)推断为系统以前从未见过的数据(例如,厨房水槽的照片) ‘不包括在用于“教授”模型的数据中)。
这非常有效。但是注释是一种不完美的方法——注释者会给表格带来偏见,这些偏见可能会渗透到训练有素的系统中。例如,研究表明, 普通注释者更有可能将非裔美国人白话英语 (AAVE) 中的短语标记为有毒,一些美国黑人使用的非正式语法,领先的 AI 毒性检测器在标签上进行了训练,将 AAVE 视为毒性不成比例。
事实证明,注释者的倾向可能不仅仅是训练标签中存在偏见的罪魁祸首。在亚利桑那州立大学和艾伦人工智能研究所的一项预印本研究中,研究人员调查了偏见的来源是否可能在于数据集创建者编写的用作注释者指南的指令中。此类说明通常包括任务的简短描述(例如“标记这些照片中的所有鸟类”)以及几个示例。

图片来源: Parmar 等人。
研究人员查看了 14 个不同的“基准”数据集,这些数据集用于衡量自然语言处理系统或可以对文本进行分类、总结、翻译以及以其他方式分析或操作文本的 AI 系统的性能。在研究提供给处理数据集的注释者的任务指令时,他们发现有证据表明这些指令会影响注释者遵循特定模式,然后将其传播到数据集。例如,Quoref 中超过一半的注释是一个数据集,旨在测试 AI 系统理解两个或多个表达式何时指代同一个人(或事物)的能力,以短语“名字是什么”开头,出现在数据集指令的三分之一中的短语。
这种被研究人员称为“指令偏差”的现象尤其令人不安,因为它表明在有偏差的指令/注释数据上训练的系统可能表现不如最初想象的那么好。事实上,合著者发现指令偏差高估了系统的性能,并且这些系统通常无法泛化超出指令模式。
一线希望是大型系统,如 OpenAI 的 GPT-3,被发现通常对指令偏差不太敏感。但这项研究提醒我们,人工智能系统和人类一样,容易受到来自并不总是显而易见的来源的偏见的影响。棘手的挑战是发现这些来源并减轻下游影响。
在一篇不那么发人深省的论文中,来自瑞士的科学家得出结论,面部识别系统不容易被真实的 AI 编辑面部所欺骗。所谓的“变形攻击”涉及使用人工智能来修改身份证、护照或其他形式的身份证件上的照片,以绕过安全系统。合著者使用 AI(Nvidia 的 StyleGAN 2)创建了“变形”,并针对四种最先进的面部识别系统对其进行了测试。他们声称,尽管它们的外表栩栩如生,但它们并没有造成重大威胁。
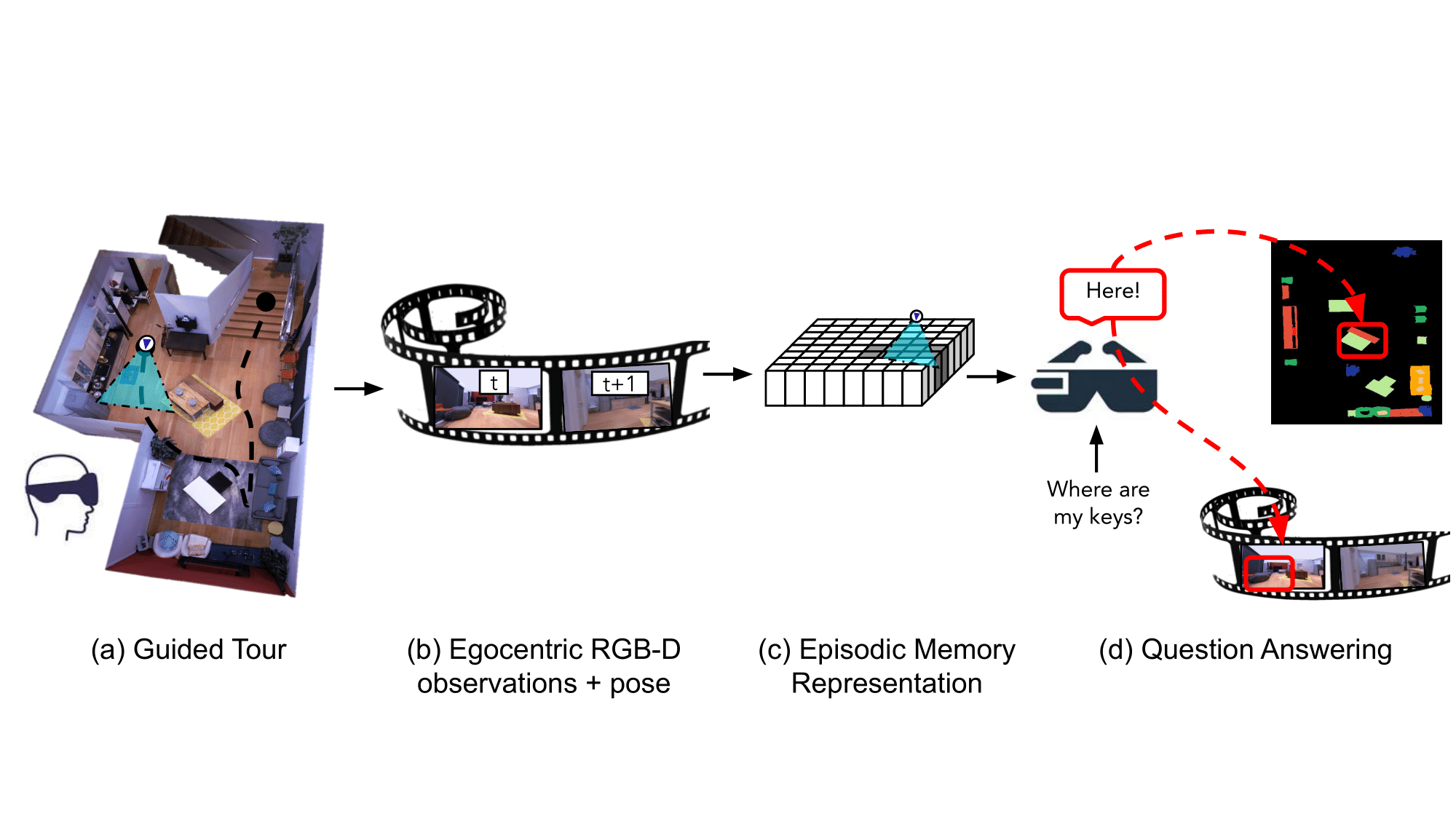
在计算机视觉领域的其他地方,Meta 的研究人员开发了一种人工智能“助手”,可以记住房间的特征,包括物体的位置和背景,以回答问题。在预印本论文中详细介绍,这项工作可能是 Meta 的Project Nazare计划的一部分,该计划旨在开发利用人工智能分析周围环境的增强现实眼镜。
图片来源:元
研究人员的系统旨在用于任何配备摄像头的穿戴式设备,它分析镜头以构建“语义丰富且高效的场景记忆”,“编码有关物体的时空信息”。系统会记住对象在哪里以及何时出现在视频片段中,此外,系统还会将用户可能询问的有关对象的问题的答案放入其内存中。例如,当被问及“你最后一次看到我的钥匙是在哪里?”时,系统可以指出那天早上钥匙在客厅的边桌上。
据报道,Meta 计划在 2024 年发布功能齐全的 AR 眼镜,并于去年 10 月通过推出长期“以自我为中心的感知”人工智能研究项目 Ego4D 传达了其“以自我为中心”的人工智能计划。该公司当时表示,目标是教会人工智能系统——除其他任务外——理解社交线索、AR 设备佩戴者的行为如何影响他们的周围环境,以及手如何与物体互动。
从语言和增强现实到物理现象:人工智能模型在麻省理工学院的波浪研究中非常有用——它们如何破裂以及何时破裂。虽然看起来有点神秘,但事实是波浪模型既需要在水中和附近建造结构,也需要在气候模型中模拟海洋与大气的相互作用。

图片来源:麻省理工学院
通常波浪是由一组方程粗略模拟的,但研究人员在一个装满传感器的 40 英尺水箱中对数百个波浪实例训练了一个机器学习模型。通过观察海浪并根据经验证据做出预测,然后将其与理论模型进行比较,人工智能有助于显示模型的不足之处。
一家初创公司正在从 EPFL 的研究中诞生,Thibault Asselborn 的关于手写分析的博士论文已经变成了一个成熟的教育应用程序。使用他设计的算法,该应用程序(称为 School Rebound)可以识别习惯和纠正措施,只需 30 秒的时间,孩子用触控笔在 iPad 上书写。这些以游戏的形式呈现给孩子,通过加强良好习惯帮助他们写得更清楚。
“我们的科学模型和严谨性很重要,是我们与其他现有应用程序不同的地方,”Asselborn 在新闻稿中说。 “我们收到了老师的来信,他们看到他们的学生取得了长足的进步。有些学生甚至会在课前来练习。”

图片来源:杜克大学
小学的另一项新发现与在常规筛查中发现听力问题有关。一些读者可能还记得,这些筛查通常使用一种称为鼓室计的设备,该设备必须由训练有素的听力学家操作。如果一个人不可用,比如说在一个偏远的学区,有听力问题的孩子可能永远无法及时得到他们需要的帮助。
杜克大学的 Samantha Robler 和 Susan Emmett 决定建造一个基本上可以自行运行的鼓室计,将数据发送到智能手机应用程序,并由人工智能模型解释。任何令人担忧的事情都会被标记出来,孩子可以接受进一步的筛查。它不是专家的替代品,但总比没有好得多,并且可能有助于在没有适当资源的地方更早地发现听力问题。
原文: https://techcrunch.com/2022/05/08/perceptron-ai-bias-can-arise-from-annotation-instructions/